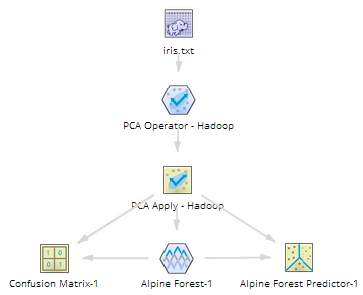
PCA Apply
Uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of uncorrelated variables (principal components).

Information at a Glance
The PCA Apply operator is used in conjunction with the PCA operator. PCA, or Principal Component Analysis, is a multivariate technique for examining relationships among several quantitative variables. Depending on your data source, see either PCA (DB) or PCA (HD) for more information about PCA modeling and the PCA operator configuration.
The PCA (HD) operator analyzes the data for determining the principle components matrix transformation, but needs the PCA Apply operator to actually transform the data before it passes the reduced variable set into any following operator.
Algorithm
The PCA Apply Operator applies the principal component matrix transformation algorithm defined by the PCA operator against the input data source.
Input
If the matrix transformation is to be applied to the source data set, no other input is required. However, if the matrix transformation is to be applied against a new data source, the data source to be transformed must also be an input into the PCA Apply Operator.
The two possible flow combinations for input into the PCA Apply operator are shown below for an example data set source called Iris. The PCA Apply operator is applied against either the training iris.txt data set or the iris.txt-NEW data set.
Restrictions
The PCA Apply operator can only be used with a PCA operator as input, applied against a Hadoop data source.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Target Number of Features | Dictates the number of principal components to define. This value must be less than or equal to the
Maximum Rank for Distributed Mode parameter value set for the associated PCA operator. See
PCA for details.
Note: This value must be less than or equal to the number of columns in the source data set that was passed into the PCA operator.
Default value: 5. |
| Carryover Columns | You can choose to keep columns from the original input data (that was passed into the PCA operator) "untransformed" and included in the PCA Apply operator output.
In this case, click Carryover Columns button to open the dialog box for selecting the columns to retain in the result table. |
| Store Results? | Specifies whether to store the results. |
| Results Location | The HDFS directory where the results of the operator are stored. This is the main directory, the subdirectory of which is specified in Results Name. Click Choose File to open the Hadoop File Explorer Dialog Box and browse to the storage location. Do not edit the text directly. |
| Results Name | The name of the file in which to store the results. |
| Overwrite | Specifies whether to delete existing data at that path and file name. |
| Compression | Select the type of compression for the output.
Available Avro compression options are the following. |
Output
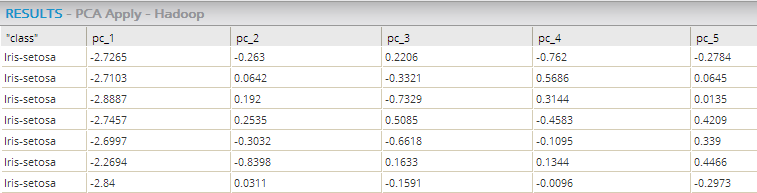
- Visual Output
- An overview of the new reduced principal components data set.
- alpine_pcaattr[0-5]+
- Each of the newly derived principal components columns is provided, along with their values for the new transformed data set. In this case, the source Iris data set with hundreds of variables was reduced to only five principal components variables and saved in Hadoop file format.
- Carryover Columns
- Any carryover columns from the original data set that were specified in the PCA operator configuration, such as any necessary unique ID key or the dependent variable to predict in a following model, are displayed here.
In this example, the "class" column was carried over to be used in a following Alpine Forest model.
- Data Output
-
The PCA Apply operator applies the matrix transformation algorithm received from the PCA operator against the input data set, outputting the transformed principal component data set. The PCA Apply operator can therefore be followed directly by any operator that accepts an input data set.