Workflow Variables
It is possible to override the default workflow parameters using workflow variables.

Default Workflow Variables
Every workflow contains default variables, and each variable begins with the @ symbol:
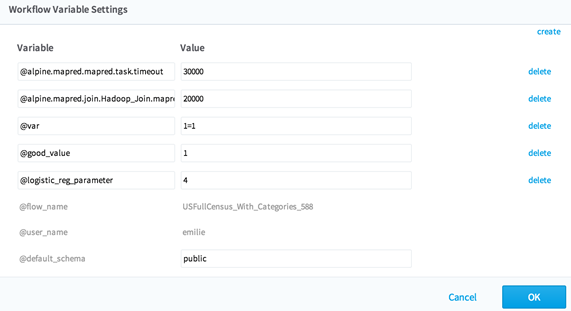
- @default_schema: used as the default schema for database output
- @default_tempdir: used as the default directory for intermediate Hadoop files
- @default_prefix: used as the default prefix for output tables and output files
- @default_delimiter: used as the default data delimiter for CSV and Hadoop files.
Spark Workflow Variables
We do not support setting Spark variables on a workflow-wide level. It is a Spark best practice to optimize the Spark parameters per job or operator that you want to run. To make this process easier, we created Spark Autotuning to help you choose the most performant values for your Spark job settings. See also Spark Optimization For Data Scientists for more information.- Defining New Workflow Variables
In addition to the default variables that every workflow contains, you can also create new workflow variables. - Overriding Hadoop Data Source Parameters Using Workflow Variables
It is possible to override the default Hadoop data source parameters using the workflow variable settings. - Team Studio Operator Job Names
The following is a list of Team Studio job names that can be referenced for overriding specific Hadoop MapReduce data source parameters only for particular operator tasks.
Related concepts
Related tasks
Related reference
Copyright © 2021. Cloud Software Group, Inc. All Rights Reserved.