Neural Network
Implements the Spark MLlib MultiLayer Perceptron Classifier (MLPC), a feedforward neural network that consists of multiple layers of nodes in a directed graph, each layer fully connected to the next one in the network.

Information at a Glance
The Neural Network operator can be exported and used in other workflows in the same workspace.
Nodes in the input layer represent the input features. All other nodes map inputs to outputs using a linear combination of the inputs, with the node's weights (w) and bias (b). The nodes apply a nonlinear activation function depending on their types of layers: sigmoidfunction for nodes in hidden layers; softmaxfunction for nodes in the output layer.
The output layer represents the classes to predict. For learning, the model the output layer uses the backpropagation function.
Because the MLPC requires continuous features as input nodes, categorical features can be used as predictors by first applying One-Hot Encoding (converting categorical columns to columns of binary vectors with a most a single 1-value).
For more information about the MLPC, see https://spark.apache.org/docs/1.6.1/ml-classification-regression.html#multilayer-perceptron-classifier and https://en.wikipedia.org/wiki/Multilayer_perceptron.
Input
An HDFS data set input, including predictor columns and a dependent column to predict.
- Bad or Missing Values
- If a row contains a null value in at least one of the independent columns or the dependent column, the row is removed from the data set. The number of null values removed can be listed in the Summary section of the output (depending on the chosen option for Write Rows Removed Due to Null Data To File).
Restrictions
If the model is exported using the Export operator to the Team Studio Model format, then this model can be loaded in other workflows in the current workspace using the Load Model operator. Scoring HDFS inputs is supported, but the model is not SQL compatible and does not score against a relational database connection.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Dependent Column | A dependent column that contains the label to predict. This column can be categorical or numeric (each number is considered as a distinct label). |
| Columns | The columns to use as independent features to train the model. Both numeric and categorical are supported. |
| Hidden Layers (Comma-Separated) | The number of hidden layers and number of neurons associated with each layer using an integer comma-separated list. (for example, "6,3" means two hidden layers with six and three neurons respectively).
If the default value (-1) is used, the algorithm automatically sets one hidden layer. number of neurons = (nb_neurons_input_layer + nb_neurons_output_layer ) / 2. |
| Maximum Iterations |
The maximum number of iterations.
Default value: 100. |
| Tolerance |
The convergence tolerance of iterations. Smaller values lead to higher accuracy at the cost of more iterations.
Default value: 10E-4. |
| Random Seed | The random seed to use to initialize the weights of the Neural Network. Range: -10000 < seed < 10000. Default value: -1 (random initialization). |
| Compute Classification Metrics on Training Set | Yes (the default) - performance metrics of the model on the input are displayed in the output Tab Training Metrics. The model accuracy is provided as well as for each label to predict, the associated recall, precision, and F1 measure. |
| Write Rows Removed Due to Null Data To File | Rows with null values in at least one of the independent columns or the dependent column are removed from the analysis. Use this parameter to specify that the data with null values be written to a file.
The file is written to @default_tempdir/tsds_out/@user_name/@flow_name/@operator_name_uuid/bad_data
|
| Advanced Spark Settings Automatic Optimization |
|
Output
- Visual Output
- A visual output with three tabs -
Summary,
Training Metrics, and
Neural Network Weights.
Summary:
Training Metrics (This tab is displayed only if the option Compute Classification Metrics on Training Set was set to Yes):
-
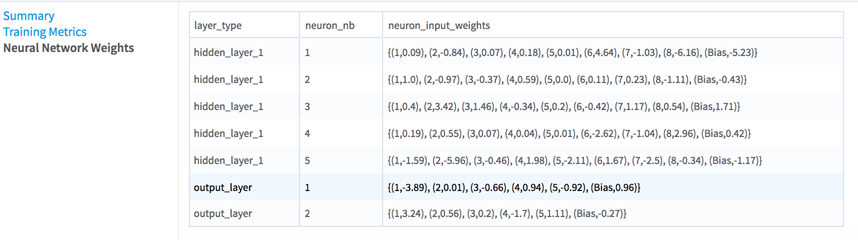
Neural Network Weights
This table provides the final input weights of each neuron of the network. The neuron_input_weights column is shows a list of all neurons connected to the neuron neuron_nb of the layer layer_type, with their associated weight (for example, (1, 0,09) means a weight of 0.09 associated with neuron 1 of the previous layer).
- Data Output
- A neural network model than can be used for classifying new input data using the Classifier or Predictor operator. Alternatively, it can be connected to classification evaluation operators such as Confusion Matrix, ROC, and Goodness of Fit. It can be exported using the Export operator (to be reused in other workflows in the current workspace).


Additional Notes
To improve Neural Network performance, try the following.
- Scale and normalize your input features before training the model to equally distribute the importance of each input and avoid saturating the hidden layers (otherwise the naturally large values become dominant). This also helps the algorithm to converge faster.
- If your training data set is very imbalanced (that is, one label is much more represented than another), resample it so all classes are well represented (you can use the Resampling operator). This is likely to improve your model accuracy.