Variable Selection (HD)
Identifies and prioritizes the variables of interest to a prediction task or model. This is especially helpful when there are a large number of potential variables for a model, enabling the modeler to focus on only a subset of those that show the strongest relevance.

Information at a Glance
| Category | Explore |
| Data source type | HD |
| Sends output to other operators | Yes |
| Data processing tool | MapReduce |
Algorithm
For Hadoop, there are two choices: Information Gain and R2. The Hadoop-based information gain option calculates both information gain and information gain ratio.
- Information Gain
-
Information Gain is a measure of the change in the entropy (or uncertainty) of a random variable Y when it is conditioned on another (categorical) variable X. In our case, Y is the class to be predicted (the dependent variable), and X is a candidate driver.
The entropy of a categorical random variable Y with n possible values (classes) is given by
The conditional entropy of Y given the values of a discrete variable X that takes on the m values is given by
The information gain about Y, given that we know X measures how much more we know about Y because we know X:
- Score Threshold by Chance
-
Score threshold by chance is a score we can get just by chance, even if X is not truly predictive of Y. We generate X that are designed to be independent of Y according the distribution of Y and then calculate the score. We can generate a lower-bound threshold T. Any candidate feature that scores lower than T is almost certainly not predictive of the output variable, and can be eliminated. In practice, T is quite small, and probably does not eliminate too many variables. However, it still gives a useful sense of scores that correspond to meaningful and less-meaningful variables.
- Handling numerical columns with Information Gain
-
For numerical columns in Hadoop, we compute mutual information between dependent and independent variables without discretization. The Hadoop Variable Operator does not perform Minimum Description Length (MDL) discretization like the database version, because it is extremely expensive when dealing with big data.
- R2
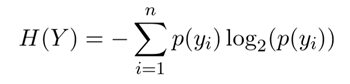
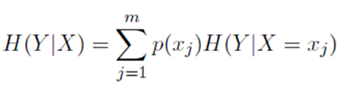
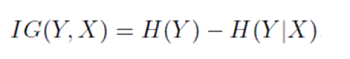
Configuration
Output
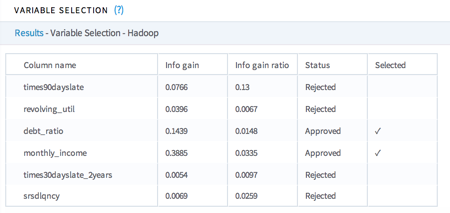
- Visual Output
- Column name, R2 or info gain, and status values, as shown in the following table.
Status Meaning Approved R2 or info gain value is above the set threshold for this variable. Mandatory R2 or info gain value is not above the set threshold, but this column is in the "always included" list. Rejected R2 or info gain value is not above the set threshold. Selected If checked, this variable is added to the variable mask. For info gain
- Data Output
- The subset of suggested variables from the Variable Selection operator can be passed to the Naive Bayes, Linear Regression, and Logistic Regression operators. These operators use the results of the variable selection to automatically choose the appropriate independent values.