
Working with the Python Step
This page explains the use of the Python processing step in TIBCO ModelOps scoring flows.
Contents
Overview
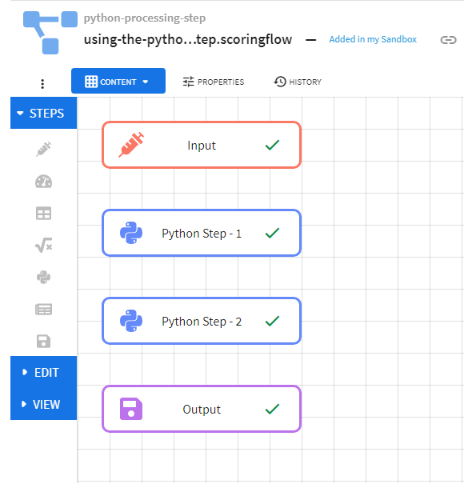
The Python step is one of the several processing steps that can be used in a TIBCO ModelOps scoring flow. Zero or more Python steps can be used in a scoring flow. Once Python scripts and other artifacts have been added to TIBCO ModelOps server, they can be used in a Python step. Each Python step can consume data from a processing step upstream and send data downstream.
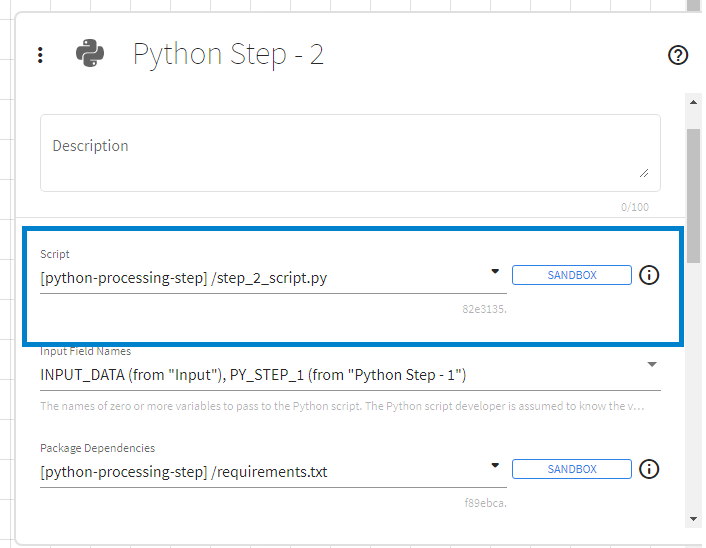
Input Field Names
A Python step can access data from upstream steps by using the output field names of the upstream steps. Data from upstream steps, when selected through the UI, is made available in the Python execution context through a Python dictionary named flowInputVars with:
- Keys set to the output field names of upstream steps
- Values set to Python dictionaries containing data from the corresponding upstream steps
A dictionary that contains data from a given upstream step has:
- Keys set to the field names defined in the output schema for that upstream step
- Values being set to data for fields flowing from that upstream step
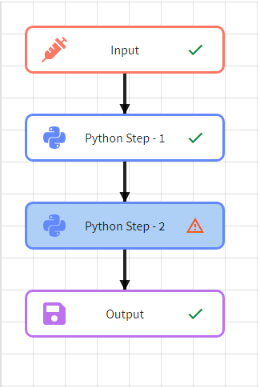
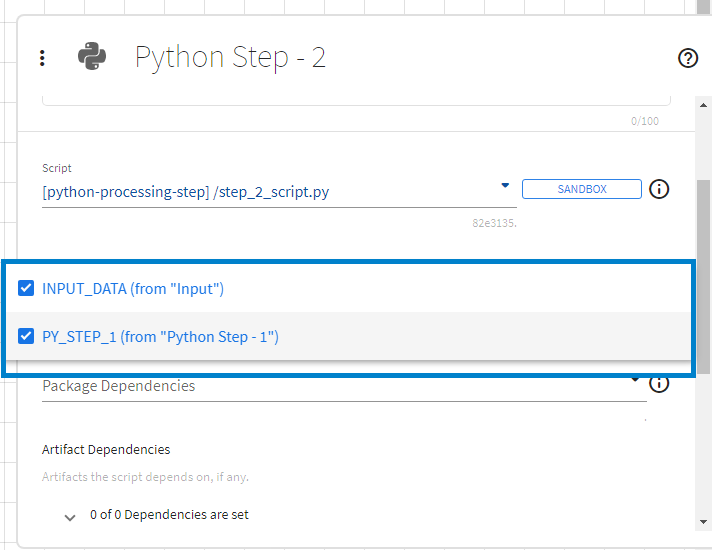
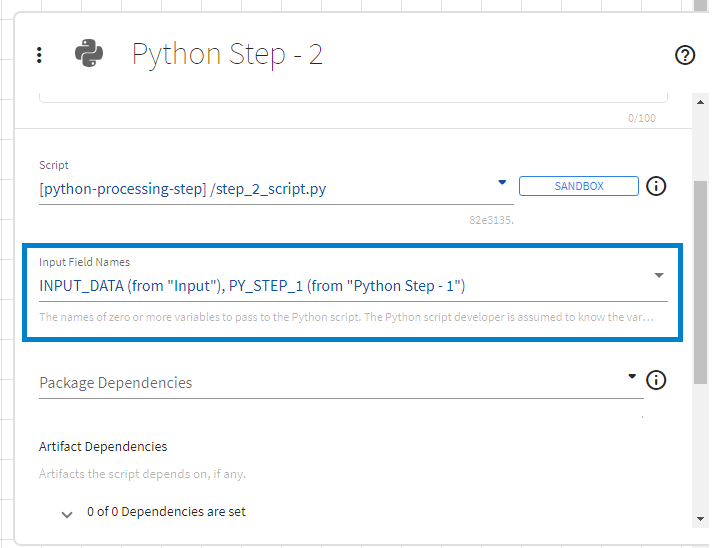
For example, the following Python code would access the SETOSA field from data from the Input step (output variable name: INPUT_DATA) and the LOG_X field from the data from the Python Step - 1 step (output variable name: PY_STEP_1):
# use flowInputVars to access data from a step data_input_step = flowInputVars["INPUT_DATA"] data_py_step_1 = flowInputVars["PY_STEP_1"] # access SETOSA field from Input step value_setosa = data_input_step["SETOSA"] # access LOG_X field from Python Step - 1 value_log_x = data_py_step_1["LOG_X"]
Package Dependencies
If certain Python packages are required for the Python script used in a Python step to run successfully, those requirements can be specified in the Package Dependencies property through an artifact that follows the standard pip requirements file format. Specifying the package dependencies property can be skipped if no packages outside of the Standard Python library are needed.
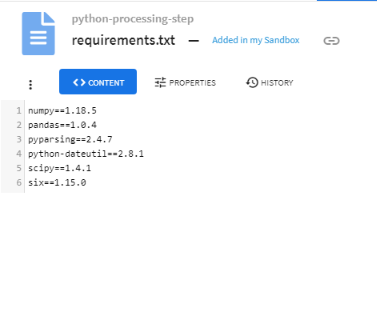
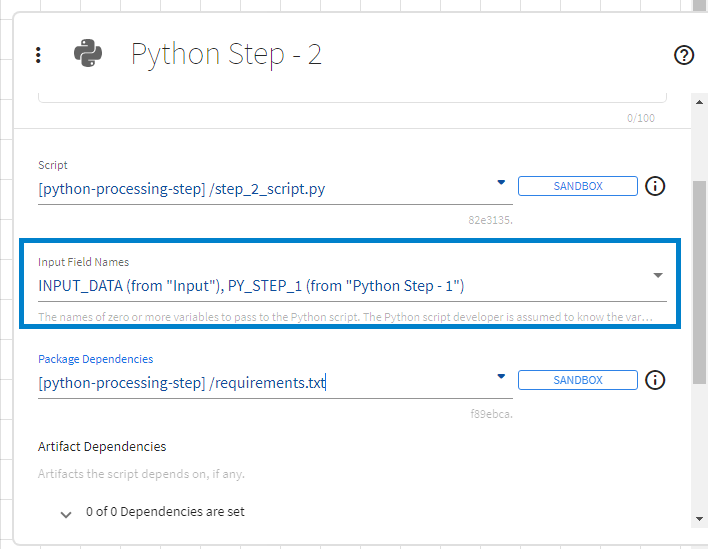
Artifact Dependencies
If certain artifacts are required for the Python script used in a Python step to run successfully, those files can be specified through Artifact Dependencies. Specifying artifact dependencies is optional.
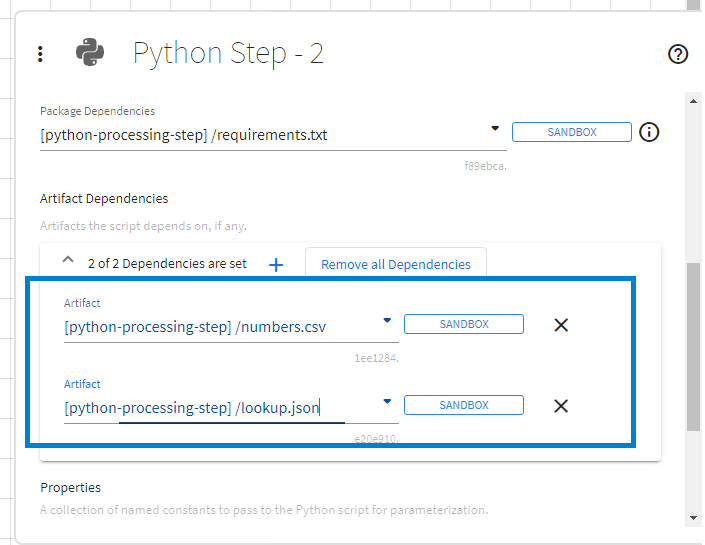
For example, the following Python code would access the CSV and JSON artifact dependencies described in the figure above:
import csv
import json
lookup_table = None
coefficient_table = None
# read & load look up table from JSON file
with open("lookup.json", "r") as json_file:
lookup_table = json.load(json_file)
# load data from CSV file
with open("numbers.csv", "r") as csv_file:
reader = csv.reader(csv_file)
coefficient_table = list(reader)
# other useful code ...
Parameters
A collection of key-value pairs can be made available in the Python execution context by specifying them through the Parameters property. The properties are made available in the Python execution context through a Python dictionary named flowParameters.
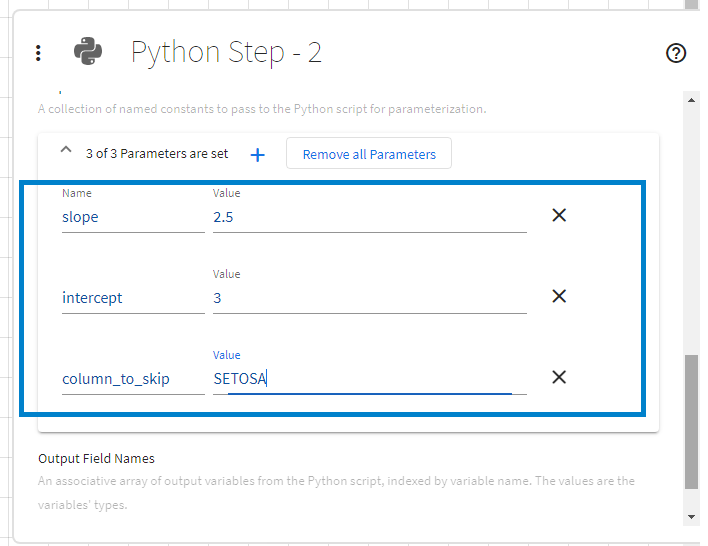
For example, the following Python code would access the parameters described in the figure above:
# some useful code ... slope_value = float(flowParameters["slope"]) intercept_value = float(flowParameters["intercept"]) skip_col = flowParameters["column_to_skip"] # other useful code ...
Script
The script to be used in a Python step can be specified through the TIBCO ModelOps artifact. This script follows standard Python syntax; the extensions flowInputVars, flowParameters, and flowOutputVars are considered reserved.
Output Field Names
A Python step can send data downstream through a Python dictionary named flowOutputVars with:
- Keys set to the field names defined in the output schema for the Python step
- Values being to actual data to be sent downstream
The data sent through flowOutputVars should match the schema specified for the Python step.
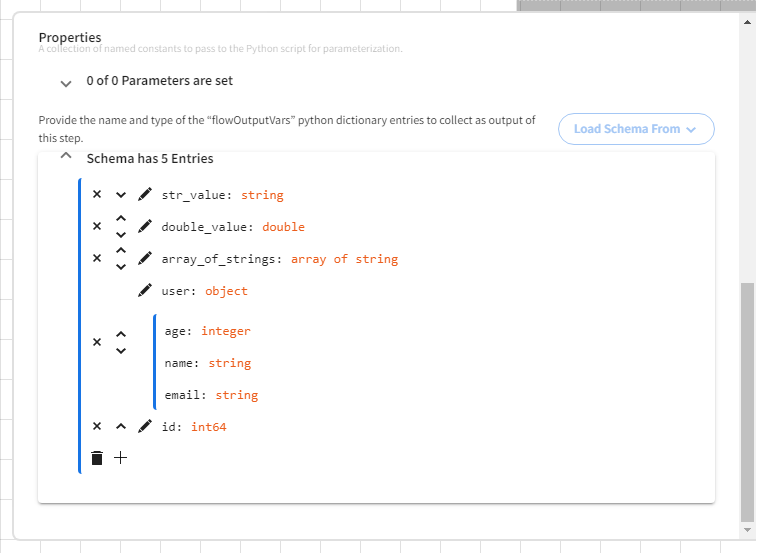
For example, the following Python code would set values for id, str_value, double_value, array_of_strings, and user fields/keys and send them downstream of the Python step:
data_from_input_step = flowInputVars["INPUT"]
idx = data_from_input_step["id"]
# prepare data to be sent
metal = "gold"
weight = 22.4
labels = ["models", "classification", "python"]
user_object = {
"age": 42,
"name": "john smith",
"email": "john@example.com"
}
#sent it downstream
flowOutputVars = {
"id": idx,
"str_value": metal,
"double_value": weight,
"array_of_strings": labels,
"user": user_object
}
Python Step Type Mapping
While receiving data into a Python Step (through flowInputVars) and sending data from the Python Step (through flowOutputVars), the mapping between Python data types and supported field types in ModelOps Scoring Pipelines is as follows:
| Open API Type | Open API Format | Python Data Type | Comments |
|---|---|---|---|
| boolean | bool | ||
| integer | int32 | int | 32 bit signed value |
| integer | int64 | int | 64 bit signed value |
| number | double | float | Double precision floating point value |
| number | float | float | Single precision floating point value |
| string | str | UTF 8 encoded character data | |
| string | bytearray | Base64 encoded binary data (contentEncoding=base64) | |
| string | date | datetime | RFC 3339 full-date |
| string | date-time | datetime | RFC 3339 date-time |
| array | list | Supports all types in this table and can be nested | |
| object | dict | Supports all types in this table and can be nested |