SANN Overviews - Activation Functions
As mentioned before, a multilayer perceptron (MLP) is a feedforward neural network architecture with unidirectional full connections between successive layers. However, this does not uniquely determine the property of a network. In addition to network architectures, the neurons of a network have activation functions that transform the incoming signals from the neurons of the previous layer using a mathematical function. The type of this function is the activation function itself and can profoundly influence the performance of the network. Thus, it is important to choose a type of activation function for the neurons of a neural network.
The input neurons usually have no activation function. In other words, they use the identity function, which means that the input signals are not transformed at all. Instead they are combined in a weighted sum (weighted by the input-hidden layer weights) and passed on to the neurons in the layer above (usually called the hidden layer). For an MLP with two layers (MLP2) it is recommended that you use the tanh (hyperbolic) function although other types are also possible such as the logistic sigmoid and exponential functions. The output neuron activation functions are, for most cases, set to the identity but this may vary from task to task. For example, in classification tasks they are set to softmax (Bishop 1995) while for regression problems they are set to identity (together with the choice of tanh for the hidden neurons).
The set of neuron activation functions for the hidden and output neurons available in STATISTICA Automatic Neural Networks is given in the table below:
| Function | Definition | Description | Range |
| Identity | The activation of the neuron is passed on directly as the output | ||
| Logistic sigmoid | An S-shaped curve | ||
| Hyperbolic tangent | A sigmoid curve similar to the logistic function. Often performs better than the logistic function because of its symmetry. Ideal for multilayer perceptrons, particularly the hidden layers | ||
| Exponential | The negative exponential function | ||
| Sine | Possibly useful if recognizing radially distributed data. Not used by default | ||
| Softmax | Mainly used for (but not restricted to) classification tasks. Useful for constructing neural networks with normalized multiple outputs which makes it particularly suitable for creating neural network classifiers with probabilistic outputs. | ||
| Gaussian | This type of isotropic Gaussian activation function is solely used by the hidden units of an RBF neural network which are also known as radial basis functions. The location (also known as prototype vectors) and spread parameters are equivalent to the input-hidden layer weights of an MLP neural network |
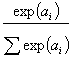
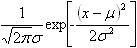
Where a is the net input of a neuron (for MLPs - weighted sum of neuron's inputs).
For the Gaussian: X represents the vector of neuron's inputs, mu - the vector of input weights (RBF center), sigma - the RBF's spread (width).