PCA (DB)
Uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of uncorrelated variables (principal components).

Algorithm
PCA (Principal Component Analysis) is an orthogonal linear transformation that transforms data into a new coordinate system such that the greatest variance by any projection of the data comes to lie on the first coordinate (called the first principal component), the second greatest variance on the second coordinate, the third on the third coordinate, continuing until the number of rows has been reached or a preset maximum principal component threshold has been reached.
The Alpine PCA operator implements an eigenvalue decomposition of a data covariance matrix Σ (or, correlation matrix R).
- Each principal component is a linear combination of the original variables.
- The coefficients (loadings) are the eigenvectors (v1, v2,...vp) of covariance matrix Σ (or, correlation matrix R) with unit length.
- The eigenvalues (λ1, λ2,...λp) denote the contribution of the principal component associated with it.
- The principal components are sorted by descending order according to their variance contribution.
- The user can choose the number of principal components according to the accumulation contribution (∑ij=1λj/∑pK=1λK).
More details are available in Principal Component Analysis, (1986), Joliffe, I.T.
- Jerome Friedman, Trevor Hastie, Robert Tibshirani (2008), The Elements of Statistical Learning Data Mining, Inference and Prediction Chapter 3: "Linear Methods for Regression"
- Joliffe, I.T. (1986), Principal Component Analysis, New York, Springer
- Wu, W., Massart, D.L., and de Jong, S. (1997), "The Kernel PCA Algorithms for Wide Data. Part I: Theory and Algorithms" Chemometrics and Intelligent Laboratory Systems, 36, 165-172.
Configuration
Output
- Visual Output
-
- Results Table
-
Provides the eigenvalues used in the matrix transformation.
- Initial variable columns: The initial variable columns passed into the PCA operator are displayed, along with a magnitude value for that variable's contribution to the eigenvector transformation into each derived principal component.
- alpine_pcadataindex: Eigenvector index number that provides a unique number for each derived principal component.
- alpine_pcaevalue: Eigenvalue for that principal component.
- alpine_pcacumvl: The fraction of the variability that this eigenvector explains for the principal component defined.
- alpine_pcatotalcumvl: The cumulative fraction of the variability that this eigenvector explains for the principal component defined.

- Output Table
-
Provides an overview of the new reduced Principal Components data set.
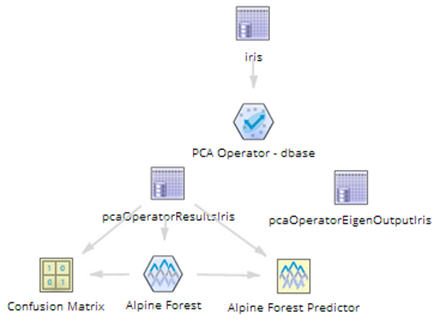
alpine_pcaattr[0-13]+: Each of the newly derived Principal Components columns is provided, along with their values for the new transformed data set. In this case, the source Iris data set with hundreds of variables was reduced to only 13 principal components variables and saved as pcaOperatorResultsIris. (See the example flow below.)
Carryover columns: any carryover columns from the original data set that were specified in the PCA operator configuration are displayed here, such as any necessary unique ID key or the dependent variable to predict in a following model. In this example, the "class" column was carried over to be used in a following Alpine Forest model.

- Data Output
- Stored database tables that can be accessed by other operators.
The PCA operator for the database is technically a terminal operator, meaning that no other operator directly follows it in the workflow. However, the PCA operator stores its Principal Component Results (and Eigenvalue Output details) in two database tables that can then be accessed as the data source for a new workflow, if applicable. The example below shows the results of the database PCA operator being saved as pcaOperatorResultsIris and pcaOperatoreEigenOutputIris. The tables can be brought into the workflow and the derived Principal Components can be fed into an Alpine Forest operator, for example, and the classification results analyzed in the Confusion Matrix in order to understand if the reduced set of variables that the PCA operator created provide an accurate enough model.