Collaborative Filter Trainer
Collaborative filtering is used commonly for recommender systems. Given input data for users, products, and ratings, the Collaborative Filtering Trainer uses an alternating least squares (ALS) method, in which users and products are described by a small set of latent factors that can be used to predict unknown or empty entries in the sparse matrix.
Input
An HDFS tabular data set with at least three columns. There should be one column each to represent people, products, and ratings.
Restrictions
Using a high value for Additional Parameters to Try impacts performance because the ALS algorithm must be run many times. See the parameters list for details.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Users Column | Select the column that has information about the users in your data set. |
| Products Column | Select the column that has information about the products in your data set. |
| Ratings Column | Select the column that has information about the ratings in your data set. |
| Number of Latent Factors (Rank) | The parameter for the MLlib model. This represents the number of latent factors to train the model on. Must be between 3 and 100.
Range: 3-100 (inclusive). Default value: 5. |
| Number of Iterations | The parameter that is passed to the MLlib ALS model. It represents the number of iterations to be used for each run of ALS.
If in the Vary Parameters and Pick Model with Lowest Error parameter you select to train more than one model, the value of this parameter is the first one selected and the next values are chosen randomly using this number as a seed. Range: 1-20 (inclusive). Default value: 10. |
| Regularization Parameter (λ) per Model | The parameter that is passed to the MLlib model to use as a scalar when training ALS to prevent overfitting the data.
Range: 0.0-1.0 (exclusive). Default value: 0.01. |
| Vary Parameters and Pick Model with Lowest Error (slower) |
In the output, we show the parameters used to train each pass of the ALS Algorithm and the Root Mean Squared Error associated with each. |
| Number of Additional Parameters to Try | Number of random values to try for each of the model parameters (Rank, Number of Iterators, Lambda). We run the MLlib ALS algorithm for each combination of the original parameter values and the randomly chosen one.
Note: The higher this value is, the more expensive the computation. This can take a very long time for higher values. For example, if you entered 5, for each of the three parameters (Rank, Number of Iterators, Lambda), we look at six values (the value you input + five randomly chosen ones). We run the ALS algorithm in this case 3^6, or 243, times. For each of those runs, we also compute the RMSE. This requires a shuffle of the data on the Spark side, further impacting performance. Choose a value for this parameter wisely.
Range: 0-20 (inclusive). Default value: 0. |
| Output Directory | The location to store the output files. |
| Advanced Spark Settings Automatic Optimization |
|
Outputs
- Visual Output
-
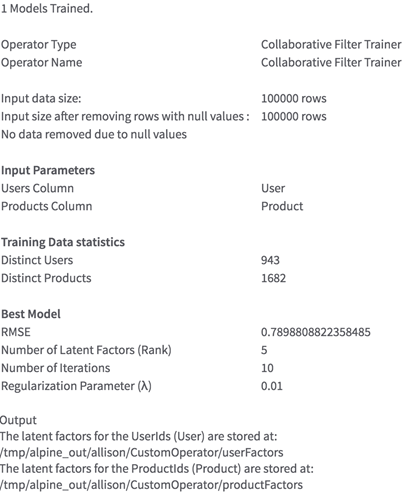
A table that shows the parameters chosen and the Root Mean Squared Error. If there are multiple models trained during this process (if you selected Vary Parameters and Pick Model with Lowest Error), the other models are shown here.

-
A Summary that describes the output location of the results and the number of rows processed, as well as the number of distinct users and products.
- Data Output
- The latent factors for the user IDs and for the product IDs are stored on HDFS and sent to the next operator. Use this operator along with a Collaborative Filter Recommender or Predictor to create recommendations.