Data Format
The Data Format shared resource contains the specification for parsing or rendering a text string using the Parse Data and Render Data activities. This resource specifies the type of formatting for the text (delimited columns or fixed-width columns), the column separator for delimited columns, the line separator, the fill character, and field offsets for fixed-width for fixed-width columns.
You must also specify the data schema to use for parsing or rendering the text. When parsing text, each column of an input line is transformed into the corresponding item in the specified data schema. The first column of the text line is turned into the first item in the data schema, the second column is transformed into the second item, and so on. Each line is treated as a record, and multiple lines result in a repeating data schema containing the lines of the input text string. The following figure illustrates how an input text string is parsed into a specified data schema.
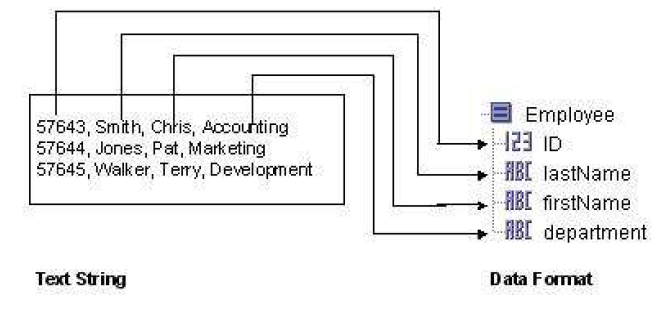
When rendering text, each record in the input data schema is transformed into a line of output text. The first item of the data schema is transformed into the first column of the text line in the output text string. Rendering a data schema into a text string is exactly the opposite process of parsing a text string into a data schema.
Data Format Editor
This editor contains General, Data Format Configuration, Data Format Editor, and Field Offsets sections.
Data Format Configuration
| Field | Description |
|---|---|
| Format Type | The Type of formatting for the text. The text can be either
Delimiter separated or
Fixed format.
When you select the Delimiter separated option, the text in each column is separated by a delimiter character, specified in the Col Separator field. Each line is separated by the character specified in the Line Separator field. When you select the Fixed format option, the text in each column occupies a fixed position on the line. For fixed format text, you must specify the fill character, the line length, and the column offsets. |
| Col Separator | This field specifies one or more separator characters between columns when
Delimiter separated option is specified in the
Format Type field.
When rendering text, each element in the input data schema is separated by the column separator in the output text string. If more than one character is specified in this field, the Render Data activity places the entire string specified in this field between each column. For example, if ":;" is specified in this field, then ":;" displays between each column in the rendered string. When parsing text, each column becomes an element in the output data schema. If more than one character is specified in this field, the Parse Data activity uses the rules specified in the Col Separator Parse Rule field to determine how to parse the data. This field supports the Module property. |
| Col Separator Parse Rule | Specifies the rule to use for multiple column separator characters when parsing data. The choices are the following:
|
| Line Separator | Specifies the character(s) that determine the end of each line. Available Line Separator characters are:
When parsing text each line is treated as a new record in the output data schema. When rendering text, each data record is separated by the line separator character in the output text string. The last line in your input file must be terminated by the specified line separator. |
| Fill Character | When processing fixed format columns, this is the type of character that is used to fill the empty space in a column and between columns. This field is only available when you select the
Fixed format option in the
Format Type field. The fill character is used only by the
Render Data activity.
You can select any one from the following available options:
For example, you have a column that holds an integer and the specified width is 10. One row has the value "588" for that column. Because the width of 588 is three and the column width is 10, the remaining 7 characters are filled with the specified fill character. |
Data Format Editor
You can define a custom schema for the text in the Data Format Editor panel. You can define your own datatype here. After defining the data type, the data specified here is used to parse a text string into the specified schema or render the specified schema as a text string. The Header element contains the following:
Field Offsets
When processing fixed format text, you must specify the line length and the column offsets. This enables the Parse Data or Render Data activity to determine where columns and lines begin and end. You can specify the format of fixed-width text using the Field Offsets.
The line length is the total length of input lines, including the line separator characters. Include the appropriate number of characters for the selected line separator in the Data Format Configuration to the total length of each line.
The column offset is the starting and ending character position on each line for the column. Each line starts at zero (0). For each column of the line, you must specify the name of the data item associated with this column (this is the same name you specified for the corresponding elements in the data schema), the starting offset for the column, and the ending offset for the column.
Each column offset can begin where the last column offset ended. Many fixed format data files are used by databases or are generated by automated processes. These files have rigid file record formats and may not have additional padding space between the columns. When you define each column offset to begin where the last column offset ends, you can read the data more quickly. This is because you can read sequentially the bytes of the input records.
Consider the following text file. The first two lines of the file indicate offset numbers (each 0 indicates another 10 characters), and the fill character between columns is spaces:
0 12 30 45 01234567890123456789012345678901234567890123456789012345678 57643 Smith Chris Account 57644 Jones Pat Marketing 57645 Walker Terry Development
Delimiter Separated Fields
When processing delimiter-separated text, each field in the input line is separated by the delimiter specified by the Column Separator field. Leading and trailing spaces are stripped from each field and the specified Line Separator determines when a new record starts.
In some situations, you may not be able to choose a column separator character that does not display in any column data. For example, if you choose a comma as the column separator, there may be commas in some of the column values. To process data that contains column separator characters in a column, you can surround the column with double quotes (" "). You can also use double quote to include leading and trailing spaces as well as line breaks in a field. If you want to display a double quote in a field, escape the double quote by using two consecutive double quotes. That is, use "" to represent a double quote in a field.
The following data illustrates input lines with each field separated by commas. some fields, however, contain commas, leading or trailing spaces, double quotes, and line breaks.
57643, Smith, "Chris", Accounting , "State: Be prepared!"
57644, Jones, "Pat ", Marketing , "Statement: To paraphrase JFK, ""Ask not what your company can do for you, ask what you can do for your company.""
57645, Walker, "Terry", Development, "Statement: May goal si to be CEO someday."
Notice that Pat Jones' statement spans two lines and contains double quotes as well as a comma. The entire field is surrounded by double quotes, so it is still treated as part of the same record.