Unpivot (HD)
Unpivots one or more columns.

Information at a Glance
Note: The Unpivot (HD) operator is for Hadoop data only. For database data, use the
Unpivot (DB) operator.
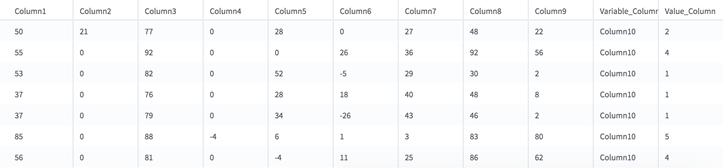
The columns selected are removed from the input and flattened into the following two new columns at the end of the output data set.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Columns | The columns to unpivot. All data types are supported. |
| Name of Variable Column | The name of the first new column. This contains the names of the columns to unpivot. |
| Name of Value Column | The name of the second new column. This contains the values of the columns to unpivot. |
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
Output
If you select X columns to unpivot from an input with Y columns and N rows, the output data set has (Y-X+2) columns and (X * N) rows.
Related reference
Copyright © Cloud Software Group, Inc. All rights reserved.