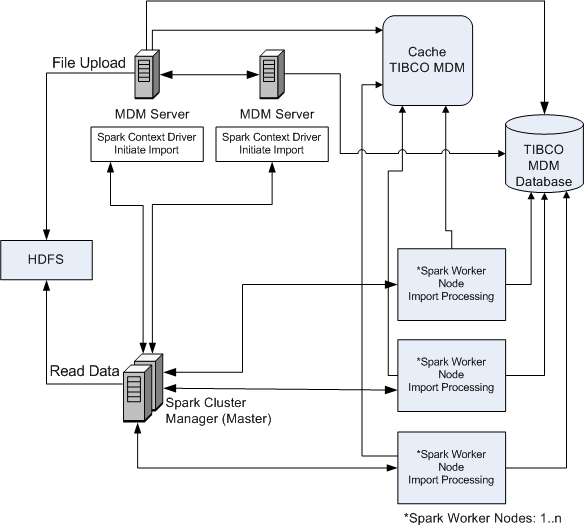
Big Data Import Using Apache Spark and HDFS
The big data import feature uses Apache Spark cluster to get high throughput. The big data import feature also leverages Apache Spark performance by processing the file simultaneously. The file is also uploaded to Apache Hadoop Distributed File System (HDFS) to get high throughput when using huge files.
When you start big data import, Apache Spark and HDFS must be up and running. Import is triggered from any of the TIBCO MDM servers. After the import is triggered, Spark cluster decides (based on the worker nodes) how to balance the loads among the worker nodes. Spark worker nodes need to know the configuration of database and the cache. After the import is triggered in TIBCO MDM and the jobs are completed by the Spark cluster, the import event is updated.