Time Series SAX Encoder
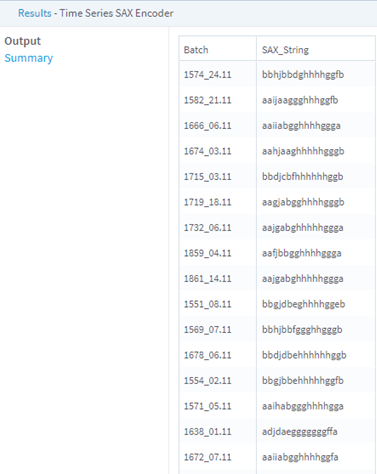
Produces a new data set with one or more columns that contains the time series ID and discretized string representation of the original time series.

Information at a Glance
The operator takes each time series in a row of the input table and creates a user-requested compressed representation of each input time series. Null values are dropped, and the time series is z-normalized if the user requests it.
The time series is then binned into a user-requested number of bins (specified in the SAX String Length parameter). If the length of the time series is not exactly divisible by the requested number of bins, the operator uses a partial contributions approach to determine the number of data points to include in each bin.
For example, if the time series has 10 data points and the user requests a bin size of three, the bin divisions are as follows.
- The first bin gets the first three points and 1/3rd of the fourth point.
- The second bin gets two-thirds of the fourth point, plus the fifth and sixth points, plus two-thirds of the seventh point.
- The third bin gets one-third of the seventh point, plus the last three points.
Once the time series is binned, the values within each bin are aggregated according to user selection (specified in the Aggregation Method parameter). If the user requests aggregate output, the values are returned; otherwise, the aggregated value is compared to the standard normal distribution, and the corresponding cut of the distribution is returned as the output.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
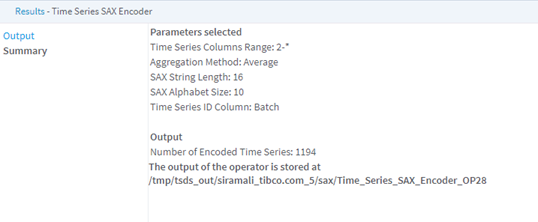
| Time Series Columns Range | Specify the column number range that contains the time series, one series per row. |
| Aggregation Method | Specify the aggregation method to use in SAX encoding - Average (the default), Maximum, Median, or Minimum. |
| SAX String Length | Specify the number of bins into which to discretize the time series. |
| SAX Alphabet Size | Specify the number of intervals into which to divide the z-normal distribution. |
| Time Series ID Column | An optional column name that contains the ID of the time series, for output clarity. If a name is not specified, Team Studio generates an ID column with row IDs in the output. |
| Columns to Keep | Click the Select Columns button to select columns from the input data set to append to the output. |
| Output Format | Defines the output format.
|
| Z Normalize Input | Specify whether the input time series should be standardized. Yes (the default) or No. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Advanced Spark Settings Automatic Optimization |
|