Record Duplicate Detection Process
To detect duplicates, using this application, you can conduct ’similarity or fuzzy’ searches based on certain identifying attributes.
You can detect a duplicate with small variations in the data and merge the data during a single or bulk record add or modify workflow. With the duplicate detection routine, you can run a fuzzy query based on a configurable record attribute and then returns one or more potential matches. Netrics or Advanced Matching Engine is the search or match engine used for text search and record matching. You can match and deduplicate records in bulk. Using the business process rule (BPR) process definition selection, you can override the default upload or import process to choose the data quality import process. This direct load import process calls the match and merge activities to detect duplicates and deduplicate.
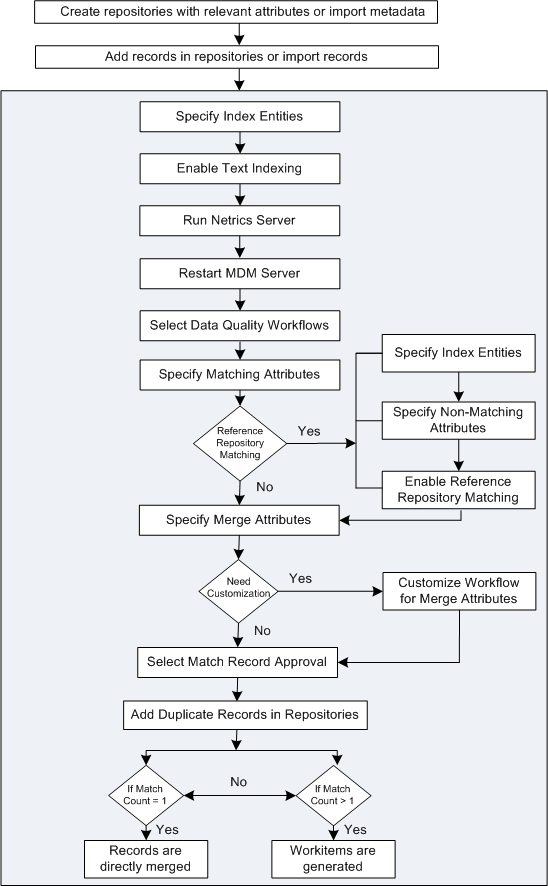
The following components are involved in this process:
- Index Entities
- Enabling Text Indexing
- Running Netrics Server and Restarting MDM Server
- Selecting Data Quality Workflows
- Specifying Matching Attributes
- Enabling Reference Repository Matching
- Specify Merge Attributes
- Customizing Workflow for Merge Attributes
- Selecting Match Record Approval
- MergeRecord Activity