Regular Expression Patterns for Text Fields
When defining a Primitive Type, text fields can be constrained to match certain patterns.
For example, if you want an OrderId type to be formatted as ORD-NNNNNN, where "N" represents a digit, then you can specify this by using a Pattern in the Advanced Property Sheet for the Primitive Type:
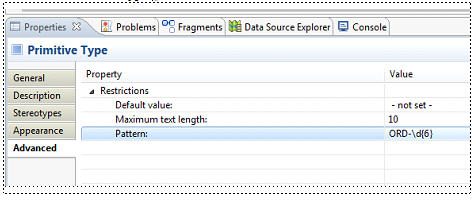
In the pattern shown in the above example, the "\d" represents any digit and the "{6}" means there must be 6 of the preceding element (in this case, a digit).
Additional example patterns that can be used are listed below.
| Pattern | Examples | Description |
|---|---|---|
| ID-[0123456789abcdef]* | Correct: ID-deadbeef ID- ID-1234 ID-0fff1234 Incorrect: ID ID-0A |
The content in the square brackets may include any number or lowercase letter of the alphabet. In other words, the square brackets may contain any hex digit. The asterisk means zero or more of the previous element. In this case, any number of lowercase hex digits may be used. |
| ID-[a-f0-9]+ | Correct: ID-0000dead Incorrect: ID- ID-0000DEAD |
As in the previous example, the "a-f" means any letter in the range "a" to "f" and the "0-9" means any digit. The "+" means one or more. |
| [^;]+; | Correct: Hello; Incorrect: Hello;Bye; |
The "^" at the start of a range refers to characters outside the allowable range, so "[^;]" matches any character apart from ";". The "+" after it means one or more, and must be followed by a ";". |
| \d{1,3}\.\d{8} | Correct: 1.12345678 123.12345678 Incorrect: 1.234 |
"\d" means any digit. "{1,3}" means between 1 and 3 repetitions of the previous element. "\." matches a ".". However, because "." normally matches any character, in this case it must be escaped. Similar to the "\d" sequence, you can use "\w" for any word character and "\s" for any white space character. The "\D", "\W", and "\S" sequences inverse character sets. |
| \i\c* | Correct: xml:schema :schema Incorrect: 0xml:schema -schema |
"\i" matches the initial character of any valid XML name, and "\c" matches any character that can appear after the initial character. Similarly, the "\I" and "\C" are the negations. |
| [\i-[:]][\c-[:]]* | Correct: xmlschema _schema Incorrect: xml:schema :schema |
"[a-z-[aeiou]] a-z"matches any lowercase letter, adding "–[aeiou]" at the end removes the vowels from the set of letters that are matched. The example on the left removes ":" from the "\i" and "\c" lists of characters so the pattern now matches non-colonized names. |
| [-+]?\d+(\.\d+)? | Correct: 0.1 -2.34 +3 Incorrect: 4. |
If you want to include a "-" in a range, then it should be the first character, as it has a special meaning if not the first character. The "?" indicates that the previous element is optional. The parenthesis marks form a group. The whole group is optional because of the "?" at the end. If a decimal point appears, then decimal digits must follow in this example. |
You can read more about regular expressions at: