Classification Modeling with Decision Tree
The Decision Tree operator applies a classification modeling algorithm to a set of input data. This operator is most suitable for predicting or describing data sets with binary or limited number of discrete output categories.
Team Studio provides several implementations of Decision Tree. Select the operator that is the best match for your use case.
| Decision Tree implementation and link | Description |
|---|---|
| Decision Tree (HD) | The core Decision Tree offering. It operates on Hadoop datasets. |
| Decision Tree - MADlib | This Decision Tree operator can be used on databases with MADlib 1.8 or below installed. It uses the C4.5 algorithm in MADlib for its calculations. |
| Decision Tree Regression -CART | This Decision Tree operator also runs on databases with MADlib installed. For this operator, we support MADlib 1.8 and above. It will not work on MADlib 1.7.1, for example. You can use the other Decision Tree - MADlib operator if you have an older version of MADlib. This operator runs a decision tree regression using the CART algorithm. |
| Decision Tree Classification - CART | This Decision Tree operator also runs on databases with MADlib installed. Like Decision Tree Regression, we support MADlib 1.8 and above. If you have an older version of MADlib, consider using our other Decision Tree MADlib operator. This operator runs a decision tree classification using the CART algorithm. |
The resulting Decision Tree can be used as a predictive model which maps observations about an item (independent variables) to conclusions about the item's target value (dependent variable).
Decision Trees have the following structural properties:
- The hierarchical classification structure called a tree with each decision point, or node, being a point at which the data is segmented into sub-groups.
- The original top node represents the entire dataset and is referred to as the root node.
- The nodes in the tree represent the various decisions, computations or logic tests made in the classification model.
- The bottom leaves (terminal nodes) represent the classification labels where a final decision or classification is made and applied to all the observations in the leaf.
- The branches represent conjunctions of features that lead to the classification labels.
Decision Tree models are attractive because they show both modelers and business users clearly how to reach a decision. They are structured as a sequence of simple questions and the answers to these questions trace a path down the tree. Therefore, it is easy for a person to manually apply the classification logic path on new data.
The following illustration depicts a simplified decision tree for determining whether to play tennis based on the weather. This shows how visually intuitive the Decision Tree Operator output is in terms of understanding the steps involved in the classification logic.
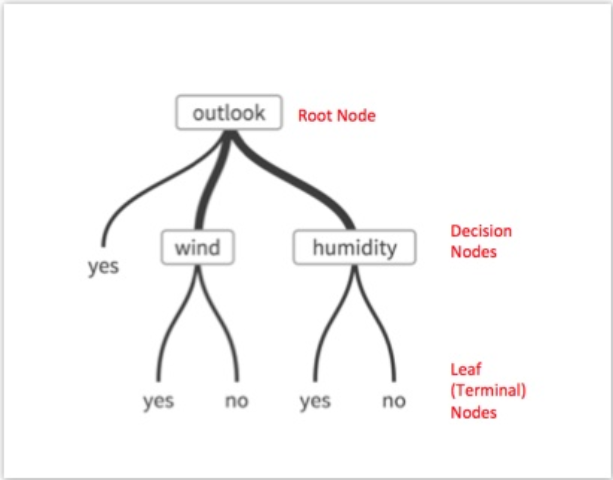
For a description of the algorithm, see the help for the Decision Tree operator you are using.
After a Decision Tree has been trained within Team Studio, it can be used in a variety of ways.
- By making inferences that help the user understand the "big picture" of the model. One of the great advantages of decision trees is that they are easy to interpret even by non-technical people. For example, if a decision tree models product sales, a quick glance might tell you that men in the South buy more of your product than women in the North. Another example might be a model of health risks for insurance policies, and a quick glance at the decision tree might illustrate that smoking and age are important predictors of health.
- By identifying target groups. For example, if a business is looking for the best potential customers for a product, the user could identify the terminal nodes in the tree that have the highest percentage of sales, and then focus the business' sales efforts on the individuals described by those nodes.
- By predicting the target value for specific cases where only the predictor variable values are known. This is known as "scoring." For example, when predicting the outcome of an election, a modeler may look at census results to predict who will win.
Optionally, you can use one of the alternative models to Decision Tree.
- Decision Tree and CART Operator General Principles
Decision trees are rule-based classifiers that consist of a hierarchy of decision points (the nodes of the tree). - Decision Tree Output Troubleshooting
When you analyze the results of a Decision Tree Model, keep in mind the most important assessment factors. - Decision Tree Use Case
This use case model demonstrates using a decision tree model to assess the characteristics of the client that leads to the purchase of a new product targeted in a direct marketing campaign.