Fuzzy Join
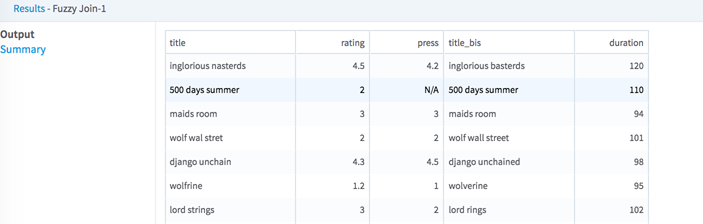
Performs a fuzzy matching join to connect two data sets based on nearly matching string values.

Input
Exactly two HDFS tabular inputs.
- Bad or Missing Values
-
If the output contains empty strings in the first column, these empty strings are converted to a double quote instead (and are not detected as empty strings by subsequent operators).
This issue is due to a bug in spark-csv for Spark version 1.6.1, where the CSV writer always quotes empty strings if they are first in a row (see https://issues.apache.org/jira/browse/CSV-63 for details). To work around it, replace all empty strings/null values in the first column in the Fuzzy Join output before you run it.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Left data set
*required |
The left data set input for the join. |
| Join On Column
*required |
The joining column from the Left data set. This column must be categorical (chararray). |
| Columns To Keep | The columns to keep from the Left data set. |
| Right data set | The right data set input for the join. |
| Join On Column
*required |
The joining column from the Right data set. This column must be categorical (chararray). |
| Columns to Keep | The columns to keep from the Right data set. |
| Join Type
*required |
The join type. |
| Pre-Precessing on Columns to Match | Select zero or more text pre-processing options to apply to the two
Join On columns selected before executing the fuzzy join.
|
| Custom Stop Words File | If the
Clear Stop Words option is selected in
Pre-Processing on Columns to Match and this box is left blank, a standard set of stop words is used. You can find this list
here.
Otherwise, choose a file that contains a list of the stop words. This list must be one word per line and should be small enough to fit in memory. |
| Stemmer Algorithm | Define the stemming algorithm to use if the
Stem Words option is selected in
Pre-Processing on Columns to Match.
If you use a language other than English, you must add a custom stop word file. |
| Match Threshold (%)
*required |
Select the minimum match threshold (inclusive) between the (pre-processed or not) two strings so that they are considered a match. It must be a Double in [0,100].
The match threshold between strings A and B is computed using the formula: 100.0 - (100 * Damerau-Levenshtein distance (A, B) / max_length(A, B)). If both values A and B are null or empty (that is, if max_length(A, B) = 0), the match score is 100. Thus, they are considered a match. For details, see Wikipedia: Damerau-Levenshtein distance. |
| Suffix for Duplicate Columns in Right data set
*required |
If some columns to keep from left and right data sets have the same name, this suffix is appended (preceded by an underscore) to the output columns of the right data set. |
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|