Collapse
Transforms the data contained in a column of a table by means of subtotals (or other calculations) that are defined by another column in the same list. The other calculations might be averages and counts. The result is a collapsed or condensed data set.
- Algorithm
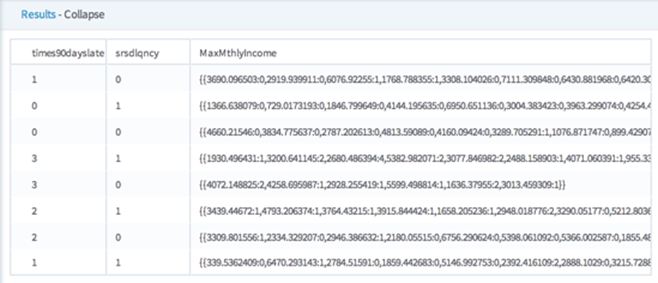
- For typical data entry and storage, data usually appears in flat tables, meaning that it consists of only columns and rows. While such data can contain a lot of information, it can be difficult to get summarized information. A collapsed table can help quickly summarize the flat data, giving it depth and highlighting the desired information by combining data from multiple rows into one row. The output format for a collapsed column is "sparse."
For example, see the following data set.
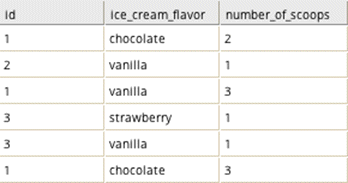
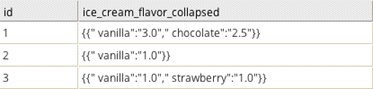
To determine the average number of scoops per flavor a customer orders, group by id, and aggregate "average" with the aggregation column number_of_scoops. The resulting data set is shown below.
To just determine how many times a customer ordered each flavor, group by id and aggregate "count" (no aggregation column is necessary). The resulting data set is shown below.
This is similar to the Pivot operator, except that the end results are stored in one column instead of pivoted out to (n-1) columns, where n is the number of categorical values in the pivot/collapse column.

Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Columns to Collapse | Define the rules for collapsing columns. |
| Group By | Select the columns to group. |
| Store Results? | Specifies whether to store the results. |
| Results Location | The HDFS directory where the results of the operator are stored. This is the main directory, the subdirectory of which is specified in Results Name. Click Choose File to open the Hadoop File Explorer Dialog Box and browse to the storage location. Do not edit the text directly. |
| Results Name | The name of the file in which to store the results. |
| Overwrite | Specifies whether to delete existing data at that path and file name. |
| Compression | Select the type of compression for the output.
Available Avro compression options are the following. |
| Use Spark | If Yes (the default), uses Spark to optimize calculation time. |
| Advanced Spark Settings Automatic Optimization |
|