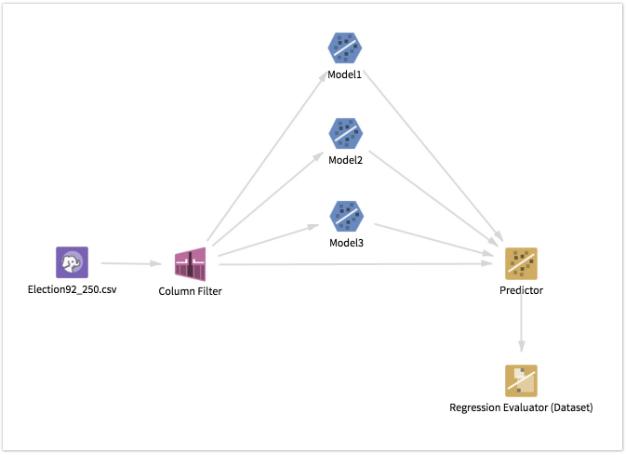
Computed Metrics and Use Case for the Regression Evaluator
For model validation, the Regression Evaluator operator uses the MLlib regression evaluator. You can use it with
| Accuracy | Description | Equation |
|---|---|---|
| Mean Squared Error (MSE) | The sum of the squared difference between actual and predicted columns, divided by the number of observations in the predicted dataset.
A value of 0 indicates that the predicted and actual values are exactly the same for each observation. A very high value indicates that on average, the difference between actual and predicted values is very large in both directions. |
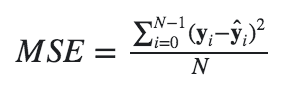
|
| Mean Squared Error (MSE) | The square root of the MSE metric. | 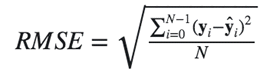
|
| Mean Absolute Error (MAE) | The average of the absolute difference between the predicted and actual columns for each observation. A value of 0 indicates that the predicted and actual values are exactly the same for each observation. A very high value indicates that on average, the difference between actual and predicted values is very large in both directions. | 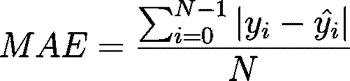
|
| Coefficient of Determination R2 ) | A metric of how well data fit a statistical model. The average of the Squared Error divided by the variance. See
Coefficient of Determinationfor more details.
An R2 of 1 indicates that the regression line perfectly fits the data, while a value of 0 indicates that it doesn't fit the data at all. |

|
| Mean Absolute Percentage Error (MAPE) | A measure of prediction accuracy. It expresses accuracy as a percentage. However, it cannot be used if there are zero values, because there would be a division by zero. If a row contains a zero value, the row is skipped.
See Mean Absolute Percentage Error for more details. |
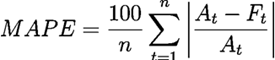
|
See the MLlib information at the Spark site for more information.
The Regression Evaluator operator (for either DB or HD) handles null values by eliminating them from the input calculation. If you want a different behavior, use the Null Value Replacement operator (for either DB or HD) on the initial training data to replace bad or missing values. All of the Team Studio MapReduce operators replace bad data with null values in a format suitable for the Regression Evaluator, so this operation does not fail on output of a MapReduce operator such as a Column Filter.
- Use with Team Studio Predictors
- One likely use case for this operator is as an evaluator for a Linear Regression operator (either DB or HD). It can be used to compare different regressions. To do this, the user should connect each of the model operators and the dataset used to train them to one Team Studio Predictor, then connect the Predictor to this operator. To configure the Regression Evaluator, select the original dependent variable column passed through the Predictor and the columns generated by the Predictor (one for each model). The last few columns passed in through the Predictor are the predictions made for each of the models that it predicted on.