Regression Evaluator (HD)
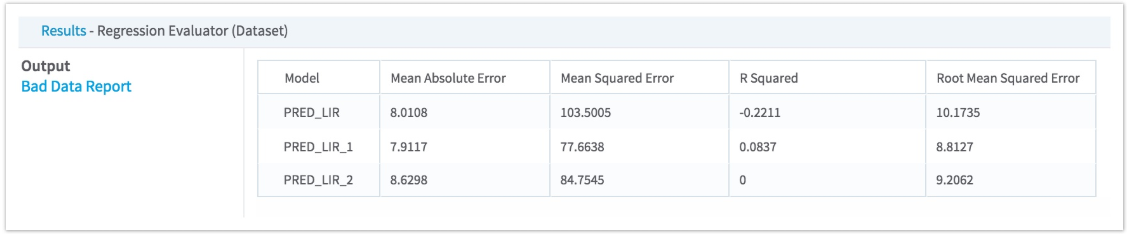
Computes several commonly used statistical tests to determine the accuracy of several columns (Predicted Values). These represent predictions against one column (Actual Value) which is specified as the "ground truth."

Information at a Glance
| Category | Model Validation |
| Data source type | HD |
| Sends output to other operators | No |
| Data processing tool | n/a |
Note: The Regression Evaluator (HD) operator is for Hadoop data only. For database data, use the
Regression Evaluator (DB) operator.
For information about the metrics used in this operator, see Computed Metrics and Use Case for the Regression Evaluator.
Input
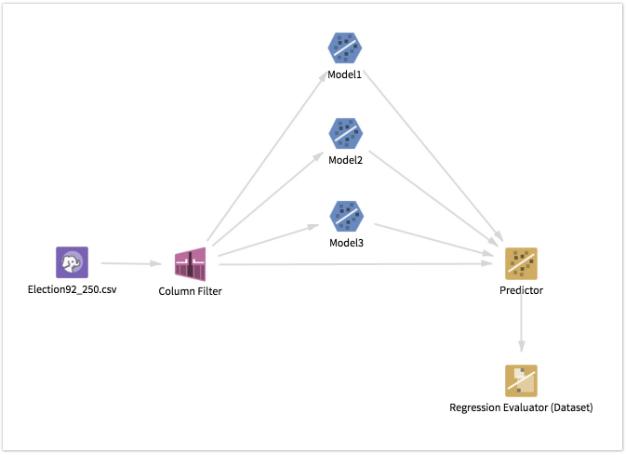
A tabular data set from Hadoop that contains a numeric column of actual values (known truth) and numeric column(s) of predicted values.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Actual Value | A numeric column that holds the dependent variable that the models were used to train on, or a column of known values for the dependent variable. |
| Predicted Values (to Compare with Actual Value) | A set of numeric column(s) whose results predict the model. For example, if you are using this to evaluate several different linear regressions, the predicted values for each of the regressions is selected here. |
| Write Rows Removed Due To Null Data To File | Rows with null values are removed from the analysis. This allows you to specify that the data with null values be written to a file.
The file is written to the same directory as the rest of the output. The filename is suffixed with _baddata.
|
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
Copyright © Cloud Software Group, Inc. All rights reserved.