Resource Failure Handling
The Resource Failure Handling feature identifies the failure or unavailability of resources as soon as possible and takes necessary actions. The Resource Failure Handling feature implements automatic reconnection feature for the key resources (JMS or DB) after failure or unavailability of these resources.
The Resource Failure Handling feature assists in the completion of the processing of previously submitted order without data loss, and in the suspending of the order processing after detecting resource failure.
Resource Failure Handling Architecture
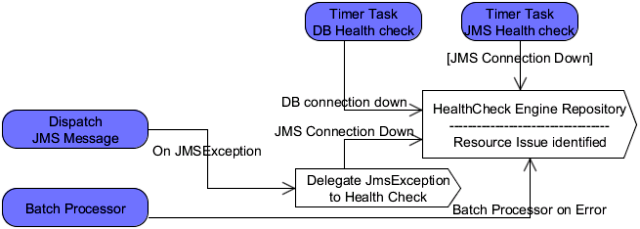
The two timer threads, one for the database and one for the JMS, keeps running at a predefined interval and checks for resource failure. If an exception is identified then status of the particular resource is updated to the HealthCheckEngine repository. If an exception is thrown while sending a JMS message by orchestrator then that exception is reported to the HealthCheck thread and the resources are verified for failure. If a failure is detected then that failure is reported to the HealthCheckEngine repository. The HealthCheckEngine repository is checked by the respective application to take the respective action on resource failure or recovery.
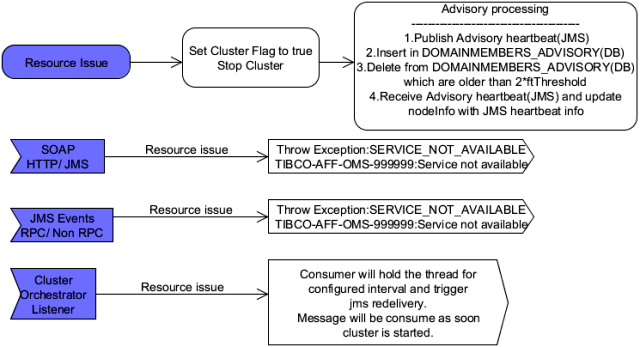
In case of a resource issue, the cluster processing will be stopped and the cluster status will be changed to INIT. The advisory messages will be processed by the Orchestrator for the JMS and the database. The messages will be processed by the respective resource that is available. The Orchestrator will not process any requests in case of a resource failure. The SOAP requests over JMS or HTTP will return back with the response code to signify resource issue. All JMS listeners of the Orchestrator will be running but will not process the messages. The JMS messages will be delivered again to the mentioned listeners. Messages on the TDS interfaces will return an error code signifying a resource issue.

In case of resource recovery, the processing of the advisory messages will be stopped and the processing of normal heartbeat will resume. The cluster will be initilaized with all the available members in the cluster using the hearteat mechanism. Once respective nodes are started, they will process the cleanup messgaes, and the pending batches, before marking the cluster state to the STARTED status. After node status is marked to STARTED, the normal processing will start and messgaes from JMS destinations will be processed.
For more details related to Resource Failure Handling, see the TIBCO® Fulfillment Order Management Administration Guide.