Permissions
Permissions dictate the access each user has to data and actions.
- Overview
- Important considerations about permissions
- Actions and user services granting high privileges
- API access without permission checks
- Using permission for hiding information in the UI
- Limitations of the permission checks in Query API
- Scripted permission rules on records and table history
- Using hidden fields in custom display labels
- Linked field permission check
- Table action permission related limitations
- Permission cache life cycle
- Permissions on a dataset with fatal errors
- Defining confidentiality
- Defining user-defined rules
- Defining dynamic rules
- Resolving permissions on data
- Resolving permissions on services
- Resolving permissions on actions
Overview
Permissions are related to whether actions are authorized or not. They are also related to access rights, that is, whether an entity is hidden, read, or read-write. The main entities controlled by permissions are:
Dataspace
Dataset
Table
Group
Field
Users, roles and profiles
The definition and resolution of permissions make extensive use of the notion of profiles, which is the generic term applied to users or roles.
Each user can participate in several roles, and a role can be shared by several users.
These relationships are defined in the user and roles directory. See Users and roles directory.
Special definitions:
A built-in administrator is a member of the built-in role 'ADMINISTRATOR'.
An owner of a dataset is a member of the owner attribute specified in the information of a root dataset. In this case, the built-in role 'OWNER' is activated when permissions are resolved in the context of the dataset.
An owner of a dataspace is a member of the owner attribute specified for a dataspace. In this case, the built-in role 'OWNER' is activated when permissions are resolved in the context of the dataspace.
Permission rules
A permission rule defines the authorization granted to a profile for a particular entity.
User-defined permission rules are created through the user interface. See the section Defining user-defined rules.
Dynamic permission rules can be either programmatic rules created by developers, or scripted rules created by administrators. See the section Defining dynamic rules.
Resolution of permissions
Permissions are always resolved in the context of an authenticated user session, thus permissions are mainly based on the user profiles.
In general, resolution of permissions is performed restrictively between a given level and its parent level. Thus, at any given level, a user cannot have a higher permission than the one resolved at a parent level.
Dynamic permissions are always considered to be restrictive.
Note
In the Java API, the class SessionPermissions provides access to the resolved permissions.
See also
Owner and administrator special permissions
On a dataset
A built-in administrator or owner of a dataset can perform the following actions:
Manage its permissions
Change its owner, if the dataset is a root dataset
Change its general information (localized labels and descriptions)
Attention
While the definition of permissions can restrict a built-in administrator or dataset owner's right to view data or perform certain actions, it remains possible for them to modify their own access, as they will always have access to permissions management.
On a dataspace
To be a super owner of a dataspace, a user must either:
Own the dataspace and be allowed to manage its permissions, or
Own a dataspace that is an ancestor of the current dataspace and be allowed to manage the permissions of that ancestor dataspace.
A built-in administrator or super owner of a dataspace can perform the following actions:
Manage its permissions of dataspace.
Change its owner
Lock it or unlock it
Change its general information (localized labels and descriptions)
Furthermore, in a workflow, when using a "Create a dataspace" or "Create a snapshot" built-in script task, resolved permissions are computed using the owner defined in the script task's configuration, rather than the current session. This is because, in these cases, the current session is associated with a system user.
Attention
While the definition of permissions can restrict a built-in administrator or dataspace owner's right to view data or perform certain actions, it remains possible for them to modify their own access, as they will always have access to permissions management.
Impact of merge on permissions
When a dataspace is merged, the permissions of the child dataset are merged with those of the parent dataspace if and only if the user specifies to do so during the merge process. The permissions of its parent dataspace are never impacted.
If some elements are hidden for the profile attempting to perform a merge, it will not be possible to proceed as the impacts of the merge on data will not be fully visible.
Important considerations about permissions
In this section are listed some very important information that must be kept in mind while working with permissions.
Actions and user services granting high privileges
The following actions and their related user services must only be allowed to trusted administrators:
'Create dataspace' (gives the 'owner' role, which grants the right to define the dataspace permissions)
'Create dataset' (gives the 'owner' role, which grants the right to define the dataset permissions)
'Import archive' (allows writing the archive content regardless of any permission)
Note
See the Owner and administrator special permissions section for more information about the privileges granted to these profiles.
API access without permission checks
Developers and administrators must be aware that some parts of the API can run without any permission check. In general if the code run in a context with a Session provided, it means that permissions will be checked. Here are some specific cases where permissions are not checked:
When a Java procedure disables all permission checks by using
ProcedureContext.setAllPrivileges.When accessing EBX® data by directly querying your database, in the case a table enables the replication mode, or the historization. This is because EBX® permissions are not "translated" in the underlying database. As a consequence, either the database access must be globally restricted or proper permissions must be defined in it.
Using permission for hiding information in the UI
Using the permissions only to hide in the UI some non sensitive information is unadvised, especially if this information is likely to be used for filtering / joining / sorting in some queries. In such cases, UI-only hiding methods should be used instead. For instance by setting the field as hidden for default views in the data model property and/or by creating views for the concerned users.
When the above suggestions can not be applied and permissions have to be used to hide non sensitive information, the nodes must be set as non confidential in the model. For more information, see Defining confidentiality.
Limitations of the permission checks in Query API
The permission check performed when specifying a session in a Query or Request will throw a QueryPermissionException if any confidential field used in the query is hidden for the current user. All fields are considered confidential except:
Fields belonging to primary keys;
Fields explicitly defined as non-confidential. For more information , see Defining confidentiality;
Attention
Confidential nodes with a record-dependent AccessRule are only partially confidential. Indeed, the method AccessRule.getPermission is only called with a dataset as the aDataSetOrRecord parameter while performing the permission check, never with a record. As a consequence, the record-dependent logic of the rule will not apply during this check.
Scripted permission rules on records and table history
You can use scripted permission rules to filter table records and table history. By default, table history access is disabled for all users. This behavior helps enforce security. However, you can create a list of profiles authorized to access table history by editing the permission rule and adding the desired profiles to the Profiles authorized to access history list.
Using hidden fields in custom display labels
Resolution of custom display labels for tables ('defaultLabel' property) and relationships ('display' property) takes into account permission. As soon as an hidden field is detected in the label, the primary key will be displayed instead.
Note
This is not the case when using API like TableRefDisplay or Adaptation.getLabelOrName. Since the provided contexts do not contain the current session, no permission check can be performed. As a consequence, developer should make sure that no confidential data is exposed when using these APIs.
Note
Also note that quick search will ignore nodes with hidden fields in custom display label in the context of history view and/or in a child dataset.
Because of this behavior it is highly discouraged to use labels for filtering in a query. When labels with hidden fields are used, it will be replaced by the pk value and the filter will become inconsistent.
Linked field permission check
When a linked field access permission is computed, the result is the minimum between the permission applying to the node in the main table and the node in the target table. Practically it means that if a field is hidden in a table, all linked fields pointing on it in other tables will also be hidden.
Table action permission related limitations
When performing actions on a table (create, delete, overwrite or occult) in a procedure, the current user session access right on the table node is ignored during the permission resolution. Should this check be performed, the client code must explicitly call SessionPermissions.getNodeAccessPermission beforehand in the procedure.
Permission cache life cycle
To optimize the resolution of permissions for both data and user services, a dedicated cache is implemented at the session level. All permissions are cached including dynamic rules, it means that a rule result should not change for the duration of the cache which is explained below.
The session cache life cycle depends on the context, as described hereafter:
In the UI, the cache is cleared for every non-ajax event (i.e on page display, pop-up opening, etc.).
In programmatic procedures, the cache lasts until the end of the procedure, unless explicitly cleared (see below).
Attention
When modifying permissions in a procedure context (by importing an EBX® archive or merging a dataspace programmatically), the session cache must be cleared via a call to
Session.clearCache. Otherwise, these modifications will not be reflected until the end of the procedure.
Permissions on a dataset with fatal errors
When a dataset has fatal errors, only owners and administrators have access and only the following actions are available:
View the validation report
View the information page
Delete the dataset
Defining confidentiality
The confidentiality of a node defines whether or not it can be used in a Query or a Request when hidden for a specific user. By default, all nodes are confidential.
Defining confidentiality on a node has the following impacts on the relationships and views that use it:
A relationship (association or table reference) is hidden if at least one of its defining nodes is confidential and hidden.
A relationship is hidden if at least one of the nodes used in its additional XPath filter is confidential and hidden.
A view is hidden if at least one of the nodes that is used in its filter criteria or in its sort criteria is confidential and hidden.
For details about relationship defining nodes and relationship additional XPath filters see Foreign keys and Associations.
Attention
It is recommended to be very vigilant before setting a field as non confidential because although hidden, a malicious user could then "guess" the value by filtering or sorting using this node. It can not always be done, but it is generally a better option to use views to handle these kinds of use cases, as recommended in Using permission for hiding information in the UI.
The confidentiality of nodes can be configured in the DMA. For more details, see Node confidentiality.
Defining user-defined rules
Each level has a similar schema, which allows defining permission rules for profiles.
Defining dataspace user-defined rules
For a given dataspace, the allowable permissions for each profile are as follows:
Dataspace access | Authorization |
|---|---|
Write |
|
Read-only |
|
Hidden |
|
Restriction policy | Indicates whether this dataspace profile-permission association should have priority over other permissions rules. |
Create a child dataspace | Indicates whether the profile can create child dataspaces from the current dataspace. |
Create a child snapshot | Indicates whether the profile can create snapshots of the current dataspace. |
Initiate merge | Indicates whether the profile can merge the current dataspace with its parent dataspace. |
Export archive | Indicates whether the profile can export the current dataspace as an archive. |
Import archive | Indicates whether the profile can import an archive into the current dataspace. |
Close a dataspace | Indicates whether the profile can close the current dataspace. |
Close a snapshot | Indicates whether the profile can close a snapshot of the current dataspace. |
Rights on services | Indicates if a profile has the right to execute services on the dataspace. By default, all dataspace services are allowed. A built-in administrator or super owner of the current dataspace or a given user who is allowed to modify permissions on the current dataspace can modify these permissions to restrict dataspace services for certain profiles. |
Permissions of child dataspace when created | When a user creates a child dataspace, the permissions of this new dataspace are automatically assigned to the profile's owner, based on the permissions defined under 'Permissions of child dataspace when created' in the parent dataspace. If multiple permissions are defined for the owner through different roles, the owner's profile behaves like any other profile and permissions are resolved as usual. |
Defining dataset user-defined rules
For a given dataset, the allowable permissions for each profile are as follows:
Actions on datasets
Restriction policy | Indicates whether this dataset profile-permission association should have priority over other permissions rules. |
Create a child dataset | Indicates whether the profile has the right to create a child dataset of the current dataset. |
Duplicate dataset | Indicates whether the profile has the right to duplicate the current dataset. |
Change the dataset parent | Indicates whether the profile has the right to change the parent dataset of a given child dataset. |
Actions on tables
The action rights on default tables are defined at the dataset level. It is then possible to override these default rights for one or more tables. The allowable permissions for each profile are as follows:
Create a new record | Indicates whether the profile has the right to create records in the table. |
Overwrite inherited record | Indicates whether the profile has the right to overwrite inherited records in the table. |
Occult inherited record | Indicates whether the profile has the right to occult inherited records in the table. |
Delete a record | Indicates whether the profile has the right to delete records in the table. |
Access rights on node values
Permissions defined on specific terminal nodes override their default access rights.
Read-write | Can view and modify node values. |
Read | Can view nodes, but cannot modify their values. |
Hidden | Cannot view nodes. |
Permissions on services
A built-in administrator or an owner of the current dataspace can modify the service default permission to either restrict or grant access to certain profiles.
Enabled | Grants service access to the current profile. |
Disabled | Forbids service access to the current profile. It will not be displayed in menus, nor will it be launchable via web components. |
Default | Sets the service permission to enabled or disabled, according to the default permission defined upon service declaration. See |
Using the Dataset Permissions configuration service
User-defined access rules at the dataset level are defined using the Permissions service available from the dataset's Actions menu. From this service, administrators can review and configure user access to data, actions, and services inside this dataset.
Permissions service UI overview
The service is presented as a grid in which:
Each column represents a rule for one profile in the dataset. As shown in the example screenshot below, the profiles are: SALES, John Doe (user), [all profiles], and [owner] admin admin. See Managing profiles for more information.
Each line represents a node, an action, or a service on which a rule applies. See Managing permissions for more information.
Each modifiable cell represents a permission level to access a node, an action, or a service for a given profile.
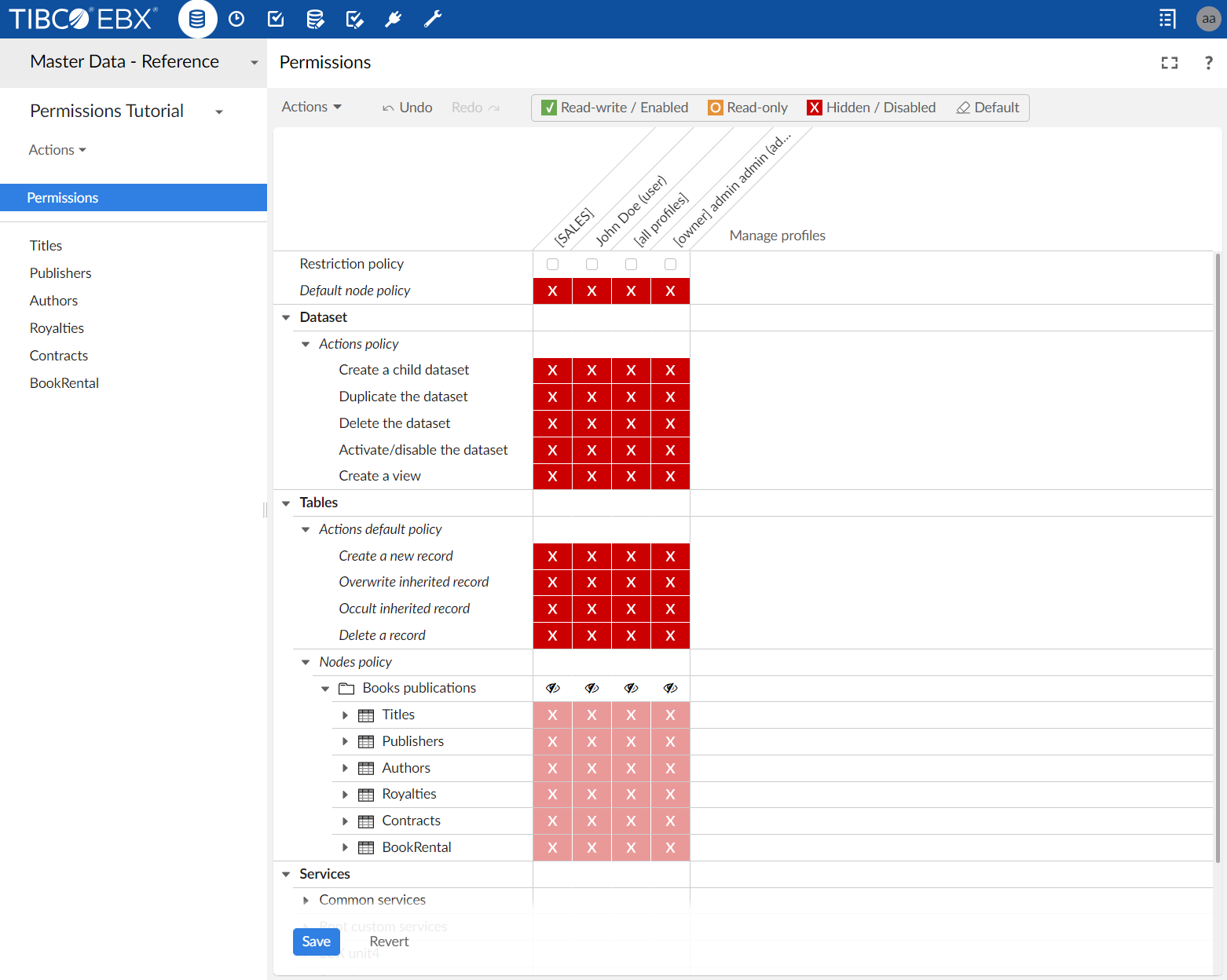
Managing profiles
Profile management tasks include:
Adding a user-defined access rule
To add a rule for a profile:
Click the Manage profiles button at the top of the grid.
In the popup menu, select or hover over a profile from the Available profiles tab.
Click the Add button.
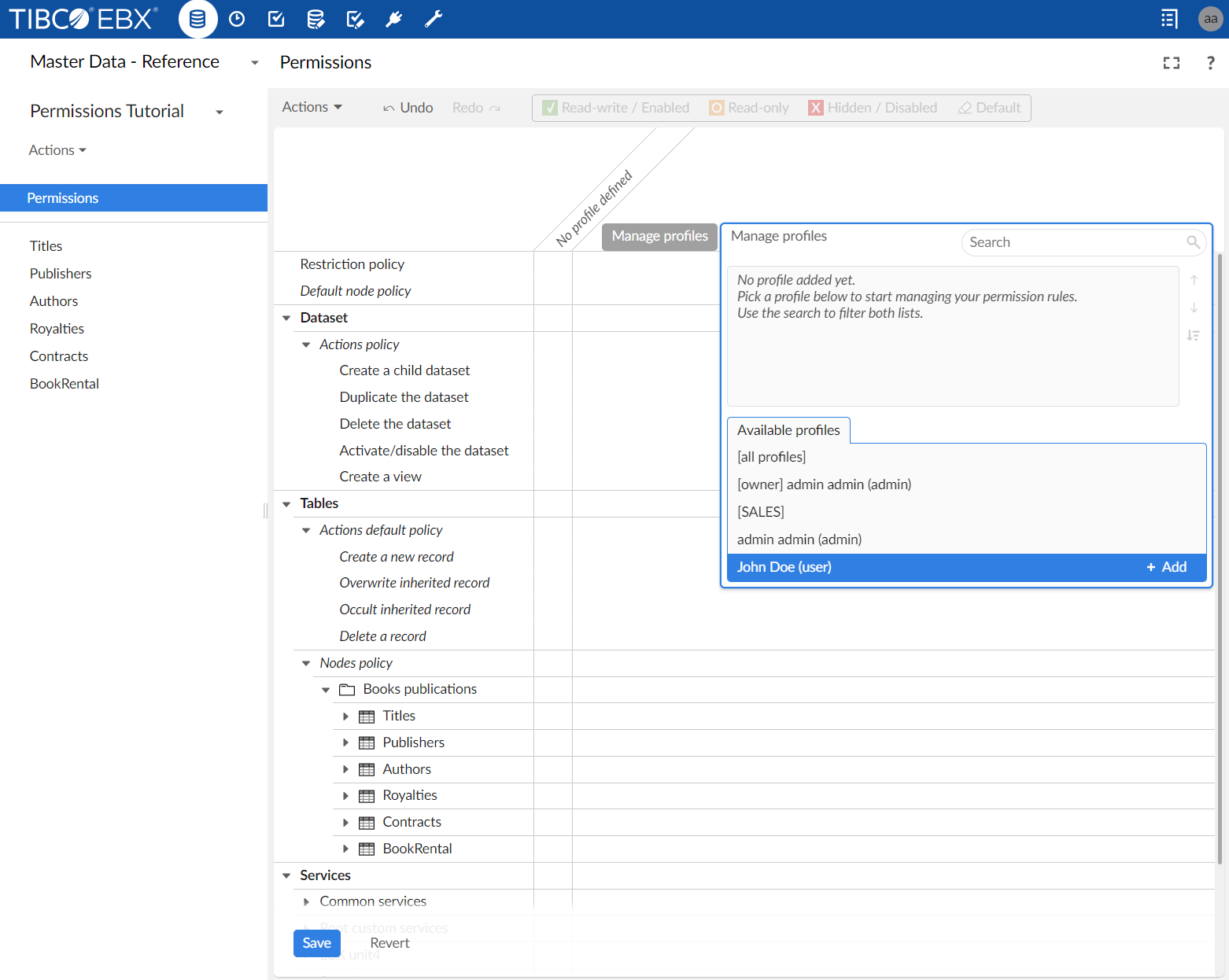
Duplicating a profile configuration into another profile
To duplicate an existing profile's configuration into another profile:
Click the Manage profiles at the top of the grid.
In the popup menu, select or hover over the source profile in the Manage profiles window.
Click the Duplicate button that displays to the right of the source profile's name.
Select the destination profile under the Available profiles.
Deleting a profile configuration
To delete a profile configuration:
Click the Manage profiles at the top of the grid.
In the popup menu, select or hover over a profile in the list.
Click the Delete button that display to the right of the source profile's name.
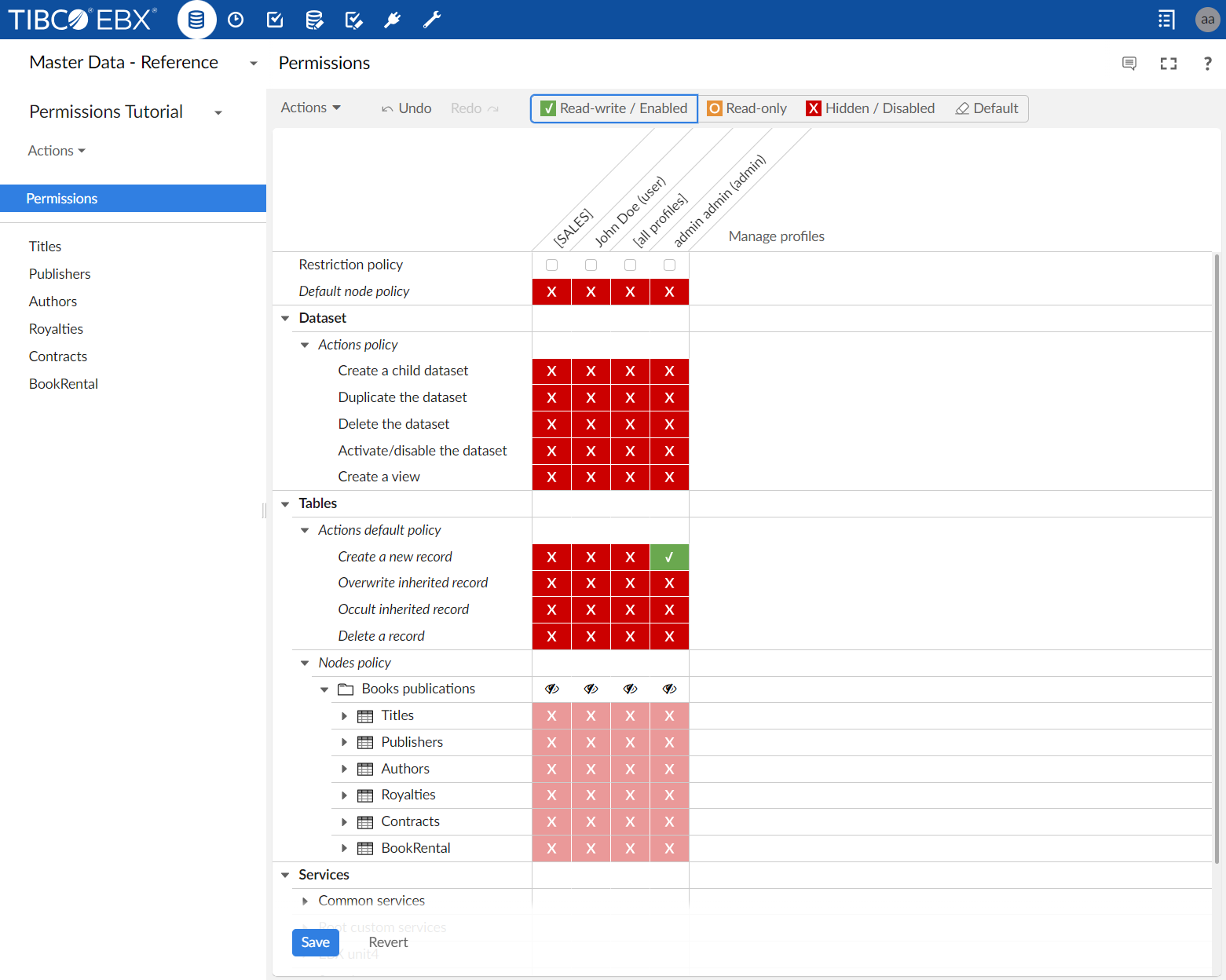
Managing permissions
There are 2 ways to assign permissions on nodes, actions, and services. You can:
Select one or more cells, then apply a permission using the toolbar or a shortcut.
Select a permission using the toolbar or a shortcut when no cell is selected, then apply this permission to one or more cells. When using this method an icon displays next to the mouse pointer and changes depending on the context.
Note
In the permissions toolbar, the Read-Write / Enabled and Hidden / Disabled value changes depending on whether the selection is a node, or an action/service. The actual value is Read-Write and Hidden for a node and Enabled and Disabled for an action/service.
In the screenshot below, the permission cell corresponding to the Create a new record service and to the user John Doe is set to Enabled:
Defining dynamic rules
Dynamic rules give the possibility to define more precisely the conditions for accessing data or user services depending on the context.
There are different types of programmatic rules:
the
AccessRule, described in the section below Defining access rules on data.the scripted record permission rule, described in the section below Defining scripted permission rules on data.
the ServiceActivationRule, described in the section below Defining activation rules on service.
the
ServicePermissionRule, described in the section below Defining permission rules on service.
Defining scripted permission rules on data
scripted permission rules are rules that dynamically define, depending on the context, the read/write rights on the records of a table.
To define such a rule, a record permission script must be created in the DMA. A script editor is available on the table node definition, in the "Extensions" tab.
Defining access rules on data
AccessRules are rules that programmatically define, depending on the context, the read/write rights on a data model node or on the records of a table.
The definition of an AccessRule is performed as follows:
Creation of a rule in the form of a Java class implementing the
AccessRuleorAccessRuleForCreateinterface.Assignment of this rule to concerned nodes in the schema extension:
SchemaExtensions.According to the rule target (model node(s) or records) and type (
AccessRuleorAccessRuleForCreate), several methods such asSchemaExtensionsContext.setAccessRuleOnOccurrenceorSchemaExtensionsContext.setAccessRuleForCreateOnNodecan be used.The rule thus assigned is said to be "local" and is only executed when the target entity is requested. See Resolving permissions on data for more information.
Attention
Only one
AccessRulecan be defined for each node, dataspace or record. Only oneAccessRuleForCreatecan be defined for each table child node. The definition of a new programmatic rule of one type will lead to the replacement of the existing one.
Defining activation rules on service
The ServiceActivationRules allow to specify if a service is activated or not for a given dataspace or dataset. A service that has been deactivated through this rule is never available in the entity for which it is deactivated, regardless of the current profile, for execution or display, even in permission screens.
The definition of a ServiceActivationRule is carried out as follows:
Creation of a rule in the form of a Java class implementing the
ServiceActivationRuleForDataspaceinterface orServiceActivationRuleForDataset, depending on the service type.Assignment of this rule to the impacted services at their declaration level, depending on the service type, via the
ActivationContextOnDataspace.setActivationRuleorActivationContextWithDatasetSet.setActivationRulemethods.The resulting assigned rule will be evaluated during the service activation evaluation. See Resolving permissions on services for more information.
Defining permission rules on service
The ServicePermissionRules are advanced rules allowing to dynamically define the display and execution conditions of a service depending on the context (current session, selected entity, etc.). The service should be activated for the current context beforehand for this type of rule to be triggered.
The definition of a ServicePermissionRule is carried out as follows:
Creation of a rule in the form of a Java class implementing the
ServicePermissionRuleinterface.Assignment of this rule to the impacted services:
Either, for new services, at their declaration level via the
ActivationContext.setPermissionRulemethod.The rule thus assigned is said to be "global" and is only executed when the service is activated for the current context. See Resolving permissions on services for more information.
Or, for existing services, in the schema extension via the
SchemaExtensionsContext.setServicePermissionRuleOnNodeandSchemaExtensionsContext.setServicePermissionRuleOnNodeAndAllDescendantsmethods. It is thus possible to assign a rule to any service, including standard services provided by EBX®, on one or more data model nodes: a table node, an association node, etc.The rule thus assigned is said to be "local" and is only executed in the extended schema context and when the node corresponds to the one specified. See Resolving permissions on services for more information.
Attention
Only one
ServicePermissionRulecan be defined for each model node. Thus, the definition of a new programmatic rule will replace the existing one.
Resolving permissions on data
Resolving user-defined rules
Access rights defined using the user interface are resolved on four levels: dataspace, dataset, record (if applicable) and node.
If a profile is associated with restrictive access rights at a given level, the minimum of all restrictive rights defined at that level is resolved. If no restrictions are defined at that level, the maximum of all access rights defined at that level is resolved.
When a restrictive permission is defined for a profile, it takes precedence over the other permissions potentially granted by the user's other roles. Generally, for all user-defined permission rules that match the current user session:
If some rules with restrictions are defined, the minimum permissions of these restricted rules are applied.
If no rules having restrictions are defined, the maximum permissions of all matching rules are applied.
Examples:
Given two profiles P1 and P2 concerning the same user, the following table lists the possibilities when resolving that user's permission to a service.
| P1 authorization | P2 authorization | Permission resolution |
|---|---|---|
| Enabled | Enabled | Enabled. Restrictions do not make any difference. |
| Disabled | Disabled | Disabled. Restrictions do not make any difference. |
| Enabled | Disabled | Enabled, unless P2's authorization is a restriction. |
| Disabled | Enabled | Enabled, unless P1's authorization is a restriction. |
The same restriction policy is applied for data access rights resolution.
In another example, a dataspace can be hidden from all users by defining a restrictive association between the built-in profile "Profile.EVERYONE" and the access right "hidden".
At any given level, the most restrictive access rights between those resolved at this level and higher levels are applied. For instance, if a user's dataset access permissions resolve to read-write access, but the container dataspace only allows read access, the user will only have read-only access to this dataset.
Note
The dataset inheritance mechanism applies to both values and access rights. That is, access rights defined on a dataset will be applied to its child datasets. It is possible to override these rights in the child dataset.
Access rights resolution example
In this example, there are three users who belong to the following defined roles and profiles:
User | Profile |
|---|---|
User 1 |
|
User 2 |
|
User 3 |
|
The access rights of the profiles on a given element are as follows:
Profile | Access rights | Restriction policy |
|---|---|---|
user1 | Hidden | Yes |
user3 | Read | No |
Role A | Read/Write | No |
Role B | Read | Yes |
Role C | Hidden | No |
After resolution based on the role and profile access rights above, the rights that are applied to each user are as follows:
User | Resolved access rights |
|---|---|
User 1 | Hidden |
User 2 | Read |
User 3 | Read/Write |
Resolving dataspace and snapshot access rights
At dataspace level, access rights are resolved as follows:
If a user has several rights defined through multiple profiles:
If the rights include restrictions, the minimum of the restrictive profile-rights associations is applied.
Otherwise, the maximum of the profile-rights associations is applied.
If the user has no rights defined:
If the user is a built-in administrator or owner of the dataspace, read-write access is given for this dataspace.
Otherwise, the dataspace will be hidden.
Resolving dataset access rights
At the dataset level, the same principle applies as at the dataspace level. After resolving the access rights at the dataset level alone, the final access rights are determined by taking the minimum rights between the resolved dataspace rights and the resolved dataset rights. For example, if a dataspace is resolved to be read-only for a user and one of its datasets is resolved to be read-write, the user will only have read-only access to that dataset.
Resolving node access rights
At the node level, the same principle applies as at the dataspace and dataset levels. After resolving the access rights at the node level alone, the final access rights are determined by taking the minimum rights between the resolved dataset rights and the resolved node rights.
Specific access rights can be defined at the node level. If no specific access right is defined, the default access right is used for the resolution process.
Note
The resolution procedure is slightly different for table and table child nodes.
Special case for table and table child nodes
This describes the resolution process used for a given table node or table record N.
For each user-defined permission rule that matches one of the user's profiles, the access rights for N are either:
The locally defined access rights for N;
Inherited from the access rights defined on the table node;
Inherited from the default access rights for dataset values.
All matching user-defined permission rules are used to resolve the access rights for N. Resolution is done according to the restriction policy.
The final resolved access rights will be the minimum between the dataspace, dataset and the resolved access right for N.
Resolving dynamic rules
There are three levels of resolution for dynamic access right rules: dataset, record and node. Since only one programmatic access rule can be set for a given level, the last rule set is the one used by the resolution procedure. However, a scripted rule can be specified on top of a programmatic rule at the table level.
Rule resolution on dataset
For a dataset, the last rule set is considered as the resolved rule
Rule resolution on record
For a record, the resolved rule is the minimum between the resolved rule set on the dataset and the rule set on this record.
See SchemaExtensionsContext.setAccessRuleOnOccurrence for more details.
Rule resolution on node
For a node that is a child node of a record, the resolved rule is the minimum between the resolved rule on the record and the rule set on this node.
For a child node of a dataset, the resolved rule is the minimum between the resolved rule set on the dataset and the rule set on this node.
See SchemaExtensionsContext.setAccessRuleOnNode for more details.
Display policy for foreign key drop-down menus
If a record is hidden due to access rules, it will not appear in foreign key drop-down menus.
Attention
The resolved access rights on a dataset or dataset node is the minimum between the resolved access rights defined in the user interface and the resolved dynamic rules, if any.
Resolving permissions on services
User services give the possibility to execute specific and advanced features from the user interface. Depending on their definition, these services can be called from a menu, as an action in a workflow, as a perspective item, or can be executed directly from a URL as a Web component.
See also
The permissions of a service are resolved as the service is called from the user interface, namely:
During the execution, just before the service is displayed.
If the permission resolved in the user context is not
enabled, a restriction message is displayed in place of the service.During the display of menus if the service is defined as displayable in menus.
If the permission resolved in the context for the user is not
enabled, the service will not be displayed in the menu.
Thus, upon every request the resolution of permissions for a service is carried out as follows, in the following order and as long as conditions are respected:
The service activation has to correspond to the current context. This activation considers:
the selected entity type (dataset, table, record, etc.);
static activation rules defined within the
UserServiceDeclaration.defineActivationmethod;the potential dynamic activation rule (ServiceActivationRule) also defined within the
UserServiceDeclaration.defineActivationmethod.
When the service is activated for the current context, permissions for the user session will be evaluated:
If permissions have been defined via the user interface for the current user (or for their roles), their resolution must return
enabled.For more information, please refer to the Resolving user-defined rules section.
If a global permission rule is defined for the service, it must return
enabledfor the context provided (seeServicePermissionRuleContext).If a local permission rule is defined for the selected node, it must return
enabledfor the context provided (seeServicePermissionRuleContext).
Resolving user-defined rules
Example
In this example, there are two users belonging to different roles and profiles:
User | Profiles |
|---|---|
User 1 |
|
User 2 |
|
The permissions associated with the roles and profiles defined on the dataset level are as follows:
Profile | Built-in service create ( | Built-in service duplicate ( | Built-in service compare ( | Custom service 1 ( | Custom service 2 ( | Restriction policy |
|---|---|---|---|---|---|---|
user1 | Enabled | Disabled | Enabled | Disabled | Enabled | No |
Role A | Enabled | Enabled | Disabled | Enabled | Disabled | Yes |
Role B | Enabled | Disabled | Enabled | Enabled | Disabled | Yes |
Role C | Enabled | Enabled | Disabled | Disabled | Disabled | No |
Role D | Enabled | Disabled | Disabled | Enabled | Disabled | No |
The services available to each user after permission resolution are as follows:
Users | Available services |
|---|---|
User 1 | Built-in service create ( |
Custom service 1 ( | |
User 2 | Built-in service create ( |
Built-in service duplicate ( | |
Custom service 1 ( |
See also
Resolving permissions on actions
Actions are low-level operations for EBX® object manipulation on which it is possible to define execution rights for a profile. Unlike permissions on user services, which only impact the user interface, these rights are also applicable when an operation is carried out programmatically (i.e. via a Procedure) or indirectly (for example during data import, actions on the table (create, override, occult and delete) are evaluated).
Here is the list of actions on which rights can be defined:
Action object | Available actions |
|---|---|
Dataspace | Create a child dataspace |
| Create a snapshot | |
| Launch a merge | |
| Export an archive | |
| Import an archive | |
| Close the dataspace | |
| Close the snapshot | |
| Create a dataset | |
Dataset | Duplicate the dataset |
| Delete the dataset | |
| Activate/deactivate the dataset | |
| Create a view | |
Table | Create a new record |
| Override records | |
| Occult records | |
| Delete records |
For the resolution of permissions on actions, only the permissions defined via the user interface for the current user (or their roles) will be taken into account, the restriction policy being applied as for any other permission defined via the user interface.
For more information, please refer to the Resolving user-defined rules section.
Resolving user-defined rules
Example
In this example, we have two users belonging to different roles and profiles:
User | Profiles |
|---|---|
User 1 |
|
User 2 |
|
Rights associated with roles and profiles on the actions of a given table are as follows:
Profile | Create a record | Override a record | Occult a record | Delete a record | Restriction policy |
|---|---|---|---|---|---|
user1 | No | Yes | No | Yes | No |
Role A | Yes | No | Yes | No | Yes |
Role B | No | Yes | Yes | No | Yes |
Role C | Yes | No | No | No | No |
Role D | No | No | Yes | No | No |
The actions available to each user after resolving the rights are as follows:
Users | Available actions |
|---|---|
User 1 | Occult a record |
User 2 | Create a record |
Occult a record |