Reorder Columns (HD)
Reorders one or more columns from an input table, and optionally renames them.

Information at a Glance
Note: The Reorder Columns (HD) operator is for Hadoop data only. For database data, use the
Reorder Columns (DB) operator.
Configuration
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Ordered Columns | Click Define to specify the columns (in order) to become the first columns in the output, and optionally specify a new name for each. See Ordered Columns Dialog Box for more information. |
| Columns to Keep | Specify any other columns to keep in the output. |
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
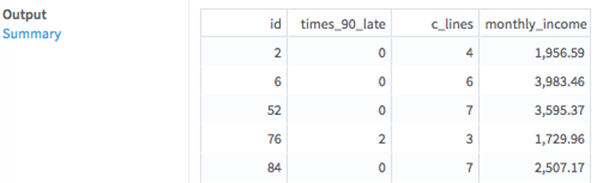
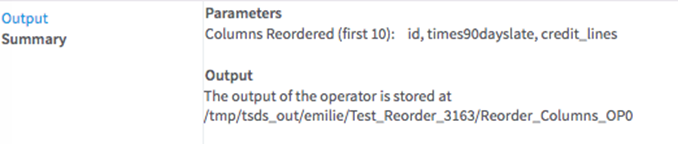
Related reference
Copyright © Cloud Software Group, Inc. All rights reserved.