Linear Regression (DB)
Use the Linear Regression operator to fit a trend line to an observed data set, in which one of the data values - the dependent variable - is linearly dependent on the value of the other causal data values or variables - the independent variables.

Information at a Glance
For more information about using linear regression, see Fitting a Trend Line for Linearly Dependent Data Values.
Algorithm
The Team Studio Linear Regression operator applies a Multivariate Linear Regression (MLR) algorithm to the input data set. For MLR, a Regularization Penalty Parameter that can be applied in order to prevent of the chances of over-fitting the model.
The Linear Regression operator implements Ordinary Regression and allows for the Stepwise Feature to avoid over-fitting a model with too many variables. The Ordinary Regression algorithm uses the Ordinary Least Squares (OLS) method of regression analysis, meaning that the model is fit such that the sum-of-squares of differences of observed and predicted values is minimized.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Dependent Column | The dependent column specified for the regression. This is the quantity to model or predict. The list of the available data columns for the Regression operator is displayed. Select the data column to consider the dependent variable for the regression.
The Dependent Column should be a numerical data type. |
| Columns | Click
Select Columns to select the available columns from the input data set for analysis.
For a linear regression, select the independent variable data columns for the regression analysis or model training. You must select at least one column or one interaction variable. |
| Interaction Parameters | Enables selecting available independent variables, where those data parameters might have a combined effect on the dependent variable. See Interaction Parameters Dialog box for detailed information. |
| Stepwise Feature Selection |
|
| Stepwise Type | Specifies the different ways to determine which of the independent variables are the most predictive to include in the model.
This option is enabled only if Stepwise Feature Selection is selected. For all Stepwise Type methods, the minimum significance value is defined by the operator's Check Value parameter specified, and the approach for determining the significance is defined by Criterion Type.
|
| Criterion Type | Specifies the approach for evaluating a variable's significance in the regression model.
Enabled only if
Stepwise Feature Selection is selected.
|
| Check Value | Specifies the minimal significance level value to use as feature selection criterion in Forward, Backward, or Stepwise Regression Analysis.
Enabled only if Stepwise Feature Selection is selected. Default value: 0.05. If you are running without a stepwise approach, consider setting Check Value to 10% of the resulting AIC value. |
| Group By | Specifies a column for categorizing or subdividing the model into multiple models based on different groupings of the data. A typical example is using gender to create two different models based on the data for males versus females. A modeler might do this to determine if there is a significant difference in the correlation between the dependent variable and the independent variable based on whether the data is for a male or a female.
The Group By column cannot be selected as a Dependent Column or as an independent variable (in Columns in the model. |
| Draw Residual Plot | Provides the option to output Q-Q Plot and Residual Plot graphs for the linear regression results.
See Output for details on the resulting output graphs when Draw Residual Plot is set to true. Default value: false. |
Output
- Visual Output
-
- Ordinary Linear Regression Output
-
Because data scientists expect model prediction errors to be unstructured and normally distributed, the Residual Plot and Q-Q Plot together are important linear regression diagnostic tools, in conjunction with R2, Coefficient and P-value summary statistics.
The remaining visual output consists of Summary, Data, Residual Plot, and Q-Q Plot.
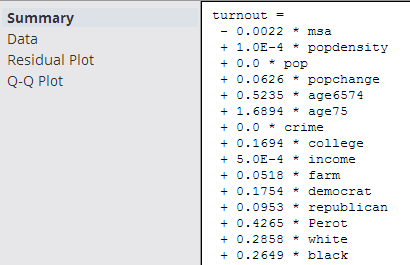
- Summary
- The
Summary output displays the details of the derived linear regression model's Equation and Correlation Coefficient values along with the R2 and Standard Error statistical values.
The derived linear regression model is shown as a mathematical equation linking the Dependent Variable (Y) to the independent variables (X1, X2, etc.). It includes the scaling or Coefficient values (β1, β2, etc.) associated with each independent variable in the model.
The following overall model statistical fit numbers are displayed.
- R2: it is called the multiple correlation coefficient of the model, or the Coefficient of Multiple Determination. It represents the fraction of the total Dependent Variable (Y) variance explained by the regression analysis, with 0 meaning 0% explanation of Y variance and 1 meaning 100% accurate fit or prediction capability.
- S: represents the standard error per model (often also denoted by SE). It is a measure of the average amount that the regression model equation over-predicts or under-predicts.
The rule of thumb data scientists use is that 60% of the model predictions are within +/- 1 SE and 90% are within +/- 2 SEs.
For example, if a linear regression model predicts the quality of the wine on a scale between 1 and 10 and the SE is .6 per model prediction, a prediction of Quality=8 means the true value is 90% likely to be within 2*.6 of the predicted 8 value (that is, the real Quality value is likely between 6.8 and 9.2).
In summary, the higher the R2 and the lower the SE, the more accurate the linear regression model predictions are likely to be.
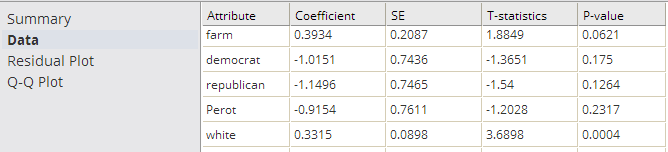
- Data
- The
Data results are a table that contains the model coefficients and statistical fit numbers for each independent variable in the model.
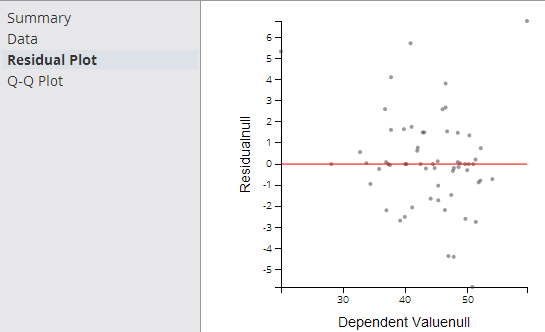
- Residual Plot
-
The Residual Plot displays a graph that shows the residuals (differences between the observed values of the dependent variable and the predicted values) of a linear regression model on the vertical axis and the independent variable on the horizontal axis, as shown in the following example.
A modeler should always look at the Residual Plot as it can quickly detect any systematic errors with the model that are not necessarily uncovered by the summary model statistics. It is expected that the Residuals of the dependent variable vary randomly above and below the horizontal access for any value of the independent variable.
If the points in a residual plot are randomly dispersed around the horizontal axis, a linear regression model is appropriate for the data; otherwise, a non-linear model is more appropriate.
A "bad" Residual Plot has some sort of structural bend or anomaly that cannot be explained away. For example, when analyzing medical data results, the linear regression model might show a good fit for male data but have a systematic error for female data. Glancing at a Residual Plot could quickly catch this structural weakness with the model.
In summary, the Residual Plot is an important diagnostic tool for analyzing linear regression results, allowing the modeler to keep a hand in the data while still analyzing overall model fit.
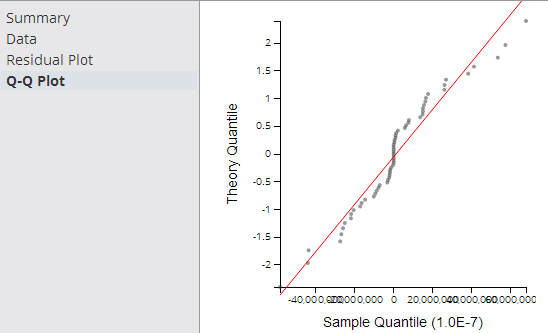
- Q-Q Plot
- The Q-Q (Quantile-Quantile) Plot graphically compares the distribution of the residuals of a given variable to the normal distribution (represented by a straight line), as shown in the following example.
The closer the dots are to the line, the more normal of a distribution the data has. This provides a better sense of whether a linear regression model is a good fit for the data. Any sort of variance from the line for a certain quantile, or section, of data should be investigated and understood.
The Q-Q Plot is an interesting analysis tool, although not always easy to read or interpret.
- Data Output
- A file with structure similar to the visual output structure is available.