Resampling
Changes the distribution of values in a single column. You can use this operator to either balance all values in the selected column or change the proportion of only one value. You can use it to up-sample or down-sample.

Restrictions
Input data must have at least one categorical column with less than 100 distinct values.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Column to Resample
*required |
A categorical column with less than 100 distinct values. |
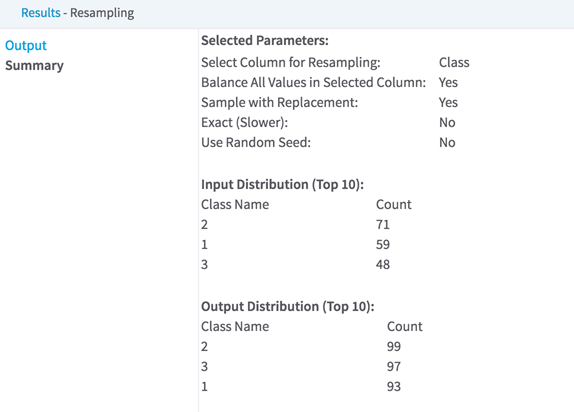
| Balance All Values in Selected Column | Yes balances all values in the selected column by up-sampling rows to match the number of rows of the most common value.
Sample with Replacement must be Yes, and any text entered into Single Value from Selected Column for Resampling is ignored. For example, if a dataset has 3 distinct values in the selected column with the following distribution the output has the following distribution. No resamples only one value in the chosen column. The user must enter values for Single Value from Selected Column for Resampling and Multiplier for Up-Sampling or Down-Sampling. Given the same input as above, if the user chooses to resample the value B with a multiplier of 3, output distribution is: |
| Single Value from Selected Column for Resampling | Required when
Balance All Values in Selected Column is
No.
A character string or a numeric value that appears in the column selected in Column to Resample. An error occurs when running the operator if the value does not occur in the column. |
| Multiplier for Up-Sampling or Down-Sampling | Required when
Balance All Values in Selected Column is
No.
A positive decimal number that is the multiplicative factor by which to resample the selected column and value. |
| Sample with Replacement | |
| Exact (Slower) | An exact calculation requires an additional pass through the data and results in slower operator execution. For non-exact resampling, the output distribution of values can vary from the expected distribution. |
| Use Random Seed | |
| Random Seed | An integer value that is used as the seed for the pseudo-random row extraction. Only used if Use Random Seed is Yes. |
| Write Rows Removed Due to Null Data To File | Rows with at least one null value in the
Column to Resample are removed from the dataset prior to resampling. This parameter allows you to specify whether rows with null values are written to a file.
The file is written to the same directory as the rest of the output. The filename is given a suffix of
_baddata.
|
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
Outputs
- Visual Output
-
The Output tab displays a preview of the output dataset.
The Summary tab displays information about the parameters selected, the output value distribution, and the information about rows removed from the data due to null values in the selected column.
- Data Output
- The resampled data set.