SVM Use Case
The following model demonstrates using an SVM Classification model to assess the varying characteristics of Forest Cover.

Forest Cover Data Classification
- Datasets
-
This dataset comes from the UC Irvine site: http://archive.ics.uci.edu/ml/datasets/Covertype, and the exact version used for this case (with added headers) is covtype.csv (75.2MB).
The Forest Cover dataset is a standard dataset that data scientists use. The source dataset provides data for determining the type of forest cover to be expected based on soil type, elevation, aspect, slope and other forest variables. It contains 581,012 observations, 54 attribute columns (10 quantitative variables, 4 binary wilderness areas ans 40 binary soil type variables) and 1 label column (cov_type). The possible classifications for cov_type include Spruce/Fir (Type 1), Lodgepole Pine (Type2), Ponderosa Pine (Type 3), Cottonwood/Willow (Type 4), Spruce/Fir and Aspen (Type 5), and Douglas-Fir (Type 6).
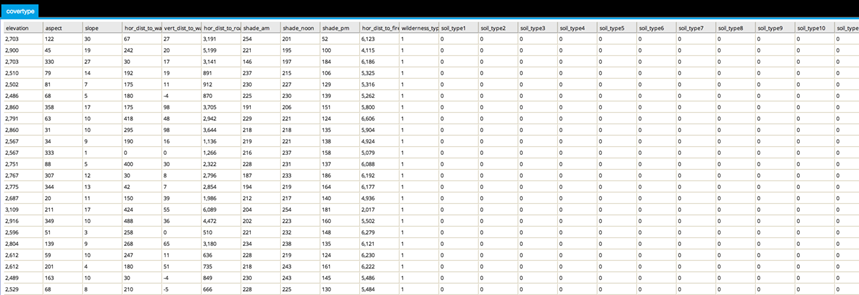
The first few rows and columns are shown below:
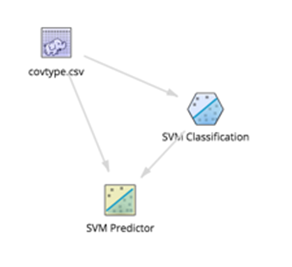
Workflow
An SVM Classification model can be setup quickly to analyze the data, with the following workflow:
The SVM Classification configuration parameters are set as follows.
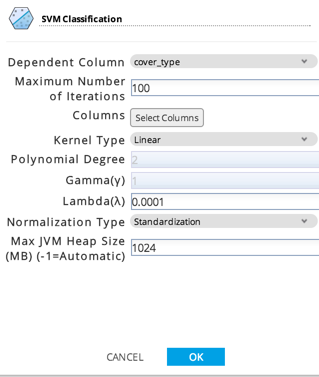
The column cover_type is selected as the dependent column and, for the Select Columns, all 54 other columns are selected as attributes for SVM.
For the first running of the SVM Classification, Linear Kernel Type should be selected.

Results
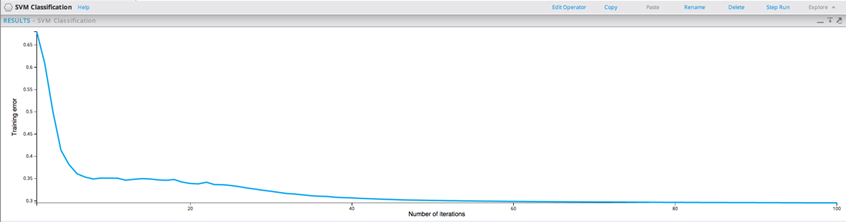
Running the SVM Classification Model results in the following Training Error curve. After about 40 Iterations the model accuracy stabilizes and it can be considered a fairly good model.
The SVM Predictor output looks as follows (same dataset with 3 more columns at the end):
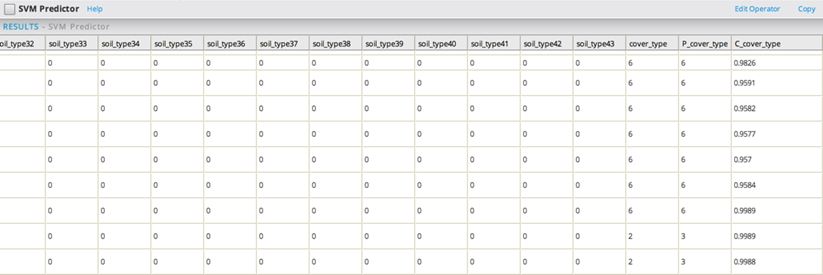
C_cover_type details give the confidence values for each of the 6 cover_type classes. C_cover_type shows the highest confidence value associated with the predicted class P_cover_type. The model does not always seem to be predicting the correct type of Forest Cover. Indeed, for some observations the predicted class (P_cover_type) is not the same as the real one (cover_type).
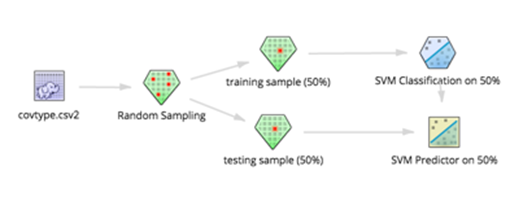
As a next step, the modeler should consider running a Cross-Validation workflow which splits the data into two groups, builds the model based on the first half of the data and then assesses it's accuracy on the other half, as follows: