Text Featurizer
Parses a corpus of text into numeric features. You can select which metric(s) to compute for each document and for each of the selected n-grams or hashed features.

Input
The operator takes output from the N-gram Dictionary Builder and a data set of documents (one for each row). Use the operator to select which n-grams to use as features based on a set of criteria.
Restrictions
If you click Yes for Use N-gram Values as Column Names, you cannot connect the output to other operators.
Configuration
| Parameter | Description |
|---|---|
| Notes | Any notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk is displayed on the operator. |
| Text Column | The column that contains the documents to analyze. Each row is treated as one document. |
| Columns to Keep | The columns to pass through as features. These columns do not change; they are sent through to the output as is. |
| N-Gram Selection Method |
The criteria used to choose the n-grams to pull out as features. These preferences are applied to the training corpus input by the N-gram Dictionary Builder.
|
| Max Number of Unique N-grams to Select (Feature Hashing Size) | The number of n-grams to select from the dictionary to use as features. The default value is
500.
If, for N-Gram Selection Method, you selected Feature Hashing, this parameter represents the size of the hash set. In either case, the total number of features in the new data set is no greater than the number of pass-through columns selected + the value of this parameter multiplied by the number of values selected in the For each N-gram and Document Calculate parameter (1,2,3). |
| For Each N-gram and Document Calculate |
Select any or all of the following metrics:
Raw N-Gram Count - The number of times the n-gram appears in the document. Normalized N-Gram Count - Normalize word count against the original corpus. This is calculated using the following equation: The Number of tokens in the document metric is reported in the first column output of the featurized data set number_of_tokens. With custom tokenization and stop-word removal, the notion of a token can be complicated. We use the number of unigrams found in the document after stop words, and special characters have been removed. tf-idf - Computes tf-idf value for each n-gram. Note: tf-idf (term frequency - inverse document frequency) is a common algorithm used for feature generation in natural language processing. It calculates the relative importance of a term t in a document. Tf-idf lowers the weight of terms that are used more frequently in the corpus. To calculate the tf-idf score for a term, we use the following formula:
While TF is often calculated as the term frequency per token (using the same calculation as the Normalized N-gram Count, we use the number of times it appears here as an approximation for performance reasons. *This metric is the "Total Number of Documents" in the training corpus. The number is reported in the Corpus Statistics section of the N-Gram Dictionary Builder output. **This metric corresponds to the "document count" for the n-gram, which is reported in the dictionary output of the N-Gram Dictionary Builder. To learn more about tf-idf metrics, see http://www.tfidf.com/. |
| Use N-gram Values as Column Names |
|
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Avro compression options. |
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path. |
| Advanced Spark Settings Automatic Optimization |
|
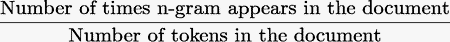
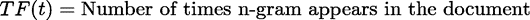

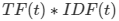
Outputs
- Visual Output
-
There are three sections of output:
- Featurized data set (Output)
- The output that is passed on to the next operator. Contains a row for each document and columns for the features generated for the n-grams.
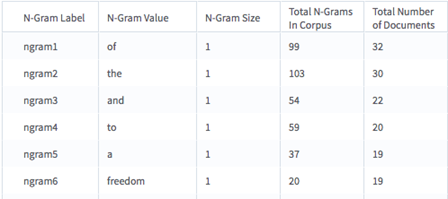
Here is an example (shortened) for analyzing Martin Luther King's speech "I Have A Dream":
- N-Grams to Column Names
- The dictionary of the actual value of the n-gram (for example, "freedom") to the name of the n-gram used in the column names such as ngram5. If feature hashing was used, this is essentially empty.
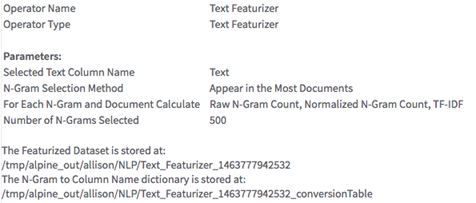
- Summary
- Some information about where the results were written and which parameters were chosen.
- Data Output
-
The data output is in two parts. One data set is the featurized data set, which is shown in the Featurized data set (Output) section above. This is what is sent to subsequent operators.
A dictionary mapping the n-gram numbers to their values is also written out, using the information from the N-grams to Column Names.