| Processing runtime
|
The processing runtime is the core set of components included in every
Spotfire Statistics Services installation.
The Processing Runtime implements the functionality of the server by accepting and processing jobs (requests submitted by supported APIs), providing support for node administration and maintenance, performing event logging to provide full traceability, and retrieving job results. The engine runs in the context of the processing runtime.
|
| Data access layer
|
The data access layer enables communication to a job database on a database server. When a job is persisted in the job database, a user can access that job as needed.
|
| Job queue
|
The job queue handles job scheduling of jobs in the job database. Users can schedule and monitor jobs.
|
| Periodic cleanup
|
The periodic cleanup component makes sure that the necessary maintenance tasks can and do run. You can configure settings related to the preservation or deletion of job definitions and job artifacts, which are results from the execution of jobs.
|
| Configuration store
|
The configuration store is a component that manages server configuration settings. This component stores the current configuration in the
spserver.properties properties file and provides JMX access to the current configuration.
|
| Engine pool
|
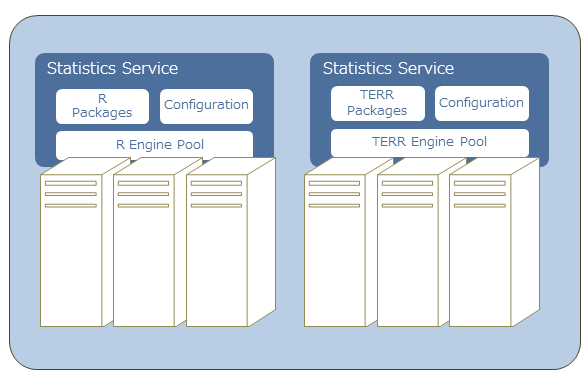
The engine pool component manages the engines. You can run multiple engines in an engine pool, but you cannot mix engines of different types. For example, you cannot run an
open-source R engine and a
TERR engine in a single engine pool. The following image shows two clusters, each configured to run a specific engine type.
Example engine clusters configured by engine type.
|