Selecting a Storage Mode
To copy columns from a source table to a publishing table, you can use the Storage Mode field in the Publication Options tab to select a storage mode. Publication Service provides two storage modes, Publish by Value and Publish by Reference. The selection depends on your specific requirements.
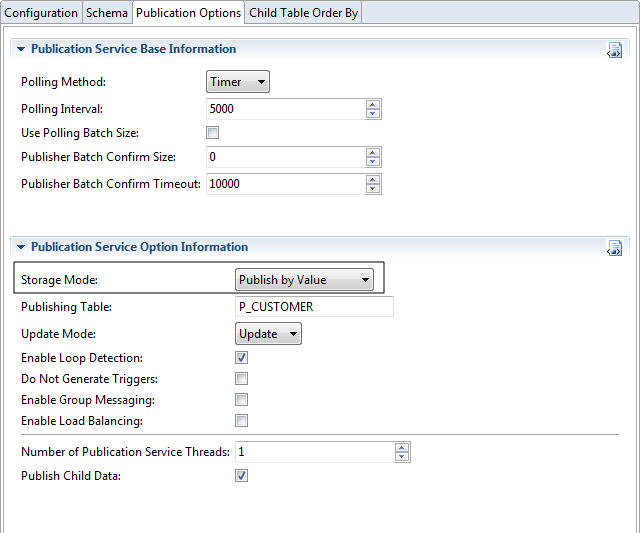
Publish by Value
With the Publish by Value storage mode, all specified columns in a source table are copied to the publishing table. Publish by Value makes for a fast copy, but does not support some data types, such as Oracle LONG and LONG RAW.
- Publishing tables cannot contain columns with the LONG data type. If a source table contains a column with the LONG data type, this column cannot be copied to the publishing table. This is because the trigger generated by the palette cannot copy the LONG column value through the
:new construct.
This is an Oracle restriction documented in the Oracle SQL Reference manual. The problem is not detected by Oracle during trigger creation. However, when the trigger fires and attempts to copy the LONG column value to the publishing table, the database connection will hang for some time and then eventually terminate.
- When you define parent-child relationships between tables, the publishing table that is created for a parent table cannot contain a column with the LONG data type. However, a child table can contain a column with the LONG data type. This is because data in child table rows is not copied using the :new construct.
- The LONG RAW data is not supported in the publishing table.
These restrictions do not apply to publishing tables when you use the Publish by Reference storage mode, and LONG and LONG RAW are non-key types.
An example of Publish by Value is as follows:
A publishing table named P_CUSTOMER is created for the source table, CUSTOMER. When the CUSTOMER table is updated, the new data is copied to the P_CUSTOMER table. The adapter polls the P_CUSTOMER table and publishes the new data.
The following figure shows the Publish by Value storage mode.
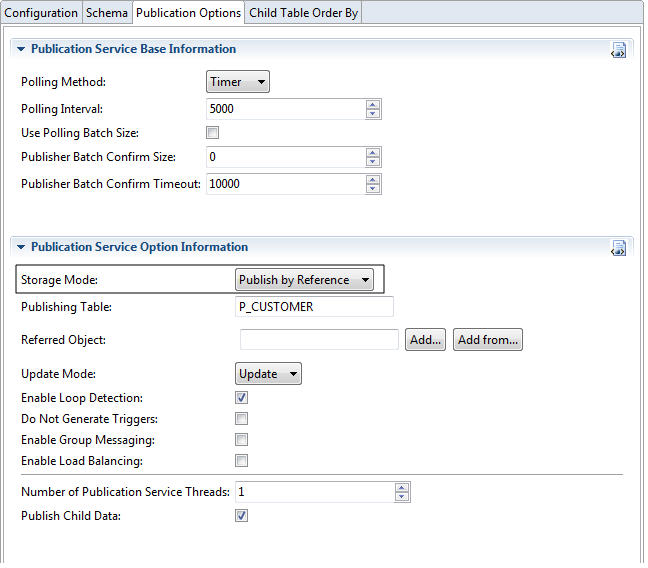
Publish by Reference
With the Publish by Reference storage mode, only key column values are copied to the publishing table. By using this feature, Publication Service can publish data directly from the source table without copying the data from the source table to the publishing table first. A trigger, a stored procedure, and a publishing table are created, but the publishing table contains the necessary adapter fields and only the key fields of the source table.
The advantage of Publish by Reference is that the data to be published is stored just once. Also, data types, such as Oracle LONG and LONG RAW are supported for Publish by Reference.
A key column or substitute key column is required when you use Publish by Reference, because the publishing table contains only key values. If no column is specified, the publication is not added.
An example of Publish by Reference is as follows:
A publisher endpoint is configured to publish from the P_CUSTOMER table with the CUST_ID key field. The publishing table is created with the necessary fields and the CUST_ID field. When a row in the P_CUSTOMER table is modified, the trigger fires, populates fields, and copies the CUST_ID field value to the publishing table. When the adapter polls the publishing table, it detects the new row and selects it from the P_CUSTOMER table by using the CUST_ID field value found in the publishing table. Then the message is published.
The following figure shows the Publish by Reference storage mode.
Publish by Reference Object
To use a view or a different database object as the source table, you can configure the adapter to publish data by a reference object, where key columns are stored in the publishing table and data to be published is selected from the referred object.
Similar to the Publish by Reference feature, Publish by Reference Object copies only key values from the source table to the publishing table.
The difference is that, if Publish by Reference Object is used, when a row changes in the source table and the associated trigger fires, the adapter fetches data from the referred object instead of the source table. The name of the referred object is stored in the ADB_REF_OBJECT column in the publishing table. It is good practice to use Publish by Reference Object when a view provides the most efficient access to the source data, for example, when many levels of nesting exist between a parent table and a child table.
- No matter if a single table or parent-child tables are used as a source table, even if you do not specify a referred object, the adapter can run properly without additional configurations for Publication Service.
- A referred object can be a table or a view in the default schema. However, if you add a prefix in the referred object name, the table or view in the schema with the specified prefix is used for reference.
- If you specify a table or view as a referred object, the referred object must contain columns with the same names and data types as the primary key columns in the source table. The primary key values in the source table must be the same as the primary key values or the subset of primary key values in the referred object.
For details on how to use Publish by Reference Object, see Using Publish by Reference Object.