Weight of Evidence (WoE) Overview
Automated Weight-of-Evidence Coding for Continuous and Categorical Predictor Variables
The purpose of the Weight of Evidence (WoE) module is to provide flexible tools to recode the values in continuous and categorical predictor variables into discrete categories automatically, and to assign to each category a unique Weight-of-Evidence value.
This recoding method will produce the largest differences between the recoded groups with respect to the WoE values. In addition, other constraints are observed while the program determines solutions for the optimal binning of predictors.
An excellent source describing in detail the development of scorecards, and the role of WoE coding in credit scoring is Siddiqi (2006).
Application: Good and Bad Outcomes (such as Credit Default)
The methods described here were developed primarily for the credit and financial industries to aid in building models to predict the risk of loan default.
Once a history of data exists describing the performance of loans, meaningful prediction models can be built to predict the probability of loan default based on various characteristics (inputs or predictors) describing the applicant and/or application. A typical example of the results of such models is where applicant characteristics such as the age of a person or business, and previous credit history are linked to expected default probability (risk), expressed as a Credit Score.
Weight of Evidence
The Weight of Evidence or WoE value is a widely used measure of the strength of a grouping for separating good and bad risk (default). It is computed from the basic odds ratio:
(Distribution of Good Credit Outcomes) / (Distribution of Bad Credit Outcomes)
Or the ratios of Distr Goods / Distr Bads for short, where Distr refers to the proportion of Goods or Bads in the respective group, relative to the column totals,(expressed as relative proportions of the total number of Goods and Bads).
Specifically, the Weight of Evidence value for a group consisting of n observations is computed as:
The value of WoE will be 0 if the odds of Distribution Goods / Distribution Bads is equal to 1. If the Distribution Bads in a group is greater than the Distribution Goods, the odds ratio will be less than 1 and the WoE will be a negative number; if the number of Goods is greater than the Distribution Bads in a group, the WoE value will be a positive number.
WoE and Logistic Regression
The WoE recoding of predictors is particularly well suited for subsequent modeling using Logistic Regression.
Specifically, logistic regression will fit a linear regression equation of predictors (or WoE-coded continuous predictors) to predict the logit-transformed binary Goods/Bads dependent or Y variable. The Logit transformation is simply the log of the odds, (ln(p(Goods)/p(Bads). Therefore, by using WoE-coded predictors in logistic regression, the predictors are all prepared and coded to the same (WoE) scale, and the parameters in the linear logistic regression equation can be directly compared, for example, when using the new modeling tools for Marginal Stepwise Logistic Regression.
Information Value (IV)
The Information Value (IV) of a predictor is related to the sum of the (absolute) values for WoE over all groups.
Thus, it expresses the amount of diagnostic information of a predictor variable for separating the Goods from the Bads. Specifically, given a predictor with n groups, each with a certain Distribution of Goods and Bads, the Information Value (IV) for that predictor can be computed as:
According to Siddiqi (2006), by convention the values of the IV statistic can be interpreted as follows. If the IV statistic is:
- Less than 0.02, then the predictor is not useful for modeling (separating the Goods from the Bads)
- 0.02 to 0.1, then the predictor has only a weak relationship to the Goods/Bads odds ratio
- 0.1 to 0.3, then the predictor has a medium strength relationship to the Goods/Bads odds ratio
- 0.3 or higher, then the predictor has a strong relationship to the Goods/Bads odds ratio.
Example
This example illustrates the computations of the WoE statistic for different coded value ranges for a predictor variable Age, and the resultant Information Value for this predictor.
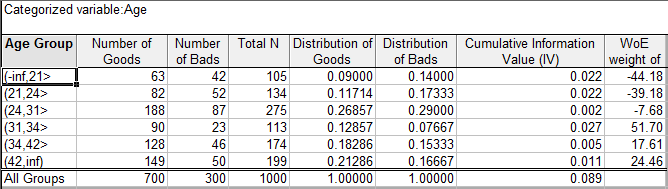
For example, for age group 21-24, there are 82 Goods and 52 Bads, or 0.117 and 0.173 Goods and Bads respectively, when expressed as proportions of the total number of Goods and Bads. The WoE value for that group is ln(0.11714/0.17333)*100=-39.18. The respective Contribution of that group to the overall Information Value (IV) is 0.022. The total IV value is 0.089, which indicates a weak relationship to the binary dependent variable.
Identifying an Optimal Coding of Continuous Predictors for Maximum WoE Delta
The goal of the automated WoE module is to efficiently identify the best recoding to weight-of-evidence values for a list of continuous predictors.
For categorical predictors or interactions between coded predictors, users can combine groups with similar observed WoE to create new coded predictors with continuous weight-of-evidence values; however, the module is of particular usefulness for continuous predictors, to achieve the best WoE coding for subsequent modeling (such as using logistic regression).
Specifically, the goal of the algorithms implemented in the automated WoE module is to identify the best groupings for predictor variables that will result in the greatest differences in WoE (WoE Delta) between groups, and in particular adjacent groups (intervals) for continuous predictors.
Algorithm
The algorithm implemented in Statistica for identifying the best coding of continuous predictors to maximize the WoE Delta proceeds as follows.
For continuous predictors, first a default coding is derived using the Classification and Regression Trees (C&RT) algorithm. For reasonably small numbers of default categories (fewer than 20 or so), Statistica will explicitly search through all possible partitions (combinations of default groups) to achieve the least numbers of groups with the greatest Information Value (IV). When the number of groups is greater than 20, Statistica uses the CHAID approach (which is described later in this document)
For categorical (discrete) predictors, the default (original) grouping is further refined using the CHAID algorithm; however, instead of the customary Chi-square value and goal function that is typically used in CHAID to determine if and how to combine groups, a modified CHAID algorithm is used with the goal to combine/split groups using the WoE Delta to combine/split criterion.
Optimal vs. best coding
Note that the algorithms used to find a best WoE coding will not search exhaustively through all possible partitions of continuous predictors.
Consequently, the results are not guaranteed to be optimal solutions, but only best solutions among those that were searched. This is a characteristic that this methodology shares with many of the predictive modeling algorithms, such as Trees, Neural Nets, which also are not guaranteed to arrive at globally optimal solutions, but will return good solutions instead. In practice, and through many real-world applications and tests, the algorithms implemented in the automatic WoE coding module have proven to return excellent solutions in practically all cases.
Constraints for Continuous Predictors
The algorithms for deriving the default coding for continuous predictors lend themselves to generate constrained solutions, in addition to the best unconstrained grouping of values.
Specifically, in many applications it is desirable to work with (WoE) coded predictors that show a specific simple relationship to the Goods/Bads odds ratio previously discussed.
For example, in credit scoring applications it is often important to be able to justify models based on common-sense reasoning because of regulatory oversight. This means, for example, that simple linear or monotone relationships of predictor values (recoded predictor WoE values) to odds (default) ratios are preferable to more complex relationships.
For example, consider a variable Age and its relationship to credit default risk. It would be desirable, and consistent with common-sense reasoning that older applicants for credit (with a longer credit history, greater assets, and so on) would pose a lesser default risk than younger applicants. Therefore, the monotone relationship between coded values for Age to the WoE would be desirable and preferable over complex nonlinear relationships.
Statistica automated WoE coding will compute, subject to their existence, three types of constrained WoE recoding solutions.
- Monotone solutions, where the WoE values of all adjacent recoded groups (intervals) will either increase (positive monotone relationship of predictor intervals to WoE), or the WoE values of all adjacent recoded groups will always decrease (negative monotone relationship of predictor intervals to WoE).
- Quadratic solutions, where the relationship between the coded value ranges (intervals) to WoE can have a single reversal so that the resulting function is either U-shaped or inverse-U-shaped.
- Cubic solutions, where the relationship between the coded value ranges (intervals) to WoE values can have two reversals so that the resulting function is S-shaped.
In summary, the automated WoE Coding module will possibly process large numbers of predictor candidates to derive the best constrained (simple) WoE coding and unconstrained WoE coding solutions.
Other Features: Custom Coding, Interactions
The automated WoE coding module also includes features that enable users to interact with the different solutions.
For example, you can create the following:
Also, the module includes a user interface where you can select pairs of coded predictors and implement a default (CHAID-derived) interaction coding of the two-way interaction table or user-defined coding. Details regarding this UI are described in the respective sections describing the automated WoE coding dialog boxes.
Deploying Predictor Coding Solutions as Rules to Enterprise
What can be done with the respective recoding logic for each variable, once a best or most desirable coding solution has been identified for the selected predictors:
- The recoding logic can be reviewed :via Statistica Rules Builder.
- The recoding logic can be deployed and managed as rules in Statistica Enterprise and workflows.
Specifically, all coding generated by the automated WoE coding module can be expressed as sequences of if {condition} then {assignment} elseif ... endif blocks.
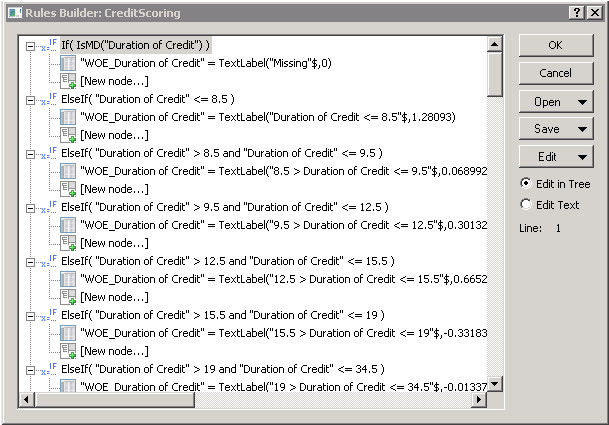
As a result of applying the final coding rules, new variables will be created following the convention WoE_OriginalName.
Each recoded predictor variable will be named with the prefix WoE, followed by an underscore and the original variable name. Also, the original value interval boundaries for each recoded group will be attached to the respective WoE value.
The deployment of the WoE coding solution involves the saving of this transformation logic either to a fixed disk location or to Statistica Enterprise.
Automated predictor pre-processing for batch and real-time scoring. Once the rules are deployed to Statistica Enterprise as a Rules object, these transformations (recoding rules) can be referenced in Workspaces from within the Rules node; the transformation logic can also be explicitly imported into a Rules node.
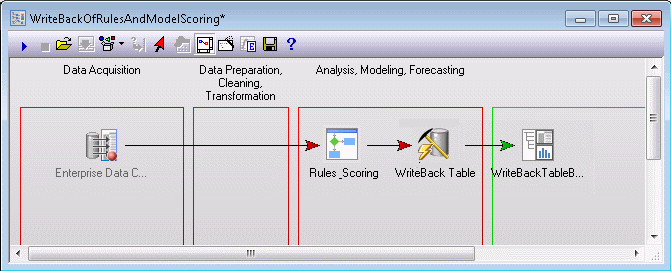
In this manner, the predictor transformation and recoding logic generated by the automated WoE Coding module can be used in efficient workflows for data pre-processing. Workflows can be used for batch scoring and real-time scoring via the Live Score platform.