Selecting Groups of HDFS files
Team Studio Hadoop users can select multiple, similarly-structured files from the Hadoop File operator.
To use this feature and include all needed files, you can add a Hadoop data source to your workflow, and then modify the Hadoop File Name text manually with wildcard characters.
The Hadoop file structure configuration is based on the first file, alphabetically, from this list, and is applied to all of the other files. Succeeding operators treat these files as a single, unified input.
For example, to select all of the .csv files that begin with "13" from a /user/tsds/ HDFS directory, set Hadoop File Name to /user/tsds/13*.csv.
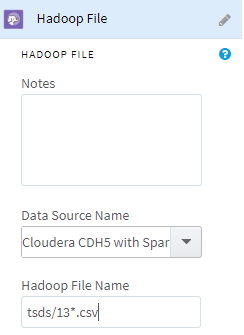
You can also use wildcards to specify multiple directories; for example, /user/*/13*.csv.
To be able to specify multiple directories, you must meet the following requirements.
Wildcard patterns
A file name pattern can be composed of regular characters and any of the following wildcard characters.
| Character or pattern | Matches |
|---|---|
| ? | Matches any single character. |
| * | Matches zero or more characters. |
| [abc] | Matches a single character from character set {a,b,c}. |
| [a-b] | Matches a single character from the character range {a...b}. Note that character a must be lexicographically less than or equal to character b. |
| [^a] | Matches a single character that is not from character set or range {a}. Note that the ^ character must occur immediately to the right of the opening bracket. |
| \c | Removes (escapes) any special meaning of character c. |
| {ab,cd} | Matches a string from the string set {ab, cd}. |
| {ab,c{de,fh}} | Matches a string from the string set {ab, cde, cfh}. |