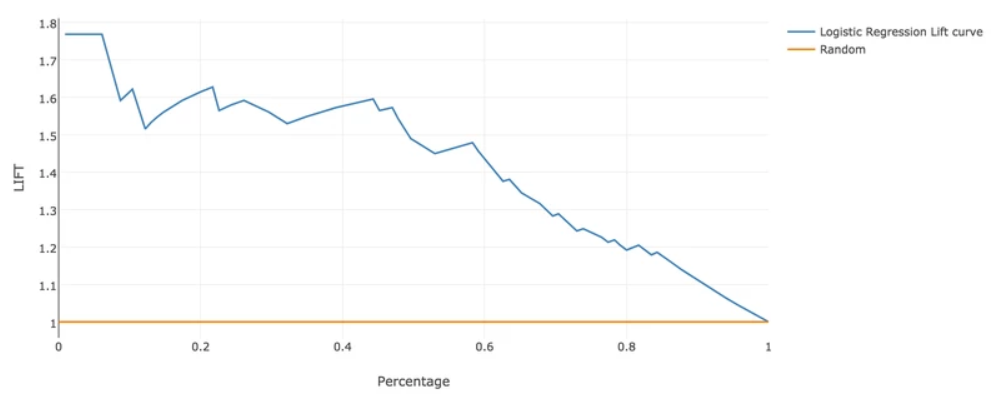
Visualizes the performance of a classification model. It applies in general to classification models (for example, CART, Decision Tree, Logistic Regression, Naive Bayes, Neural Network, and Alpine Forest).
Information at a Glance
| Category
|
Model Validation
|
| Data source type
|
DB
|
| Sends output to other operators
|
No
|
| Data processing tool
|
n/a
|
While a cumulative gains chart shows the total number of events captured by a model over a given number of samples, a lift curve shows the ratio of a model to a random guess. Lift charts show how a model performs compared to random guessing given
x number of samples.
For example, suppose a population has an average response rate of 1%, but a certain model has identified a segment with a response rate of 10%. That segment has a "lift" of 10.0 (10%/1%).
By ranking quantiles of data by lift, you can see which areas have the most lift and thus which the model performs best on. For more information and examples about lift, see
here.
Input
- A data set from the preceding operator.
- Optional - One or more model(s) from the preceding operator(s). The models must be a classification model. The following models are supported.
- CART
- Decision Tree
- Logistic Regression
- Naive Bayes
- Neural Network
- Alpine Forest
Configuration
| Parameter
|
Description
|
| Notes
|
Any notes or helpful information about this operator's parameter settings. When you enter content in the
Notes field, a yellow asterisk is displayed on the operator.
|
| Dependent Column
|
Define the column to use as the class variable.
|
| Value to Predict
|
The value that represents the event to analyze.
Note: The value of this column must match the data as it is stored in the database that matches how it appears in the data explorer. If the user defines a Boolean
Dependent Column with 1s and 0s, the user must use 1 or 0 as the
Value to Predict. If the column uses True and False, the user must use "True" or "False" as the
Value to Predict.
|
| Use Model
|
Specify whether the evaluation uses a model from preceding operator(s) or the data in the prediction columns of the input data set. If
true, at least one model operator must directly precede it. If
false, the prediction columns must be present in the input data set from its preceding operator.
Default value:
true.
|
| Confidence Columns
|
Choose the list of columns in the input data set to compare to the dependent column.
|
Output
- Visual Output
- Lift diagram. Used for model comparison if more than one model is supplied by the preceding operators.
- Data Output
- None. This is a terminal operator.
Copyright © 2021. Cloud Software Group, Inc. All Rights Reserved.