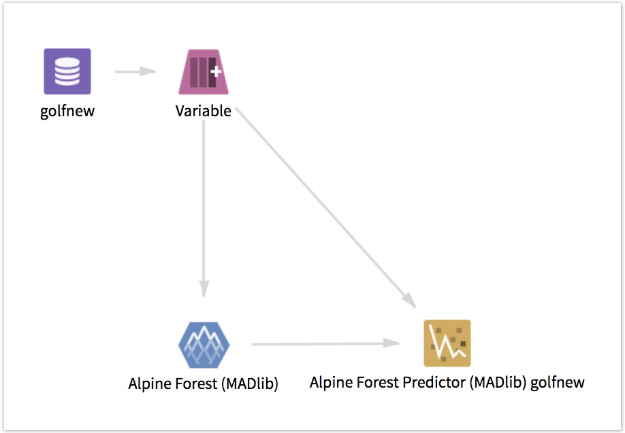
Alpine Forest - MADlib
Uses the MADlib built-in function, forest_train(), to generate multiple decision trees, the combination of which is used to make a prediction based on several independent columns.

Information at a Glance
Each decision tree is generated based on bootstrapped sampling and a random subset of the feature columns. The destination of the output of this operator must be an Alpine Forest Predictor (MADlib) operator. MADlib 1.8 or higher must be installed on the database. For more information, see the official MADlib documentation.
Input
The input table must have a single, categorical (string or integer) or regression (floating point) column to predict, and one or more independent columns to serve as input.
Restrictions
This operator works only on databases with MADlib 1.8+ installed. Source data tables must have a numeric ID column that uniquely identifies each row in the source table. The prediction column must be integer or string for classification trees, or floating point for regression trees.
Configuration
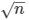 for classification trees or
for classification trees or
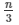 for regression trees, where
n is the maximum number of trees.
for regression trees, where
n is the maximum number of trees.
Output
- Visual Output
-
This operator has three sets of output tabs.
- The first set of tabs contains a text representation of each of the generated decision trees.
- The second tab contains DOT notation of each of the generated decision trees. DOT notation can be exported to third-party tools such as GraphViz.
- The third tab contains the raw output tables generated by MADlib.
- The first is the model output table. The gid column represents the group ID. Grouping is not supported at this time, so this value is always 1. The sample_id represents the tree ID. The tree column encodes each generated decision tree in binary format.
- The second is the output summary table, which contains information about how the trees were generated. Many parameters passed to the MADlib training function appear here as columns.
- The third tab is the grouping table, which contains one row for each set of values by which we are grouping. Because grouping is not supported, it has only one row.
- Data Output
- The output of this operator must be sent to an Alpine Forest Predictor operator.