Multivariate Adaptive Regression Splines (MARSplines) Overview
The STATISTICA Multivariate Adaptive Regression Spines (MARSplines) module is a generalization of techniques popularized by Friedman (1991) for solving regression (see also, Multiple Regression) and classification type problems, with the purpose to predict the value of a set of dependent or outcome variables from a set of independent or predictor variables. MARSplines can handle both categorical and continuous variables (whether response or predictors). In the case of categorical responses, MARSplines will treat the problem as a classification problem. This is in contrast to the case of continuous dependent variables where the task is treated as a regression problem. MARSplines will automatically determine that for you.
MARSplines is a nonparametric procedure that makes no assumption about the underlying functional relationship between the dependent and independent variables. Instead, MARSplines constructs this relation from a set of coefficients and basis functions that are entirely "driven" from the data. In a sense, the method is based on the "divide and conquer" strategy, which partitions the input space into regions, each with its own regression or classification equation. This makes MARSplines particularly suitable for problems with higher input dimensions (i.e., with more than 2 variables), where the curse of dimensionality would likely create problems for other techniques.
The MARSplines technique has become particularly popular in the area of data mining because it does not assume or impose any particular type or class of relationship (e.g., linear, logistic, etc.) between the predictor variables and the dependent (outcome) variable of interest. Instead, useful models (i.e., models that yield accurate predictions) can be derived even in situations where the relationships between the predictors and the dependent variables is non-monotone and difficult to approximate with parametric models. For more information about this technique and how it compares to other methods for nonlinear regression (or regression trees), see Hastie, Tibshirani, and Friedman (2001) and Nisbet, R., Elder, J., & Miner, G. (2009).
Regression and Classification Problems
Regression problems are used to determine the relationship between a set of dependent variables (also called output, outcome, or response variables) and one or more independent variables (also known as input or predictor variables). The dependent variable is the one whose values you want to predict, based on the values of the independent (predictor) variables. For instance, one might be interested in the number of car accidents on the roads, which can be caused by 1) bad weather and 2) drunk driving. In this case, one might write, for example,
Number_of_Accidents = Some Constant + 0.5*Bad_Weather + 2.0*Drunk_Driving
The variable Number of Accidents is the dependent variable which is thought to be caused by (among other variables) Bad Weather and Drunk Driving (hence the name dependent variable). Note that the independent variables are multiplied by factors 0.5 and 2.0. These are known as regression coefficients. The larger these coefficients, the stronger the influence of the independent variables on the dependent variable. If the two predictors in this simple (fictitious) example were measured on the same scale (e.g., if the variables were standardized to a mean of 0.0 and standard deviation 1.0), then Drunk Driving could be inferred to contribute 4 times more to car accidents than Bad Weather. (If the variables are not measured on the same scale, then direct comparisons between these coefficients are not meaningful, and, usually, some other standardized measure of predictor "importance" is included in the results.)
For additional details regarding these types of statistical models, refer also to the Overviews for Multiple Regression and General Linear Models (GLM), as well as General Regression Models (GRM). In general, in the social and natural sciences, regression procedures are very widely used in research. Regression enables the researcher to ask (and hopefully answer) the general question "what is the best predictor of ..." For example, educational researchers might want to learn what are the best predictors of success in high school. Psychologists may want to determine which personality variable best predicts social adjustment. Sociologists may want to find out which of the multiple social indicators best predict whether a new immigrant group will adapt and be absorbed into society.
On the other hand, classification problems are concerned with predicting the value of discreet (categorical) response variables from a set of predictor variables. Classification is used to predict membership of cases or objects in the classes of a categorical dependent variable from their measurements on one or more predictor variables. Classification analysis is one of the main techniques used in data mining. The goal of classification is to predict or explain responses on a categorical dependent variable, and as such, the available techniques have much in common with the techniques used in the more traditional methods of Discriminant Analysis, Cluster Analysis, Nonparametric Statistics, and Nonlinear Estimation. Imagine that you want to devise a system for sorting a collection of coins into different classes (perhaps pennies, nickels, dimes, quarters). Suppose that there is a measurement on which the coins differ, say width, which can be used to devise a hierarchical system for sorting coins. You might roll the coins edge down on a narrow track in which a slot the width of a dime is cut. If the coin falls through the slot, it is classified as a dime; otherwise, it continues down the track to where a slot the width of a penny is cut. If the coin falls through the slot, it is classified as a penny; otherwise, it continues down the track to where a slot the width of a nickel is cut, and so on. You have just constructed a classification model. The decision process used by your classification model provides an efficient method for sorting a pile of coins and, more generally, can be applied to a wide variety of classification problems.
Multivariate Adaptive Regression Splines
The car accident example we considered previously is a typical application for linear regression, where the response variable is hypothesized to depend linearly on the predictor variables. Linear regression also falls into the category of so-called parametric methods, which assumes that the nature of the relationships (but not the specific parameters) between the dependent and independent variables is known a priori (e.g., is linear). By contrast, nonparametric methods (see also, Nonparametric Statistics) do not make any such assumption as to how the dependent variables are related to the predictors. Instead, it allows the model function to be "driven" directly from data.
Multivariate Adaptive Regression Spines (MARSplines) is a nonparametric procedure which makes no assumption about the underlying functional relationship between the dependent and independent variables. Instead, MARSplines constructs this relation from a set of coefficients and so-called basis functions that are entirely determined from the data. You can think of the general "mechanism" by which the MARSplines algorithm operates as multiple piecewise linear regression (see also, Nonlinear Estimation), where each breakpoint (estimated from the data) defines the "region of application" for a particular (very simple) linear equation.
- Basis functions
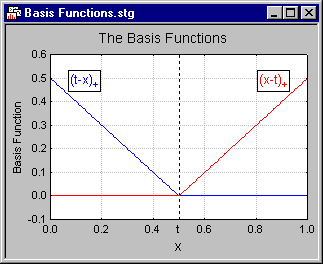
- Specifically, MARSplines uses two-sided truncated functions of the form (as shown below) as basis functions for linear or nonlinear expansion, which approximates the relationships between the response and predictor variables.
Shown above is a simple example of two basis functions ( t-x)+ and ( x-t)+ (adapted from Hastie, et al., 2001, Figure 9.9). Parameter t is the knot of the basis functions (defining the "pieces" of the piecewise linear regression); these knots (t parameters) are also determined from the data. The "+" signs next to the terms ( t-x) and ( x-t) simply denote that only positive results of the respective equations are considered; otherwise the respective functions evaluate to zero. This can also be seen in the illustration.
- The MARSplines model
- The basis functions together with the model parameters (estimated via least squares estimation) are combined to produce the predictions given the inputs. The general MARSplines model equation (see Hastie et al., 2001, equation 9.19) is given as:
where the summation is over the M nonconstant terms in the model (further details regarding the model are also provided in Technical Notes). To summarize, y is predicted as a function of the predictor variables X (and their interactions); this function consists of an intercept parameter (
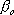 ) and the weighted (by
) and the weighted (by
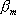 ) sum of one or more basis functions
) sum of one or more basis functions
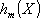 , of the kind illustrated earlier. You can also think of this model as "selecting" a weighted sum of basis functions from the set of (a large number of) basis functions that span all values of each predictor (i.e., that set would consist of one basis function, and parameter t, for each distinct value for each predictor variable). The MARSplines algorithm then searches over the space of all inputs and predictor values (knot locations t) as well as interactions between variables. During this search, an increasingly larger number of basis functions are added to the model (selected from the set of possible basis functions), to maximize an overall least squares goodness-of-fit criterion. As a result of these operations, MARSplines automatically determines the most important independent variables as well as the most significant interactions among them. The details of this algorithm are further described in Technical Notes, as well as in Hastie et al., 2001).
, of the kind illustrated earlier. You can also think of this model as "selecting" a weighted sum of basis functions from the set of (a large number of) basis functions that span all values of each predictor (i.e., that set would consist of one basis function, and parameter t, for each distinct value for each predictor variable). The MARSplines algorithm then searches over the space of all inputs and predictor values (knot locations t) as well as interactions between variables. During this search, an increasingly larger number of basis functions are added to the model (selected from the set of possible basis functions), to maximize an overall least squares goodness-of-fit criterion. As a result of these operations, MARSplines automatically determines the most important independent variables as well as the most significant interactions among them. The details of this algorithm are further described in Technical Notes, as well as in Hastie et al., 2001).
- Categorical predictors
- MARSplines is well suited for tasks involving categorical predictors variables. Different basis functions are computed for each distinct value for each predictor and the usual techniques for handling categorical variables is applied. Therefore, categorical variables (with class codes rather than continuous or ordered data values) can be accommodated by this algorithm without requiring any further modifications.
- Multiple dependent (outcome) variables
- The MARSplines algorithm can be applied to multiple dependent (outcome) variables, whether continuous or categorical. When the dependent variables are continuous, MARSplines will treat the task as regression; otherwise, it is a classification problem. When the outputs are multiple, the algorithm will determine a common set of basis functions in the predictors, but estimate different coefficients for each dependent variable. This method of treating multiple outcome variables is not unlike some neural networks architectures, where multiple outcome variables can be predicted from common neurons and hidden layers; in the case of MARSplines, multiple outcome variables are predicted from common basis functions, with different coefficients.
- MARSplines and classification problems
- Because MARSplines can handle multiple dependent variables, it is easy to apply the algorithm to classification problems as well. First, MARSplines will code the classes in the categorical response variable into multiple indicator variables (e.g., 1 = observation belongs to class k, 0 = observation does not belong to class k); then MARSplines will fit a model and compute predicted (continuous) values or scores; and finally, for prediction, will assign each case to the class for which the highest score is predicted (see also Hastie, Tibshirani, and Freedman, 2001, for a description of this procedure). The above procedure is handled by MARSplines automatically for you.
Model Selection and Pruning
In general, nonparametric models are adaptive and can exhibit a high degree of flexibility that may ultimately result in overfitting if no measures are taken to counteract it. Although such models can achieve zero error on training data (provided they have a sufficiently large number of parameters), they have the tendency to perform poorly when presented with new observations or instances (i.e., they do not generalize well to the prediction of "new" cases). MARSplines, such as most methods of this kind, tend to overfit the data as well. To combat this problem, MARSplines uses a pruning technique (similar to pruning in classification trees) to limit the complexity of the model by reducing the number of its basis functions.
- MARSplines as a predictor (feature) selection method
- This feature - the selection of and pruning of basis functions - makes this method a very powerful tool for predictor selection. The MARSplines algorithm will pick up only those basis functions (and those predictor variables) that make a "sizeable" contribution to the prediction (refer to Technical Notes for details). The Results dialog of the Multivariate Adaptive Regression Splines (MARSplines) module will clearly identify (highlight) only those variables associated with basis functions that were retained for the final solution (model).
Applications
Multivariate Adaptive Regression Splines (MARSplines) have become very popular recently for finding predictive models for "difficult" data mining problems, i.e., when the predictor variables do not exhibit simple and/or monotone relationships to the dependent variable of interest. Alternative models or approaches that you can consider for such cases are CHAID, Classification and Regression Trees, or any of the many Neural Networks architectures available in STATISTICA. Because of the specific manner in which MARSplines selects predictors (basis functions) for the model, it does generally "well" in situations where regression-tree models are also appropriate, i.e., where hierarchically organized successive splits on the predictor variables yield good (accurate) predictions. In fact, instead of considering this technique as a generalization of Multiple Regression (as it was presented in this introduction), you may consider MARSplines as a generalization of Regression Trees, where the "hard" binary splits are replaced by "smooth" basis functions. Refer to Hastie, Tibshirani, and Friedman (2001) for additional details.
Program Overview
The STATISTICA Multivariate Adaptive Regression Splines (MARSplines) module is an implementation of techniques popularized by Friedman (1991) for solving regression and classification type problems (see also Multiple Regression), with the main purpose to predict the values of a set of continuous dependent or outcome variables from a set of independent or predictor variables. There are a large number of methods available in STATISTICA for fitting models to continuous variables, such as a linear regression [e.g., Multiple Regression, General Linear Model (GLM)], nonlinear regression (Generalized Linear/Nonlinear Models), regression trees (see Classification and Regression Trees), CHAID, Neural Networks, etc. (see also Hastie, Tishirani, and Friedman, 2001, for an overview).
The program will automatically select the best set of predictor variables, or their interactions and report all model parameters required for interpreting the model. Options are available to address the problem of over-fitting by restricting the model complexity (maximum number of basis functions), or by applying pruning after a model of maximum complexity has been fitted to the data.
A large number of graphs can be computed to evaluate the quality of the fit and to aid with the interpretation of results. Various code generator options are available for saving estimated (fully parameterized) models for deployment in C/C++/C#, Visual Basic, PMML or STATISTICA Enterprise. (See also, Using C/C++/C# Code for Deployment.)