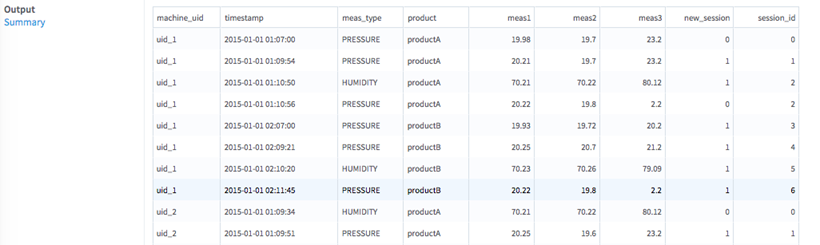
Sessionization
Enables the application of sessionization on time-series data to create a session_id column that, for each row (and user ID), gives the session the action belongs to.

Information at a Glance
A session can be described as an ordered list of a user's actions in completing a task. For information about how the boundaries of a session are defined, see the Session Boundaries parameter in the table below.
Sessionization is most commonly used in web analytics for log/clickstream analysis, but is also popular in other areas such as predictive maintenance and IoT.
Input
This operator requires a single tabular input that contains at least a datetime column.
- Bad or Missing Values
-
- Dirty data: When parsing delimited data, the Sessionization operator removes dirty data (such as strings in numeric columns, doubles in integer columns, or rows with the incorrect number of values) as it parses. These rows are silently removed because Spark is incapable of handling them.
- Null values: Before applying sessionization, the operator filters any rows that contain null values either in the Timestamp column or the Status column. The operator then processes these rows with null values according to the value of the Write Rows Removed Due to Null Data To File parameter. The number of rows removed due to null data is reported in the Summary tab of the visual output.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Session Boundaries | Select the method to define session boundaries: |
| Timestamp Column | Select the datetime column that contains the timestamp for each action in the data set. |
| Time Interval Threshold (seconds) | Required only if
Session Boundaries is set to
Time Interval Threshold.
Enter the threshold of inactivity, in seconds, that is used to define a new session. |
| Status Column | Required only if
Session Boundaries is set to
Change of Status.
Specify the column to use to detect the change of assignation to define a new session. |
| User ID Column(s) | Select the user ID column(s) to use to partition the input data set and create session IDs for each distinct user. |
| Columns to Keep | Select the input columns to keep in the output. |
| Write Rows Removed Due to Null Data To File |
Rows with null values are removed from the analysis. Use this parameter to specify that the data with null values is written to a file.
The file is written to the same directory as the rest of the output. The filename is appended with the suffix _baddata.
|
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|