Testing Models for Performance Decay
After models are trained and deployed, differences between the training data and the data to be scored might lead to a degree of deterioration in their predictive performance. This page addresses how to test models to verify that their performance lies within predefined thresholds of acceptability.

Training a Model
For this example, we use the freely available Bank Marketing data set. The data consists of demographic information, client relationship information, and economic conditions information for 41,188 clients of a Portuguese bank who were targets of a marketing campaign to subscribe to a term deposit (a type of financial product) on offer. The goal is to predict whether the client will accept the offer. This is a classification task.
We split the data set into three sets: a training and validation data set that consists of the first 39,000 clients, which represents marketing data from 2007 to 2009 (the dates were verified using the 3M LIBOR column included in the data set). The remaining 2,188 clients were sampled in the year 2010 and are used to test the model for performance decay in operational settings.
Our model training workflow is as follows:
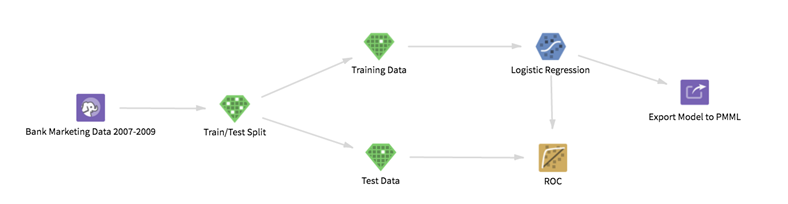
We split the data set that contains marketing data from 2007 to 2009 into a training set and a test set for model validation. We build a logistic regression model on the training data using all the columns in the data set apart from the index and the target variable, and then we validate the performance of the trained logistic regression model on the test data by generating an ROC curve:
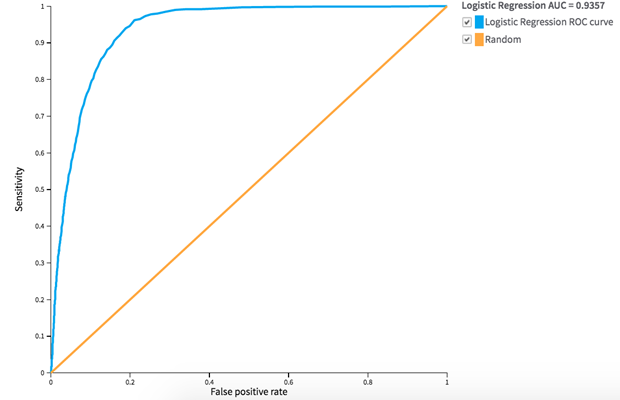
Because the model demonstrates satisfactory performance on the test data, we export the model into the local Team Studio workspace for use in other operational workflows:

Testing the Model in an Operational Workflow
Trained models could undergo performance decay in operational settings if the underlying data set that the model was trained on is substantially different than the data set on which it is tested. This is often the case when models are not trained on a sufficiently large and diverse data set that covers a variety of scenarios. Another possibility might be if the newer data set undergoes a non-trivial change in composition as compared to the older data set. For example, the rate of defaults in consumer lending data sets changed dramatically during the financial crisis; predictive models trained on more benign lending environments failed to anticipate this change appropriately.
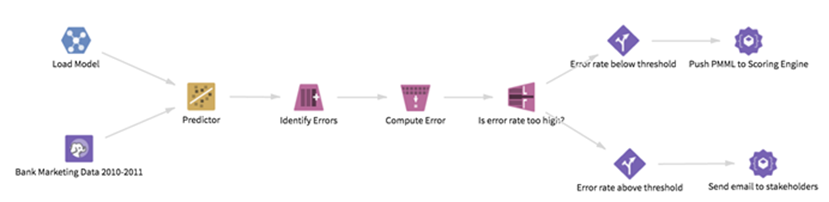
In the following workflow, we create a mechanism to check the performance of a predefined model on recently available bank marketing data. If the model's performance continues to be satisfactory, we push the model to a scoring engine for production usage. If not, we send out an alert email to inform stakeholders of this failure. The overall workflow looks like this:
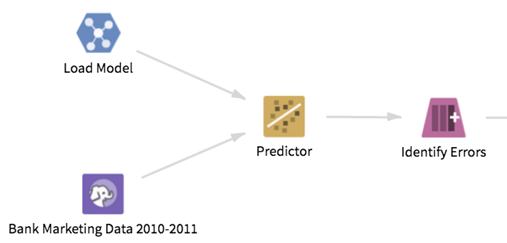
We begin by loading the saved model from the local Team Studio workspace. We run the Predictor operator on the loaded model and the latest data set, and check for row-wise prediction errors by introducing a new error variable:
The error variable compares the actual target value (accepted_offer) against the value predicted by the model (PRED_LOR), and is set to 1 if these values are not identical. We compute the average error rate over the entire data set using an Aggregation operator to count the number of errors. We expect the model to exhibit an error rate of less than 5%, and we use a Row Filter operator to check if the error rate is too high (that is, greater than 0.05). Finally, we use Flow Control operators to determine what action to take depending on the performance of the model on this data set:
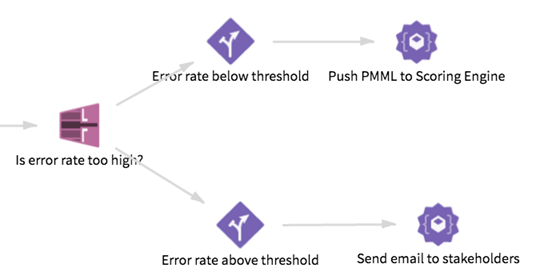
If the error rate falls above the threshold, the first sub-flow below executes, and an email is sent to stakeholders informing them of a potential drop in model performance. On the other hand, if the error rate falls below the threshold, the second sub-flow below executes, and the PMML format of the model is pushed to a scoring engine. We run the Predictor operator on the loaded model and the latest data set, and check for row-wise prediction errors by introducing a new error variable.
Note that each of the final actions - Push PMML to Scoring Engine and Send email to stakeholders - are custom operators built using the Custom Operator SDK in Team Studio, and are not available as part of the core Team Studio offering.