Noncentrality Interval Estimation and the Evaluation of Statistical Models - Advantages of Interval Estimation
Much research is exploratory. The fundamental questions in exploratory research are "What is our best guess for the size of the population effect?" and "How precisely have we determined the population effect size from our sample data?" Significance testing fails to answer these questions directly. Many a researcher, faced with an "overwhelming rejection" of a null hypothesis, cannot resist the temptation to report that it was "significant well beyond the .001 level." Yet it is widely agreed that a p-value following a significance test can be a poor vehicle for conveying what we have learned about the strength of population effects.
Confidence interval estimation provides a convenient alternative to significance testing in most situations. Consider the 2-tailed hypothesis of no difference between means. Recall first that the significance test rejects at the significance level if and only if the 1 - a confidence interval for the mean difference excludes the value zero. Thus the significance test can be performed with the confidence interval. Most undergraduate texts in behavioral statistics show how to compute such a confidence interval. The interval is exact under the assumptions of the standard t-test. However, the confidence interval contains information about experimental precision that is not available from the result of a significance test. Assuming we are reasonably confident about the metric of the data, it is much more informative to state a confidence interval on Mu1 - Mu2 than it is to give the p-value for the t-test of the hypothesis that Mu1 - Mu2 = 0 In summary, we might say that, in general, a confidence interval conveys more information, in a more naturally usable form, than a significance test.
This is seen most clearly when confidence intervals from several studies are graphed alongside one another, as in the figure below:
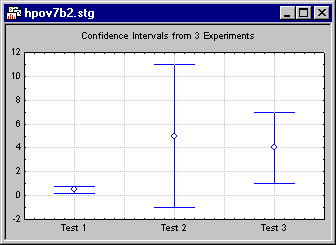
The figure shows confidence intervals for the difference between means for 3 experiments, all performed in the same domain, using measures with approximately the same variability. Experiments 1 and 3 yield a confidence interval that fails to include zero. For these experiments, the null hypothesis was rejected. The second experiment yields a confidence interval that includes zero, so the null hypothesis of no difference is not rejected. A significance testing approach would yield the impression that the second experiment did not agree with the first and the third.
The confidence intervals suggest a different interpretation, however. The first experiment had a very large sample size, and very high precision of measurement, reflected in a very narrow confidence interval. In this experiment, a small effect was found, and determined with such high precision that the null hypothesis of no difference could be rejected at a stringent significance level.
The second experiment clearly lacked precision, and this is reflected in the very wide confidence interval. Evidently, the sample size was too small. It may well be that the actual effect in conditions assessed in the second experiment was larger than that in the first experiment, but the experimental precision was simply inadequate to detect it.
The third experiment found an effect that was statistically significant, and perhaps substantially higher than the first experiment, although this is partly masked by the lower level of precision, reflected in a confidence interval that, though narrower than Experiment 2, is substantially wider than Experiment 1.
Suppose the 3 experiments involved testing groups for differences in IQ. In the final analysis, we may have had too much power in Experiment 1, as we are declaring "highly significant" a rather minuscule effect substantially less than a single IQ point. We had far too little power in Experiment 2. Experiment 3 seems about right.
Many of the arguments we have made on behalf of confidence intervals have been made by others as cogently as we have made them here. Yet, confidence intervals are seldom reported in the literature. Most important, as we demonstrate in the succeeding sections, there are several extremely useful confidence intervals that virtually never are reported. In what follows, we discuss why the intervals are seldom reported.