Replace Outliers (DB)
Reduces the range of values for numeric columns.

Information at a Glance
For more information about how the Replace Outliers operator works, see Outliers in Numerical Data.
Note: The Replace Outliers (DB) operator is for database data only. For Hadoop data, use the
Replace Outliers (HD) operator.
Input
This operator works for tabular data sets. The transformation function can be applied only to numeric columns, and the type of the numeric input columns is preserved in the output.
- Bad or Missing Values
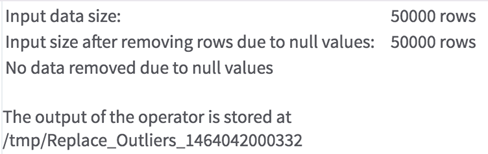
- Any row that contains dirty data, such as a string in a numeric column, is removed as the data is read in. After the data is read in, the operator filters out all rows that contain null values in the selected numeric columns. Rows that have null values in any of the columns not selected are not removed. The rows removed are reported in the Summary tab. If the value of Write Null Data to File Parameter is set to yes, then the rows removed because they have null data are written to an external file (the location of which is reported in the Summary tab).
Restrictions
Any data set with numeric columns can be used. This operator slows down as the number of columns selected and the cardinality of the columns increases.
Configuration
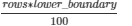 .
.
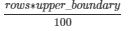 .
.
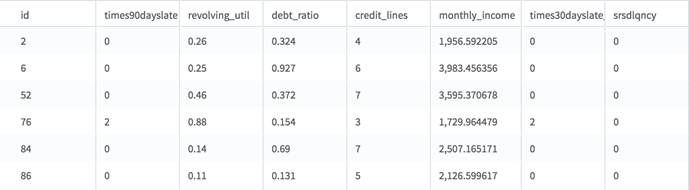
Output
- Visual Output
- The operator has two tabs of output. The first is the output data, which is passed on to the next operator. The second is a summary that explains which parameters were selected, how much null data was removed, and where the results were written.
- Data Output
- The operator outputs the same tabular data set as the input data, but with some of the values in the selected numeric columns replaced. See Outliers in Numerical Data for more information.
Related reference
Copyright © Cloud Software Group, Inc. All rights reserved.