Distinct (HD)
Returns the unique value combinations across selected columns.

Information at a Glance
Removing duplicate records is often a required step before data analysis and modeling can begin. Any record with the same values for the field (or selected fields) is considered a duplicate, and the Distinct operator can be used to remove these entries.
An example use case might be applied to a marketing database in which an individual's data appears several times with different addresses or company information.
Input
A Hadoop data set from the preceding operator.
- Bad or Missing Values
- This operator handles null values by eliminating them from the input calculation. To prevent this behavior, use the Null Value Replacement operator on the initial training data to replace bad or missing values.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Column Names in Order | Specify the column or columns to use as the unique value combination criteria. At least one column must be selected. |
| Store Results? | Specifies whether to store the results. |
| Results Location | The HDFS directory where the results of the operator are stored. This is the main directory, the subdirectory of which is specified in Results Name. Click Choose File to open the Hadoop File Explorer Dialog Box and browse to the storage location. Do not edit the text directly. |
| Results Name | The name of the file in which to store the results. |
| Overwrite | Specifies whether to delete existing data at that path and file name. |
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Use Spark | If Yes (the default), uses Spark to optimize calculation time. |
| Advanced Spark Settings Automatic Optimization |
|
Output
- Visual Output
-
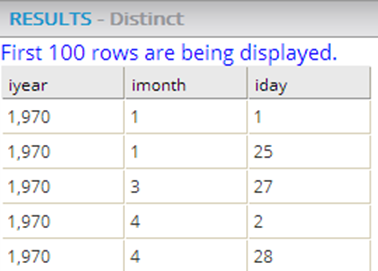
The data rows of the output table or view displayed (up to 100 rows of the data).
In the following example, three columns (iyear, imonth, and iday) were selected as the distinct criteria. Each results row has a unique combination of values for the three data columns.
- Data Output
- The data set of the distinct data table.