Working with Data Channels
This page shows us how to configure and deploy data channels.
Contents
Overview
A data channel is a configurable and deployable component that maps between an external protocol and scoring flows. A data sink is a data channel that consumes output data with a known schema and a standard serialization format. It defines the format of the end result. On the other hand, a data source is a data channel that provides input data with a known schema and a standard serialization format.
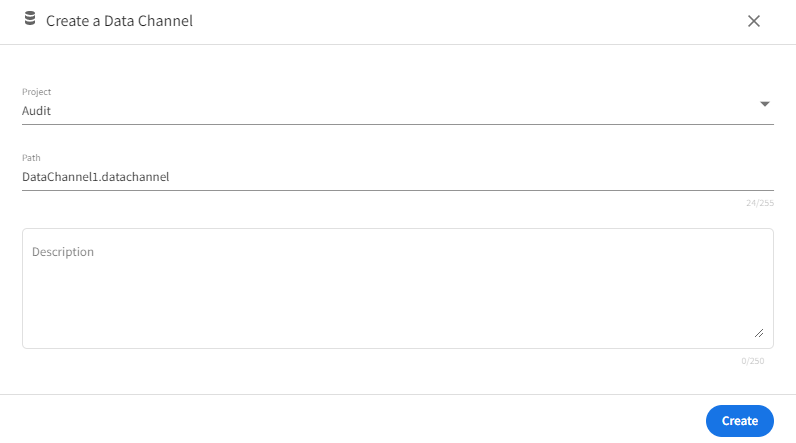
Adding a Data Channel
- In the Project Explorer pane, select Data Channels.
- Click Create a data channel to create a new data channel. You can also click the Add one option to add a new data channel if there are none present.
- On the Create a Data Channel page, select the project, for which you wish to create the data channel, from the drop-down list.
- Add data channel name and description, if needed.
- Click Create.
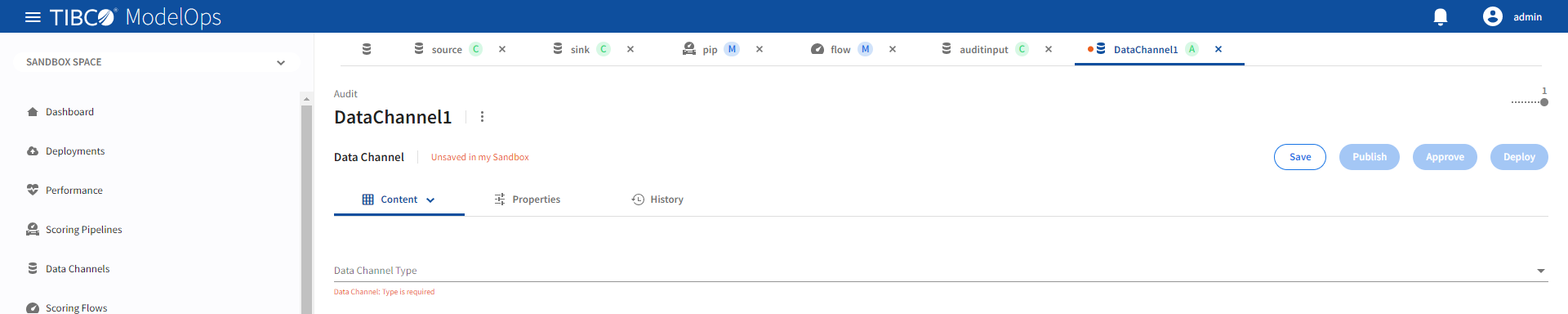
Configuring Data Channels
This section shows how to configure a data channel.
- In the Project Explorer pane, select Data Channels.
- Select the data channel, which you wish to configure, from the list.
- On the Data Channel Type tab, select the data channel type from the drop-down list.
-
Provide the required configuration for the data channel type. See the configuration reference for the data channel type being configured.
- On the Schema Definition tab, you get the following option to add a schema definition.
- Enter it manually: Builds schema from scratch.
- Get from CSV file: Extracts schema from a CSV file. You need to select a
csvfile if you choose this option. - Get from Data Channel: Adds schema from an existing data channel. You need to select a data channel if you choose this option.
- Get from Model: Extracts schema from a model. You need to select a model if you choose this option.
- Get from Scoring Flow: Extracts schema from a scoring flow. You need to select a scoring flow if you choose this option.
- Once done, click Save.
Data Channel Configuration Reference
This is the configuration reference for these data channels:
Each data channel requires different configuration which is summarized in the sections below.
File Data Channels
The file data channel supports reading (source) and writing (sink) to CSV data files.
The supported file data channel types are:
File Data Sink
Refer the following details to configure File Data Sink data channel type.
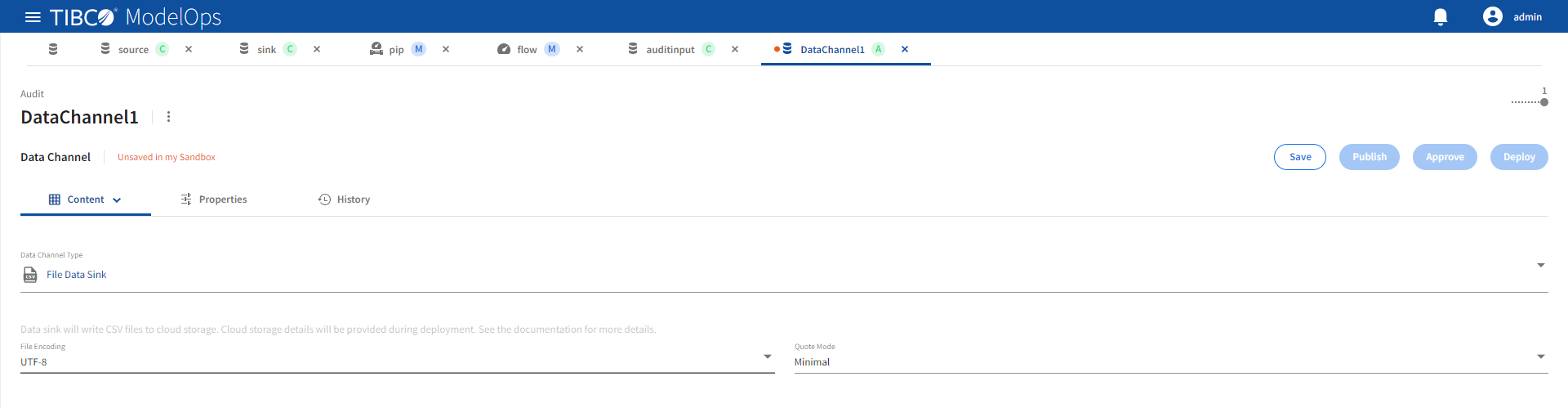
| Name | Default | Description |
|---|---|---|
| File Encoding | UTF-8 | CSV file character encoding. |
| Quote Mode | Minimal | See quote mode for details. |
The valid values for Quote Mode are:
| Value | Description |
|---|---|
| All | Quotes all fields. |
| All non null | Quotes all non-null fields. |
| Minimal | Quotes fields which contain special characters such as the field delimiter, quote character, or any of the characters in the line separator string. |
| Non numeric | Quotes all non-numeric fields. |
| None | Never quotes fields. |
File Data Source
Refer the following details to configure File Data source data channel type.
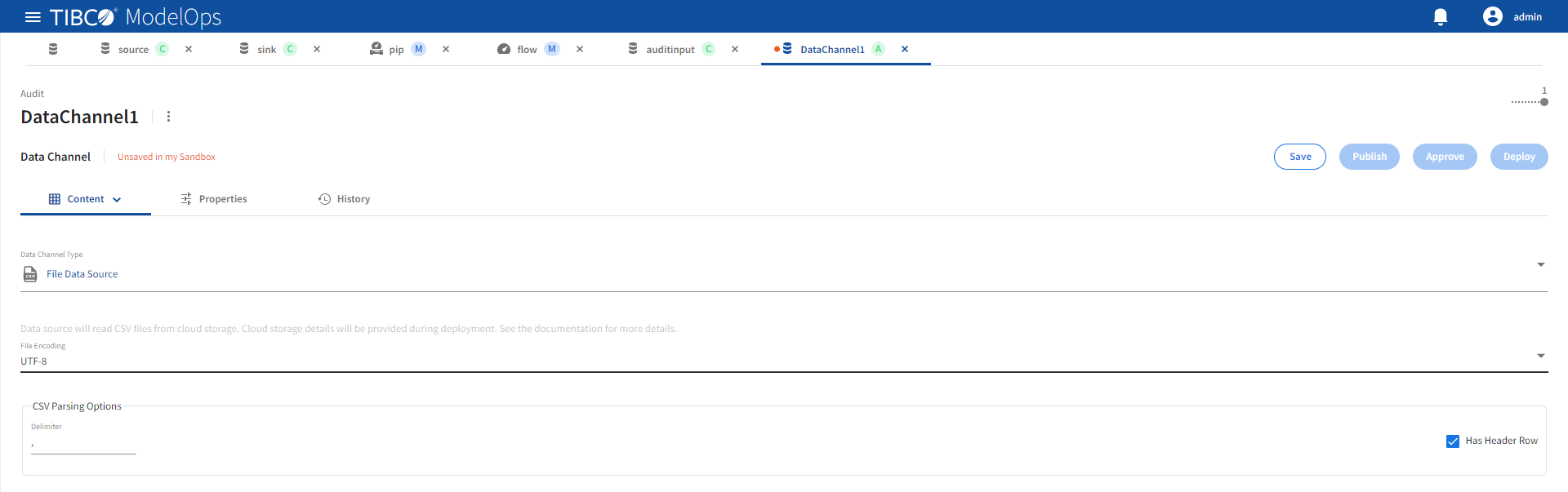
| Name | Default | Description |
|---|---|---|
| File Encoding | UTF-8 | CSV file character encoding. |
| Delimiter | , | Character field delimiter in CSV file. |
| Has Header Row | Checkbox selected | First row in CSV file contains header names. |
JDBC Data Channels
ModelOps JDBC data channels support selection or insertion of data records from or to a JDBC compliant relational database management system (RDBMS).
The supported JDBC data channel types are:
JDBC Data Sink
Refer the following details to configure JDBC Data Sink data channel type.
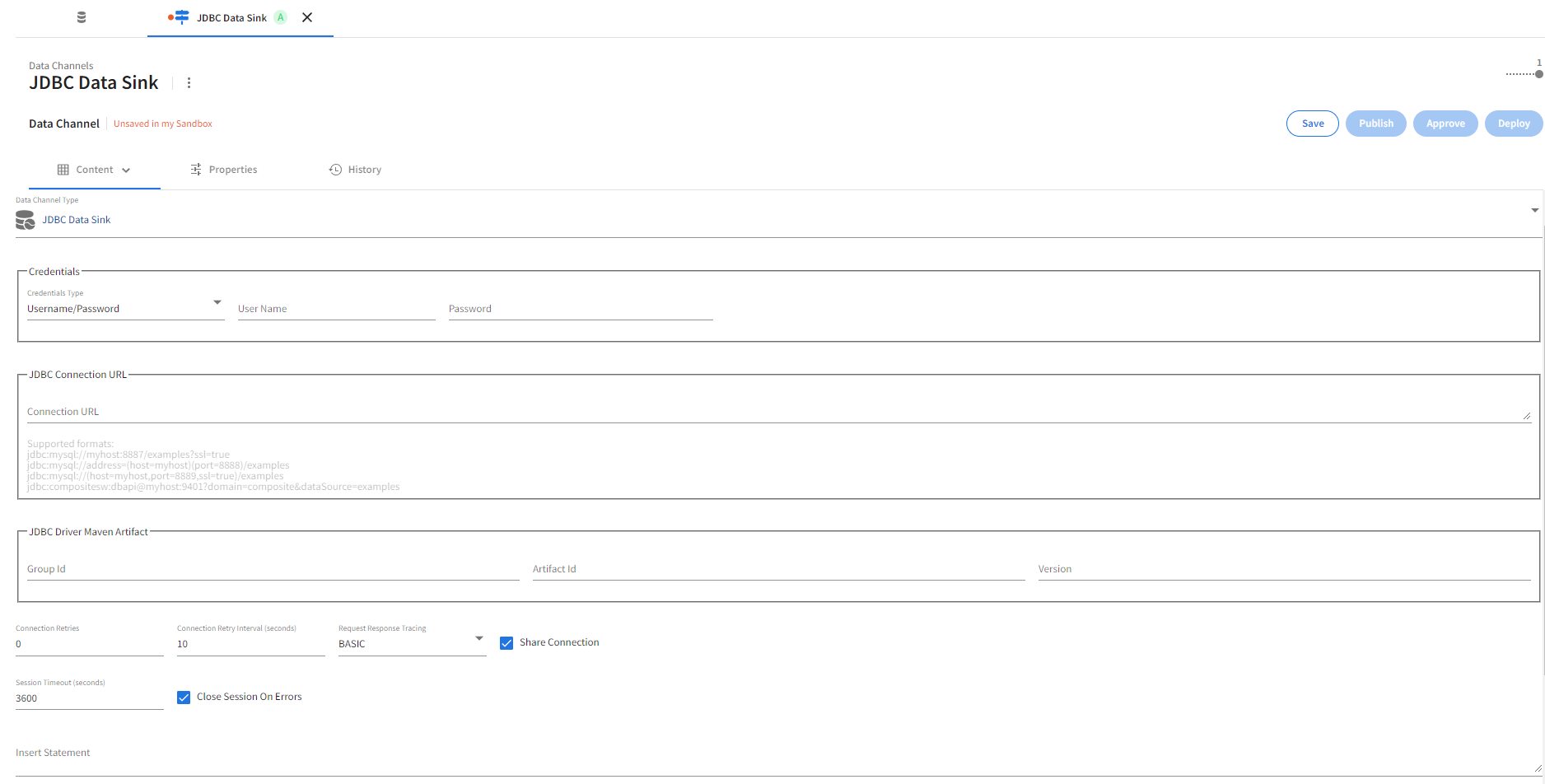
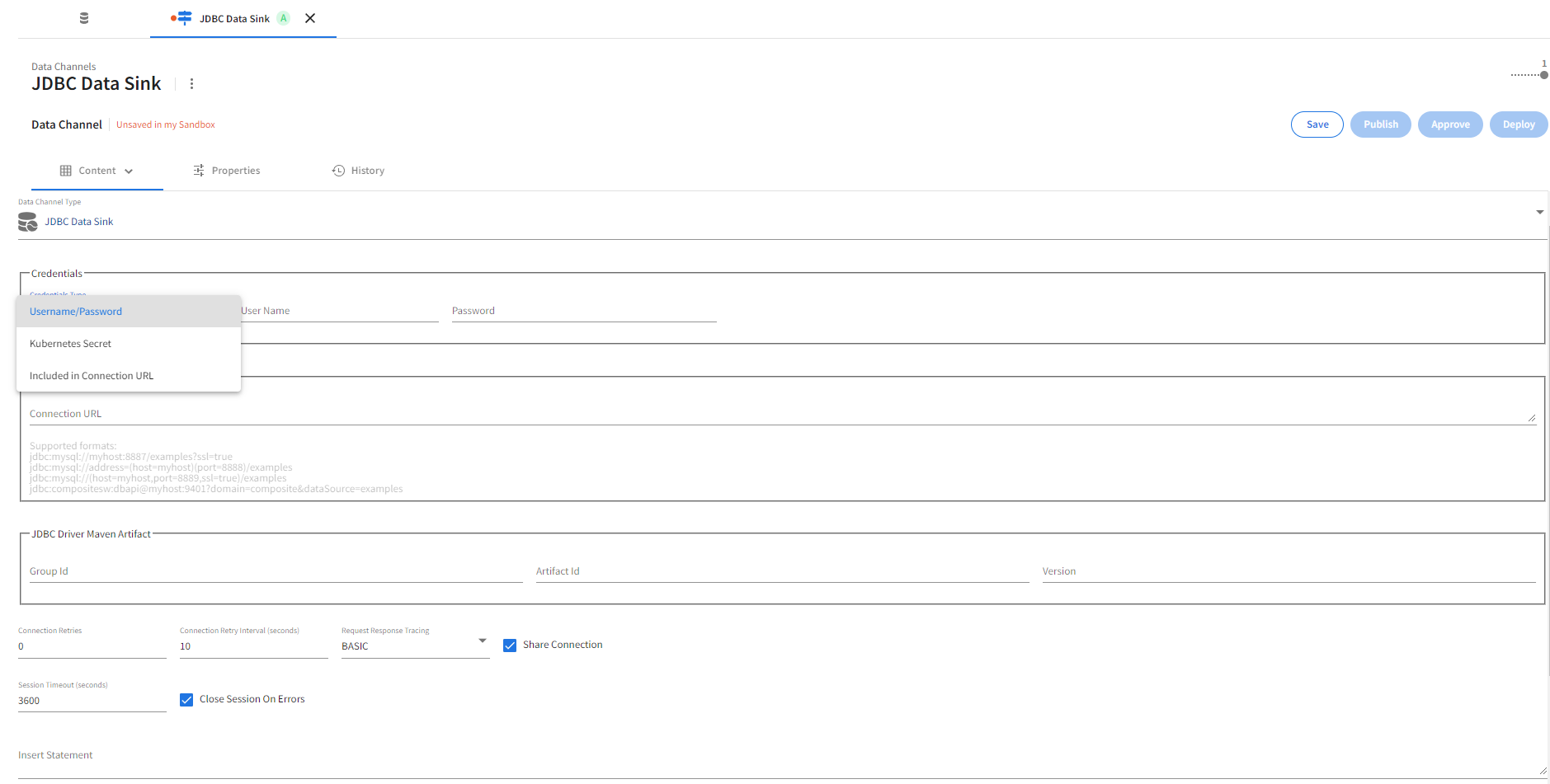
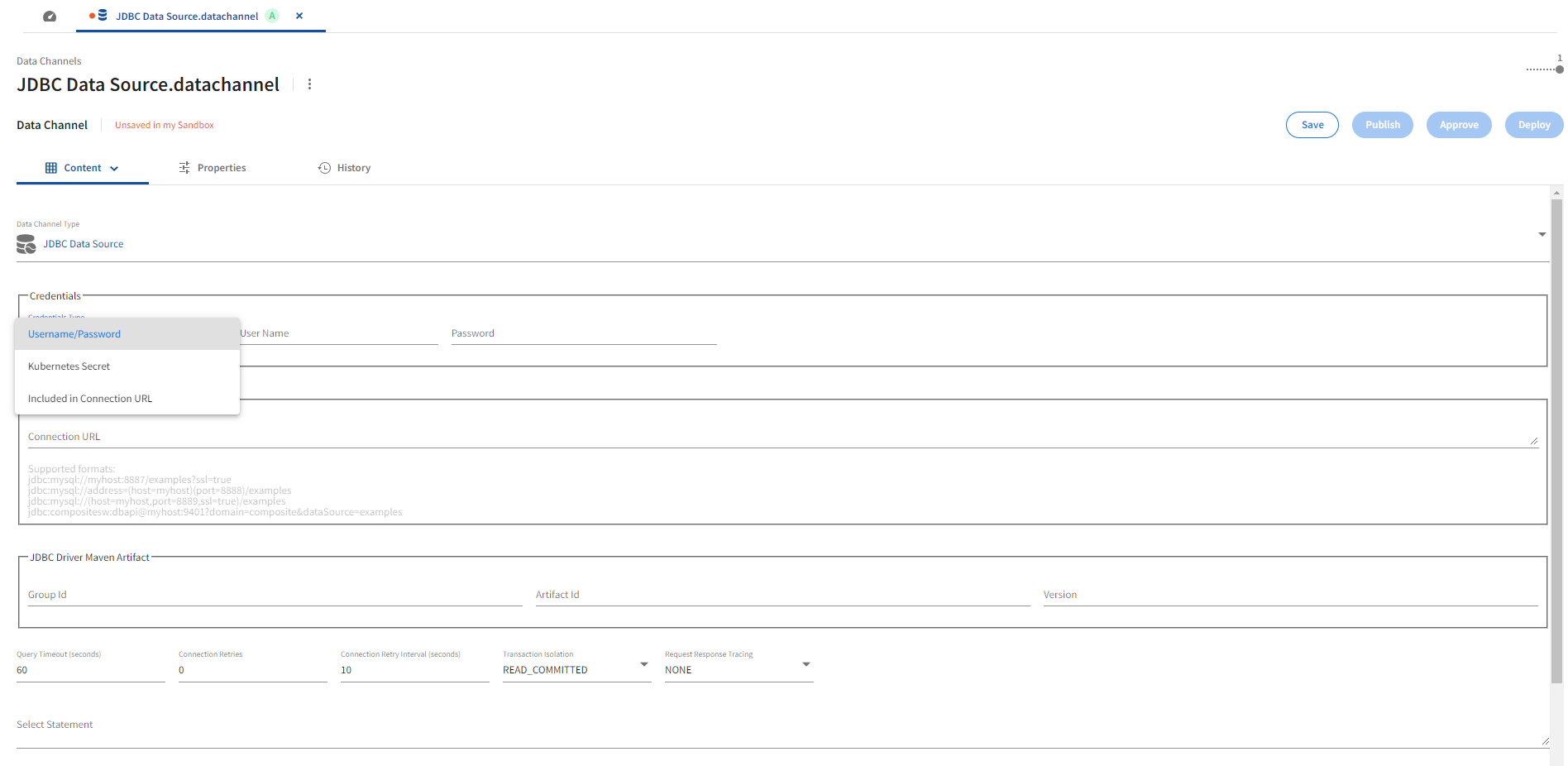
Credentials
The required database credentials are set in the Credentials section. The following Credentials Type dropdown options are available for database authentication.
| Authentication | Description | Comments |
|---|---|---|
Username/Password |
Database username and password. | The provided password will be treated as opaque data. |
Kubernetes Secret |
Database username and password as Kubernetes secret. | example-jdbc-channel-secret (See Kubernetes Secret section for the command template to create Kubernetes secrets). At deploy time, the secret name is used to find the Kubernetes secret that contains both the database user name and password. |
Included in Connection URL |
Database credentials specified with the Connection URL option. | jdbc:compositesw:dbapi@example.tibco.com:9401?domain=composite&dataSource=/examples/exampledb&user=exampleuser&password=examplesecret. This mechanism is strongly discouraged since passwords are stored in plain text. Use of Kubernetes Secret is preferred. |
Kubernetes Secret
To create Kubernetes secrets, use the following command template. Provide appropriate values for the Kubernetes secret name, username, password and namespace. Execute the kubectl command from command line.
kubectl create secret generic <jdbc-channel-secret-name> \
--from-literal=jdbc-database-username=<username> \
--from-literal=jdbc-database-password=<password> \
--namespace <data-channel-namespace>
Connection URL
A required text field, Connection URL is available to specify the JDBC connection URL.
| Name | Default | Description |
|---|---|---|
Connection URL |
None | JDBC database connection URL (e.g. jdbc:mysql://example.tibco.com:3306/exampledb). |
JDBC Driver Maven Artifact
The JDBC Driver Maven Artifact section provides the following options.
| Name | Default | Description |
|---|---|---|
Group Id |
None | JDBC driver Maven group identifier. Required. |
Artifact Id |
None | JDBC driver Maven artifact identifier. Required. |
Version |
None | JDBC driver Maven version number. Required. |
Connection Properties
The following database connection options are available.
| Name | Default | Description |
|---|---|---|
Connection Retries |
0 |
Number of connection retries before failure is reported. A value of 0 retries forever. |
Connection Retry Interval (seconds) |
10 |
Connection retry interval in seconds. Value must be > 0. |
Share Connection |
true |
Share a single database connection for all scoring pipeline logins (true), or create one database connection per scoring pipeline login (false). |
Insert Statement
A required text field, Insert Statement , is available to specify a SQL INSERT statement. The program expects a SQL prepared statement to be specified in this field.
| Name | Default | Description |
|---|---|---|
Insert Statement |
None | Insert statement for input record (e.g., INSERT INTO test(id, firstname, lastname, salary) VALUES (?, ?, ?, ?)). |
Request Response Tracing
A dropdown option is available to enable tracing.
| Name | Default | Description |
|---|---|---|
Request Response Tracing |
NONE |
Enable request response tracing. Valid values are BASIC, HEADERS or NONE. A value of NONE disables request response tracing. |
Login Session Properties
The following login session options are available.
| Name | Default | Description |
|---|---|---|
Close Session On Errors |
true |
Close login session on database errors. |
Session Timeout (seconds) |
3600 |
Pipeline login timeout in seconds to timeout inactive login sessions. A value of 0 disables timeouts. |
Supported Data Types
The JDBC data sink supports the following record data type to SQL type mapping.
| OpenAPI Type | OpenAPI Format | SQL Type | Comments |
|---|---|---|---|
| boolean | boolean | ||
| integer | int32 | integer | 32 bit signed value |
| integer | int64 | bigint | 64 bit signed value |
| number | double | double | |
| number | float | float | |
| string | longvarchar | UTF 8 encoded character data with a maximum length of 32,700 characters as mentioned here | |
| string | varbinary | Base64 encoded binary data (contentEncoding=base64) | |
| string | date | date | RFC 3339 full-date |
| string | date-time | timestamp | RFC 3339 date-time |
| array | longvarchar | String of JSON array. Supports all types and can be nested. | |
| object | longvarchar | String of JSON object. Supports all types and can be nested. |
JDBC Data Source
Refer the following details to configure JDBC Data Source data channel type.
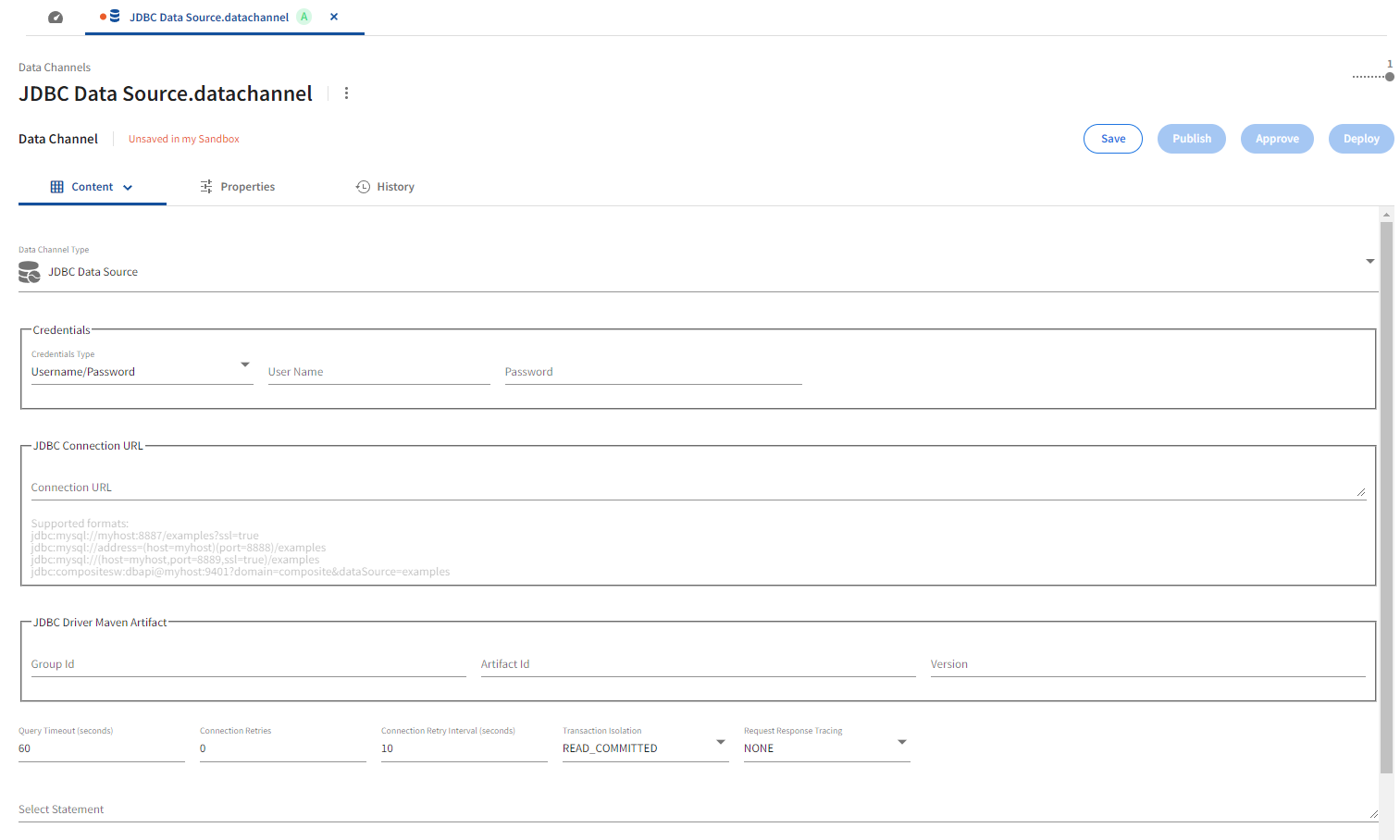
Credentials
The required database credentials are set in the Credentials section. The following Credentials Type dropdown options are available for database authentication.
| Authentication | Description | Comments |
|---|---|---|
Username/Password |
Database username and password. Mutually exclusive with Kubernetes Secret. | The provided password will be treated as opaque data. |
Kubernetes Secret |
Database username and password as Kubernetes secrets. | example-jdbc-channel-secret (See Kubernetes Secret section for the command template to create Kubernetes secrets). At deploy time, the secret name is used to find the Kubernetes secret that contains both the database user name and password. |
Included in Connection URL |
Database credentials specified with the Connection URL option. | jdbc:compositesw:dbapi@example.tibco.com:9401?domain=composite&dataSource=/examples/exampledb&user=exampleuser&password=examplesecret. This mechanism is strongly discouraged since passwords are stored in plain text. Use of Kubernetes Secret is preferred. |
Kubernetes Secret
To create Kubernetes secrets, use the following command template. Provide appropriate values for the Kubernetes secret name, username, password and namespace. Execute the kubectl command from command line.
kubectl create secret generic <jdbc-channel-secret-name> \
--from-literal=jdbc-database-username=<username> \
--from-literal=jdbc-database-password=<password> \
--namespace <data-channel-namespace>
Connection URL
A required text field, Connection URL is available to specify the JDBC connection URL.
| Name | Default | Description |
|---|---|---|
Connection URL |
None | JDBC database connection URL (e.g., jdbc:mysql://example.tibco.com:3306/exampledb). |
JDBC Driver Maven Artifact
The JDBC Driver Maven Artifact section provides the following options.
| Name | Default | Description |
|---|---|---|
Group Id |
None | JDBC driver Maven group identifier. Required. |
Artifact Id |
None | JDBC driver Maven artifact identifier. Required. |
Version |
None | JDBC driver Maven version number. Required. |
Connection Properties
The JDBC data source channel UI exposes the following database connection configuration properties.
| Name | Default | Description |
|---|---|---|
Connection Retries |
0 |
Number of connection retries before a failure is reported. A value of 0 retries forever. |
Connection Retry Interval (seconds) |
10 |
Connection retry interval in seconds. Value must be > 0. |
Query Timeout (seconds) |
60 |
Query timeout in seconds. A query execution timeout closes a login session. A value of 0 disables timeouts. |
Transaction Isolation |
READ_COMMITTED |
Transaction isolation, one of READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, or SERIALIZABLE. |
Request Response Tracing
A dropdown option is available to enable tracing.
| Name | Default | Description |
|---|---|---|
Request Response Tracing |
NONE |
Enable request response tracing. Valid values are BASIC, HEADERS or NONE. A value of NONE disables request response tracing. |
Select Statement
A required text field, Select Statement , is available to specify a SQL SELECT statement.
| Name | Default | Description |
|---|---|---|
Select Statement |
None | Select statement that defines the result set (e.g., SELECT id, firstname, lastname, salary FROM exampletable). |
Supported Data Types
The JDBC data source supports the following SQL type to record field data type mapping:
| SQL Type | OpenAPI Type | OpenAPI Format | Comments | |
|---|---|---|---|---|
| BIGINT | integer | int64 | 64 bit signed value | |
| BINARY | string | Base64 encoded binary data | ||
| BIT | boolean | |||
| BOOLEAN | boolean | |||
| CHAR | string | |||
| DATE | string | date | RFC 3339 full-date | |
| DOUBLE | number | double | ||
| FLOAT | number | float | ||
| INTEGER | integer | int32 | 32 bit signed value | |
| LONGVARBINARY | string | Base64 encoded binary data | ||
| LONGVARCHAR | string | |||
| NCHAR | string | |||
| NVARCHAR | string | |||
| REAL | number | float | ||
| SMALLINT | integer | int32 | 32 bit signed value | |
| TIME | string | date-time | RFC 3339 date-time | |
| TIME_WITH_TIMEZONE | string | date-time | RFC 3339 date-time | |
| TIMESTAMP | string | date-time | RFC 3339 date-time | |
| TIMESTAMP_WITH_TIMEZONE | string | date-time | RFC 3339 date-time | |
| TINYINT | integer | int32 | 32 bit signed value | |
| VARBINARY | string | Base64 encoded binary data | ||
| VARCHAR | string |
Kafka® Data Channels
The Kafka data channels subscribe to the configured Apache Kafka® brokers and can either read the data messages broadcasted by the brokers or publish data records to the brokers.
The supported Kafka data channel types are:
- Apache Kafka® Data Sink
- Apache Kafka® Data Source
Both Apache Kafka data sink and source channels support the same configuration properties.
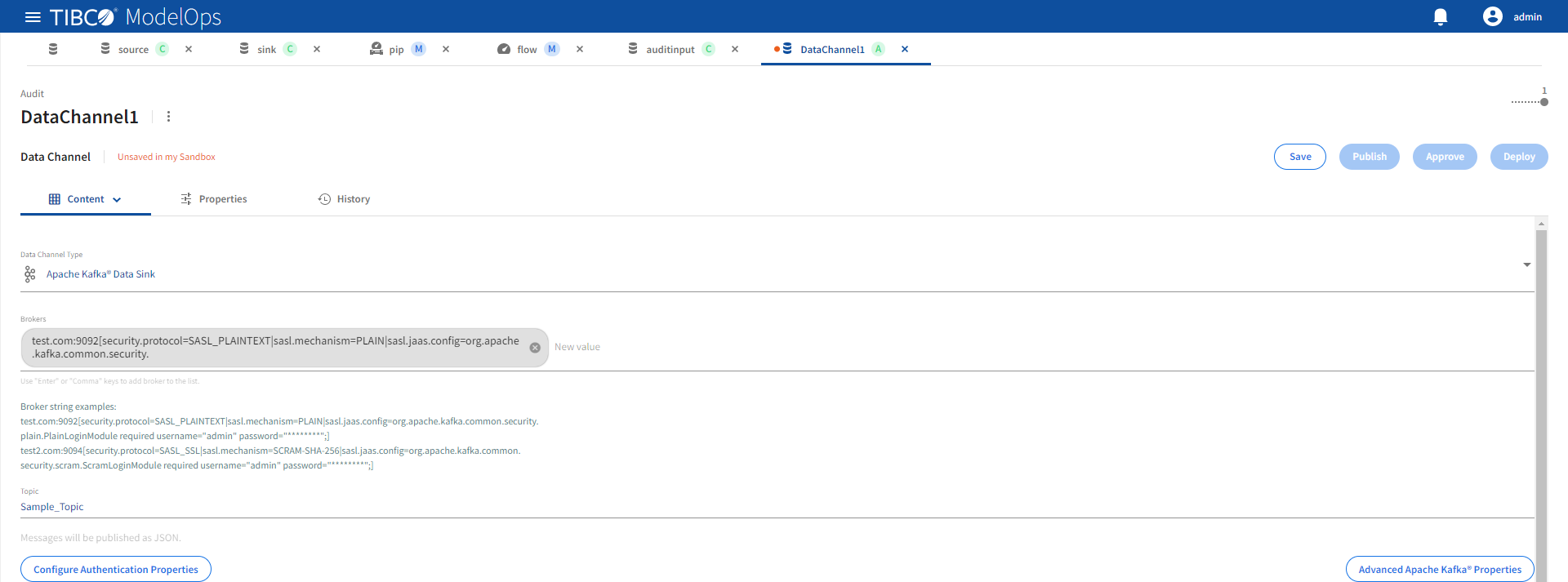
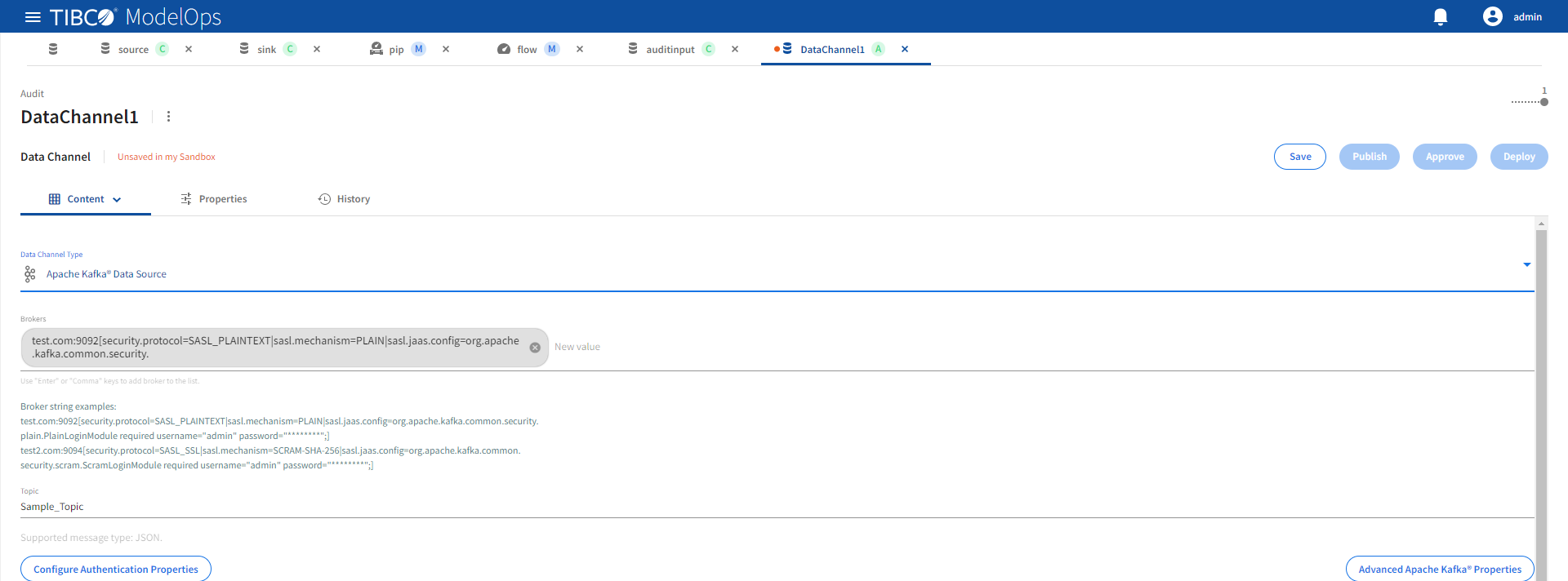
| Name | Default | Description |
|---|---|---|
| Brokers | None | A comma separated lists of Kafka brokers specified as address:port[config=value|config=value]. Required. |
| Topic | None | Topic name. Required. |
The optional [config=value] portion in the broker string allows specification of Kafka advanced configuration. For example, security.protocol and a security.mechanism can be configured in the broker string as shown below:
test.com:9093[security.protocol=SASL_SSL,sasl.mechanism=PLAIN|sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username=“admin” password=“********”;] test2.com:9093[security.protocol=SASL_SSL|sasl.mechanism=SCRAM-SHA-256|sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username=“admin” password=“********”;]
The advanced Kafka properties are configured using the Advanced Apache Kafka Properties dialog:
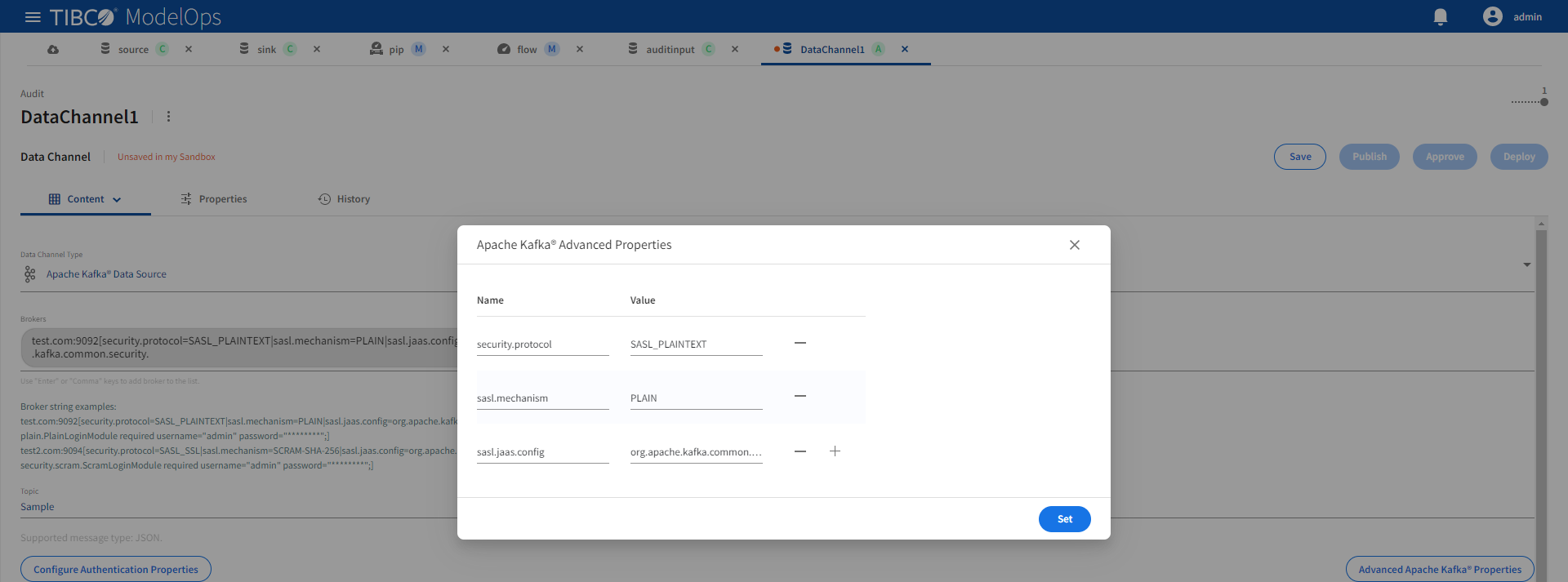
Authentication
Broker authentication properties are configured using the Configure Authentication Properties dialog:
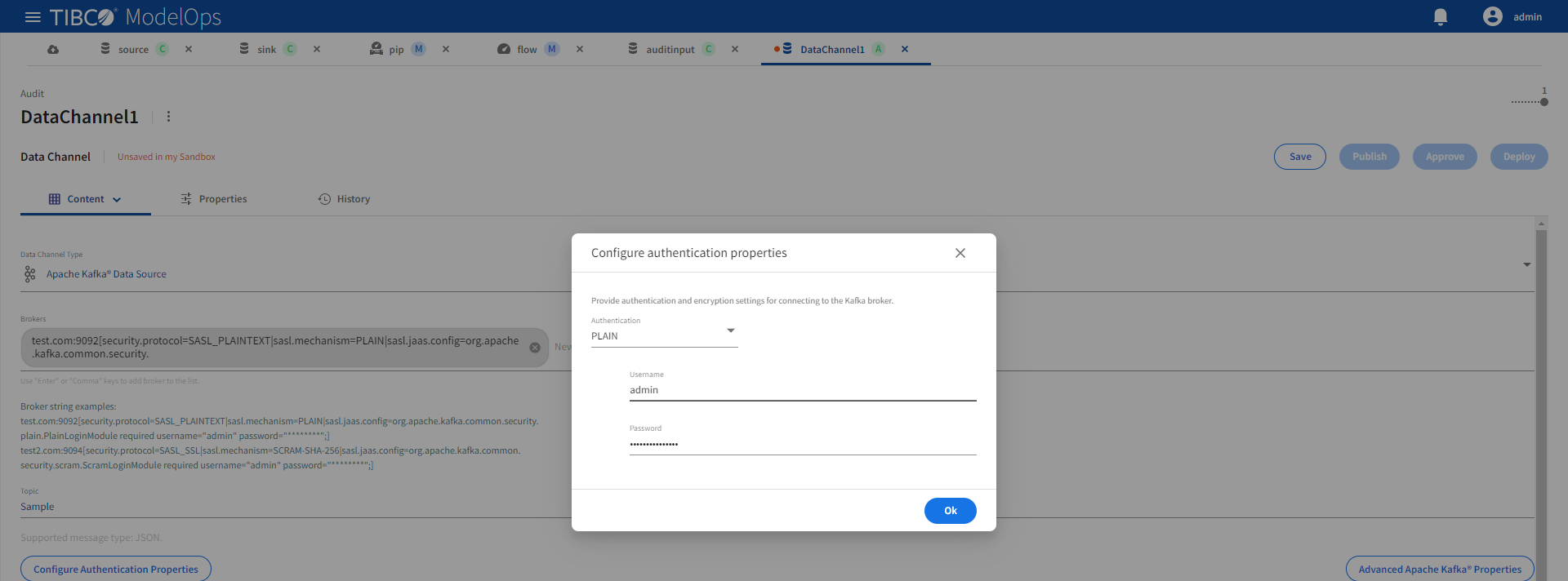
These authentication options are supported:
| Authentication | Description | Broker String Example |
|---|---|---|
| None | No authentication | test.com:9092 |
| PLAIN | Username and password authentication | test.com:9094[security.protocol=SASL_PLAINTEXT|sasl.mechanism=PLAIN|sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="********";] |
| SCRAM | Salted Challenge Response Authentication Mechanism | test.com:9094[security.protocol=SASL_SSL|sasl.mechanism=SCRAM-SHA-256|sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="admin" password="********";] |
Note:
- Configuring Kafka data channel authentication using the Configure Authentication Properties dialog is preferred.
- When configuring Kafka data channel authentication in a broker string using PLAIN or SCRAM authentication, provide a pipe separated list of required authentication configurations as shown in the table above.
Supported Data Serialization
The Kafka data sink channel supports JSON value serialization of the given records and publishes a single Kafka message per data record.
The Kafka data source channel supports JSON value deserialization of the incoming Kafka messages with the provided data schema and generates a data record per message.
Supported Data Types
The following data types are supported by Kafka source and sink data channels:
| OpenAPI Type | OpenAPI Format | Comments |
|---|---|---|
| boolean | ||
| integer | int32 | 32 bit signed value |
| integer | int64 | 64 bit signed value |
| number | double | Double precision floating point value |
| number | float | Single precision floating point value |
| string | UTF 8 encoded character data | |
| string | Base64 encoded binary data (contentEncoding=base64) | |
| string | date | An absolute timestamp at midnight for the given date in Streaming date and time format |
| string | date-time | An absolute timestamp for the given date and time in Streaming date and time format |
| array | Supports all types in this table and can be nested | |
| object | Supports all types in this table and can be nested |
REST Data Channels
The REST data channel supports accepting REST requests (source) from a REST client and generating REST responses (sink) as Server-Sent Events (SSE) to a SSE client.
The supported REST data channel types are:
REST Data Sink
Refer the following details to configure REST Data Sink data channel type.
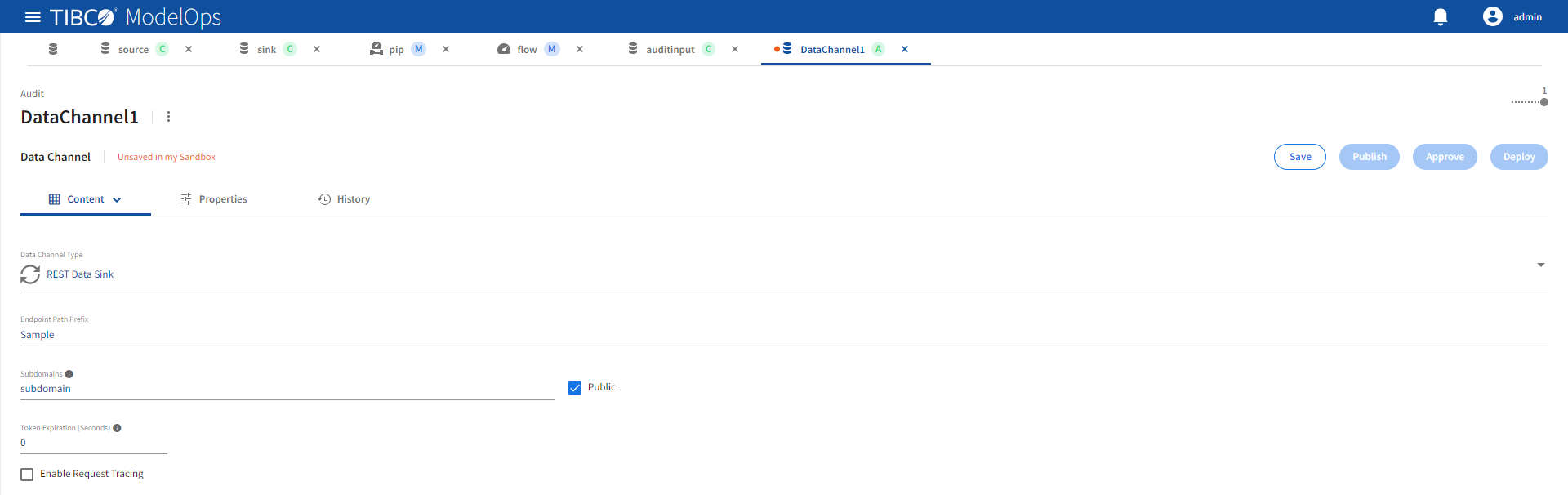
| Name | Default | Description |
|---|---|---|
| Enable Request Tracing | Unchecked | Enable tracing. |
| Endpoint Path Prefix | None | A unique URL path prefix for this data sink. See Addresses for more details. Required value. |
| Public | Checked | Expose endpoint outside of the ModelOps Kubernetes cluster and update DNS with data channel URL. |
| Subdomains | None | A DNS subdomain for this data sink. Must conform to DNS label restrictions. See Addresses for more details. Required when Public checked. |
| Token Expiration (Seconds) | 0 | Idle session expiration for both external SSE connections and internal pipeline connections. The login session is terminated following token expiration. A value of zero disables expiration. |
REST Data Source
Refer the following details to configure REST Data Source data channel type.
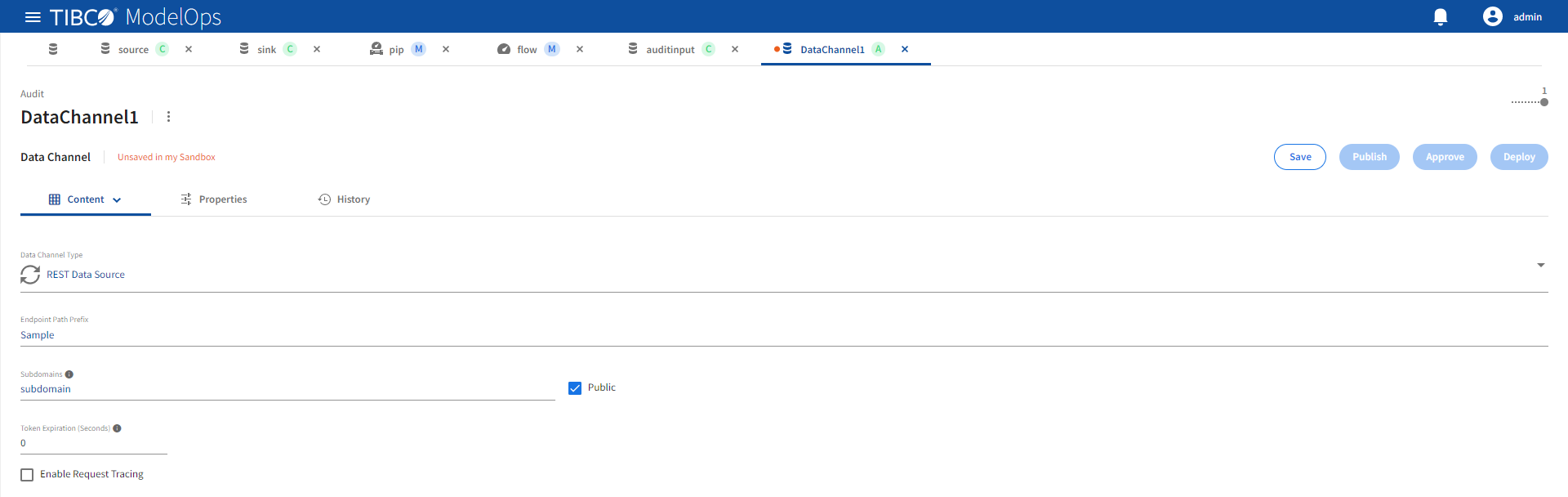
| Name | Default | Description |
|---|---|---|
| Enable Request Tracing | Unchecked | Enable tracing. |
| Endpoint Path Prefix | None | A unique URL path prefix for this data source. See Addresses for more details. Required value. |
| Public | Checked | Expose endpoint outside of the ModelOps Kubernetes cluster and update DNS with data channel URL. |
| Subdomains | None | A DNS subdomain for this data source. Must conform to DNS label restrictions. See Addresses for more details. Required when Public checked. |
| Token Expiration (Seconds) | 0 | Idle session expiration for both external REST connections and internal pipeline connections. The login session is terminated following token expiration. A value of zero disables expiration. |
Public Addresses
When exposed publicly, REST data channels are accessible via a public DNS hostname and URL. The hostname and URL are built from this information:
- ModelOps Kubernetes cluster hostname
- Configured DNS subdomains
- Configured endpoint URL path prefix
The URL format is:
https://<subdomains>.<modelops-kubernetes-hostname>/<endpoint-path-prefix>
For example, if a REST data channel is running in a ModelOps Kubernetes cluster with a hostname of example.tibco.com and it was configured with these values:
- a configured subdomain of rest.data.channels
- a configured endpoint path prefix of taxi-source-data
The REST data channel would be accessed at:
https://rest.data.channels.example.tibco.com/taxi-source-data
The domain name (<subdomains>.<modelops-kubernetes-hostname>) component of the URL must be unique for all running REST source and sink data channels. For example if a data channel with this URL is running:
https://rest.data.channels.example.tibco.com/taxi-source-data
Attempting to start another data channel with the same domain name, but a different endpoint URL path will fail, for example:
https://rest.data.channels.example.tibco.com/train-source-data
When a REST data channel is started, its URL is automatically published to the DNS server that is servicing the ModelOps Kubernetes cluster. An indeterminate DNS propagation delay determines when the URL is visible to clients.
Approving Data Channels
- In the Project Explorer pane, select Data Channels.
- Select the data channel that needs to be approved.
- Click Approve present in the right panel.
-
Click Approve present at the bottom of the list of data channels.
- Select the desired environments by toggling the switch and close the pop-up window.
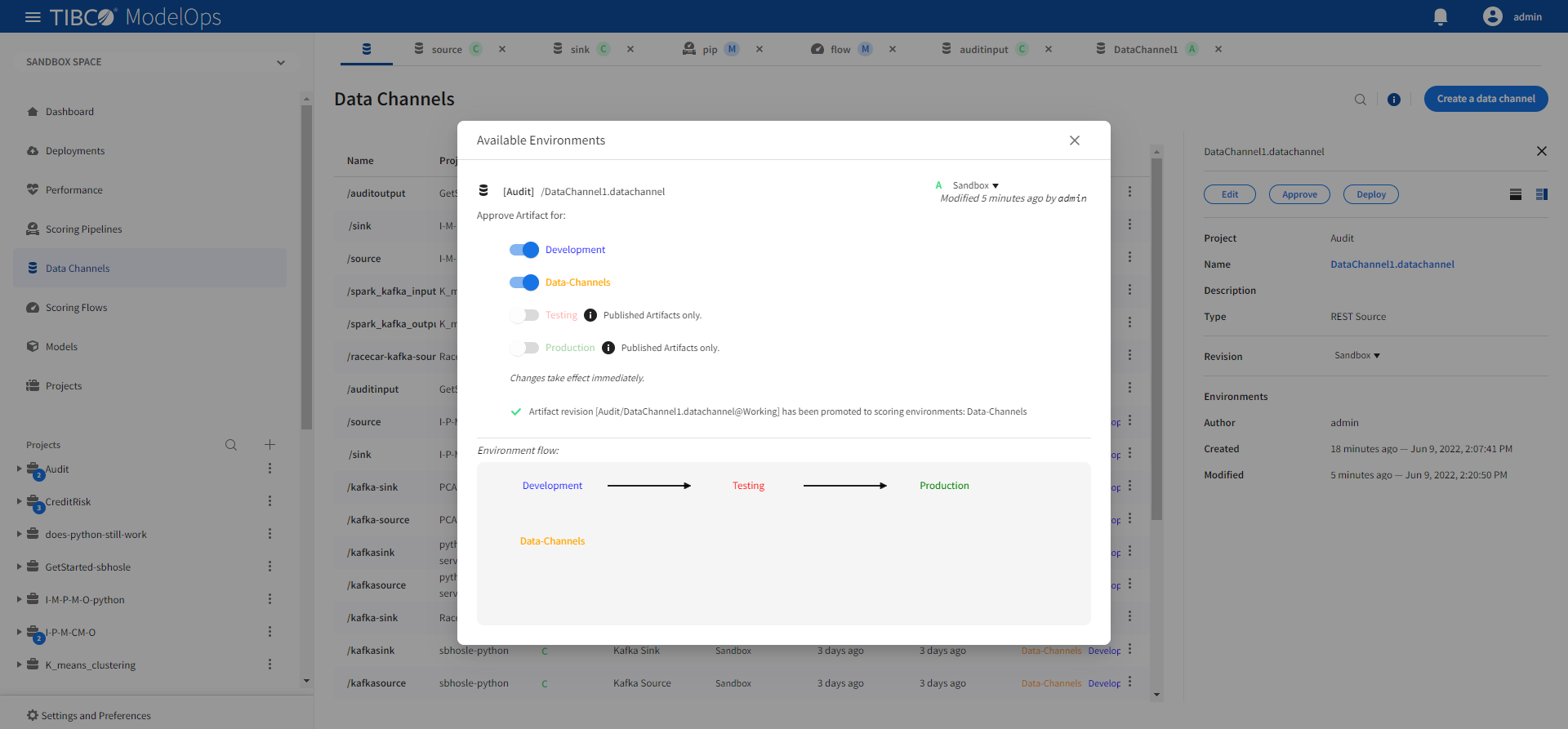
This data channel is now approved for deployment to the selected environments.
Note: Make sure to approve the data channels to an additional environment where scoring pipeline will be deployed
- Consider a scenario where a data channel is deployed to Data-Channels environment.
- Now, when you attempt to deploy pipeline to the Development environment, you might encounter a Pipeline deployment failure, since its data channel is not accessible from the Development environment (only Data-Channels).
Deploying Data Channels
- In the Project Explorer pane, select Deployments.
- Click Deploy new and select Data channel from the drop-down list.
- Add deployment name and description in the respective field.
- Select the data channel and the space from the drop-down list.
- Select Data-Channels environment from the drop-down list.
- Check off the additional environments that you need to expose the data channel to.
- Select when you need to schedule the job from the given options (Immediate, Future, or Periodic).
- Select the duration for which you need to run the job. You can run the job forever or add the duration as per your needs.
- Click Deploy.
Note: You might see failure in pipeline deployment if the data channel is not accessible from the environment in which the scoring pipeline is being deployed.
- Consider a scenario where a Data channel is deployed to Data-Channels environment with Test and Production as external environments.
- Now, when you attempt to deploy pipeline to the Development environment, you might encounter a Pipeline deployment failure, since its data channel is not accessible from the Development environment (only Data-Channels, Test, and Production)
- Make sure to approve and expose the data channel to the same environment as that of the scoring pipeline.
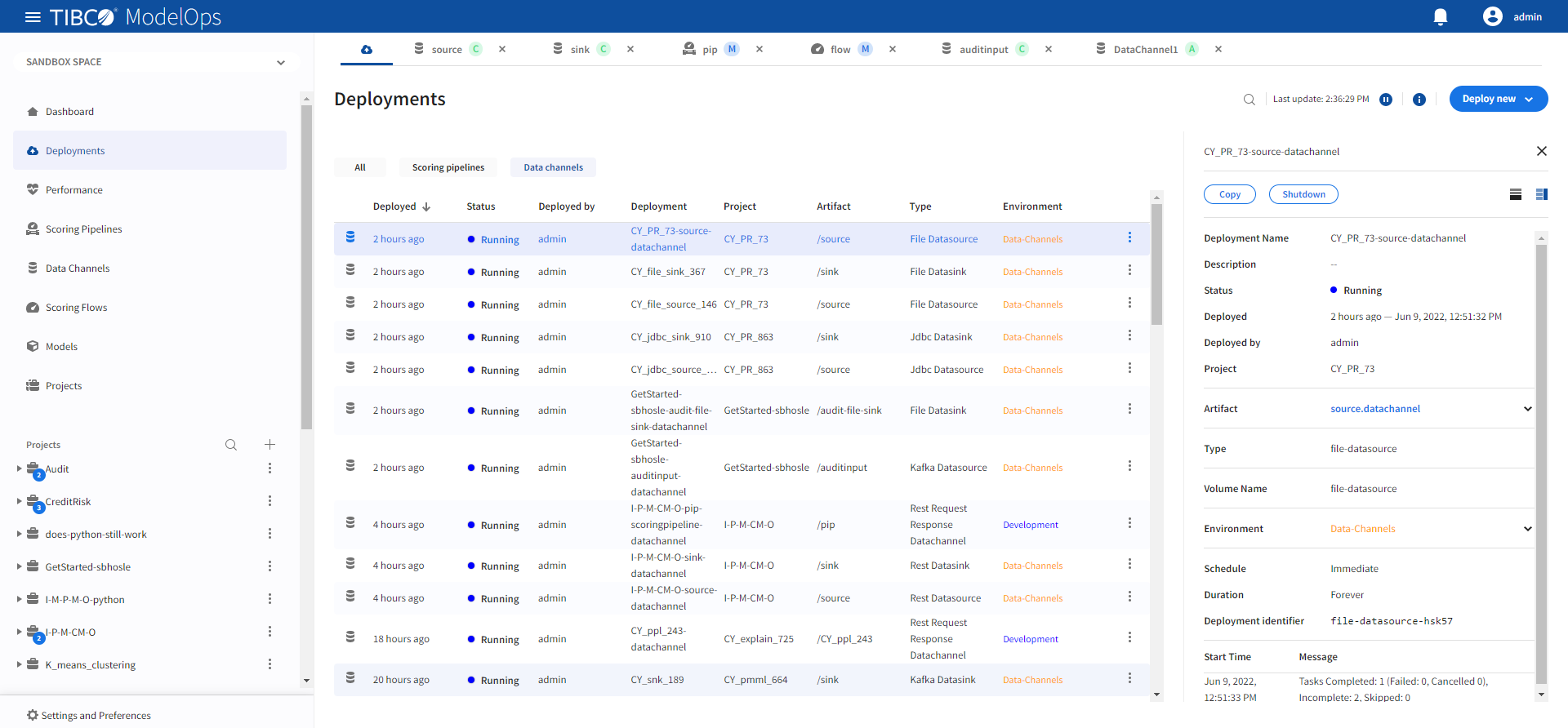
Viewing Deployed Data Channels
You can view status for deployed data channels by:
- In the Project Explorer pane, select Deployments.
- A list of deployed scoring pipelines and data channels appears here. Select Data channels filter to see the list of only data channels.
- The list is sorted based on the deployed time in ascending order.
- The list shows information such as time when the data channel was deployed, status of the deployed data channel, user by whom the data channel was deployed, deployment name, project, artifact, type of deployment, and environment.
- Additional information is displayed on the right pane after clicking the individual data channel instance.