Batch Aggregation
Performs aggregations on multiple columns.
Input
One data set from HDFS. The operator requires at least some numeric columns on which to compute the aggregations. It can include a group by column of any type. For example, you can use an input data set of counties and demographic information to get some aggregations about counties by state.
- Bad or Missing Values
-
Dirty data: When parsing delimited data, the Batch Aggregation operator removes dirty data (such as strings in numeric columns, doubles in integer columns, or rows with the incorrect number of values) as it parses. These "dirty" rows are silently removed because Spark is incapable of handling them.
Null values: Before calculating any of the aggregations, the operator filters any rows that contain null values in the group by column, or in any of the columns selected for aggregations. The operator then processes these rows with null values according to the value of the Write Rows Removed Due to Null Data To File" parameter. The number of rows removed due to null data are reported in the Summary tab of the visual output.
Restrictions
Median with many distinct values in group by: This operator might not be able to calculate medians if the group by column has many distinct values. Specifically, if there are more distinct values in the group by column than fit in driver memory, the operator might fail with an out-of-memory exception. The default driver memory in Spark is set to 1024 MB, so if your input data has more than 1 million distinct values in the group-by column(s), you might need to increase the driver memory using the Advanced Spark Settings dialog box on the operator configuration screen. Because the group-by columns are stored as strings, reducing the size of each value in the group by column might increase this limit.
Wide data: The operator is very performant on long data, but performance might slow down dramatically if aggregations are calculated on thousands of columns. Increasing Spark's executor memory might improve performance.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Group By | Columns by which to group the data. |
| Find Maximum | Maximum value for each of these columns for each group. |
| Find Minimum | Minimum value for each of these columns for each group. |
| Calculate Sum | Sum for each of these columns for each group. |
| Calculate Mean | Mean value for each of these columns for each group. |
| Calculate Variance | Variance for each of these columns for each group. See Aggregation Methods for Batch Aggregation for implementation and performance details. |
| Calculate Standard Deviation | Standard deviation for each of these columns for each group. See Aggregation Methods for Batch Aggregation for implementation and performance details. |
| Calculate Number of Distinct (slower) | Number of distinct values (excluding null values) for each of these columns for each group. See Aggregation Methods for Batch Aggregation for implementation and performance details. |
| Calculate Median (slower) | Median for each of these columns for each group. See Aggregation Methods for Batch Aggregation for implementation and performance details. |
| Use Approximate Median | Specify whether to use approximate median - Yes or No (the default). |
| Column Name Format | Indicates whether the aggregation type is added to the beginning or the end of the column name in the output.
Default value: suffix. For example, a column that calculates the mean for a set of ages would be titled 'age_mean'. |
| Write Rows Removed Due to Null Data To File | Rows with null values are removed from the analysis. This parameter allows you to specify that the data with null values is written to a file.
The file is written to the same directory as the rest of the output. The filename is suffixed with _baddata.
|
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
Output
- Visual Output
-
The operator returns visual output with three tabs: Output, Parameters, and Summary.
Output - A preview of the data output (see the Data Output section).
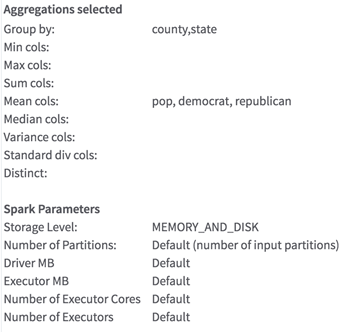
Parameters - A list of the parameters that were selected, as shown in the following example.
Summary - A summary of the number of rows removed due to null data and a message about where the results were stored.
- Data Output
-
A wide data set that can be accepted by any Team Studio operator that accepts HDFS data as input. Each of the group by columns is in the output. The group_size column shows the number of non-null values in that group. For each aggregation type, there is a column for each input column selected.
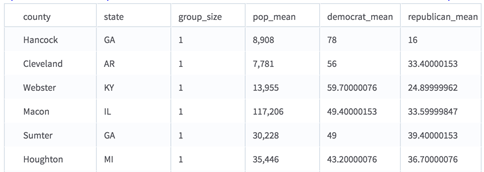
Suppose that we had used a data set about election data across counties and states, selecting the "suffix" option and the aggregations shown above. Our new data set would have the following structure:
As you can see, each of the aggregation columns is named with the original column name + underscore + a suffix that describes the type of aggregation performed. If we had used the "prefix" option, the aggregation would come first; for example, "max_pop". See the Available Aggregation Methods table above for the exact abbreviations used for each aggregation. The columns are ordered by aggregation and then by input column, thus all the mean columns are grouped together, and so on. The aggregations are listed in the same order as the parameters and are computed after the rows with null values are removed.
As this example demonstrates, the groups are not in alphabetically sorted order. To order the aggregations, connect this operator to a sorting operator.
- Data Output
- A data set that contains the aggregated values as specified.