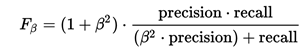Classification Threshold Metrics
Use to output (binary or multi-class) classification performance metrics for different confidence thresholds associated with a unique class that the user specifies.

Information at a Glance
The Classification Threshold Metrics operator partially leverages Spark MLLib Classification Threshold Tuning in the Evaluation Metrics package (Spark version 1.5.1).
For more information about this operator and its available metrics, see Prediction Threshold.
Input
Classification Threshold Tuning must be preceded by either the Classifier operator or the Predictor operator. The outputs from those operators are required for the calculations in this operator.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Dependent Column | Select the column that contains the dependent variable used to train the classification model (can be numeric or categorical). |
| Confidences Column |
Select the column that contains the confidences levels associated with classes from the classification model (binary or multi-class). This column must have the sparse data type, and contains the dictionary (with string keys and double values) of all confidence levels associated with model classes.
Example: {"red":0.52, "green":0.32, "blue":0.26} or {"0":0.52, "1":0.48} It is most likely to be the INFO_model_name column in the output of the Classifier or Predictor operators. |
| Class to Predict |
Enter one of the model classes to predict (quotes are not needed for both numeric or string entries). This class is considered as the positive class in order to compute the classification metrics.
Example: red or 1 Note: If the
Dependent column is numeric and the value entered for
Class to Predict cannot be cast to numeric, an error appears before closing the parameter dialog box.
If the value entered for Class to Predict is not a member of the model classes (classes in Confidences column), an error occurs at runtime. |
| Number of Bins (approx.) | Select the approximate number of confidence threshold bins (default is
20), corresponding to the approximate number of rows in the output.
Points are made of bins of equal number of consecutive points. The size of each bin is equal to floor(total_rows/num_bins), which means the resulting number of bins might not exactly match the value specified. The last bin in each partition might be smaller as a result, meaning there might be an extra sample at partition boundaries. |
| Beta Value for F-measure ( β) | Enter the β value to compute F-score (must be >= 0, default = 1). |
| Write Rows Removed Due to Null Data To File | Rows with at least one null value in either the
Dependent column or
Confidences column are removed from the analysis. This parameter allows you to specify whether rows with null values are written to a file.
The file is written to the same directory as the rest of the output. The filename is suffixed with _baddata.
|
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|