Viewing Input Maps
To view details of an input map, select the input map name on the Input Map screen and click
 . The View Input Map screen is displayed.
. The View Input Map screen is displayed.
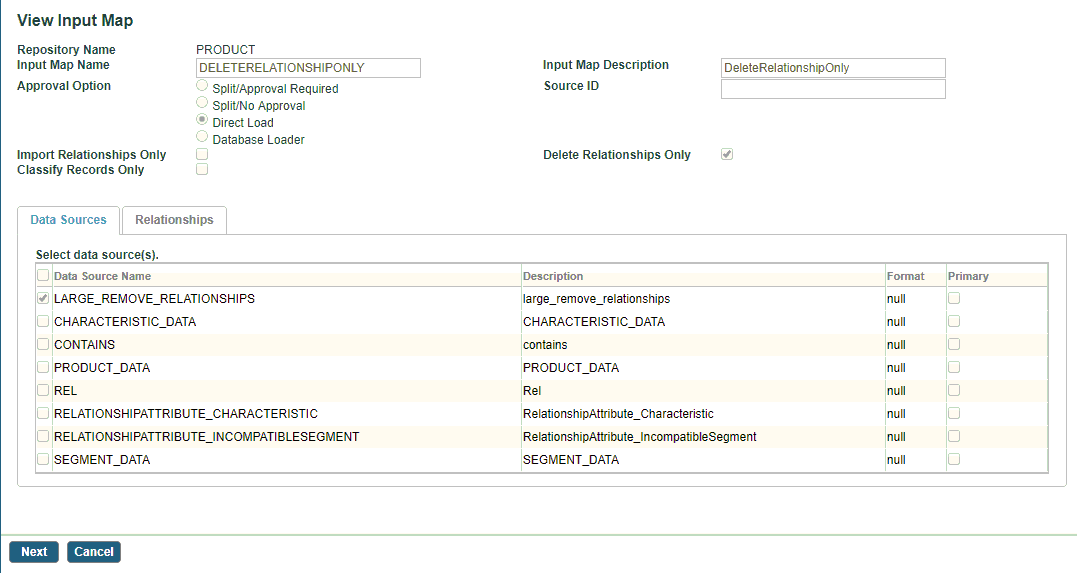
The Viewing Input Map screen contains the following two sections:
- Input Map Details: The name and description for the Input Map. The Name is unique and not case-sensitive for a repository. The name can contain A-Z, 0-9, and _.
- Approval Option:
Split/Approval Required: Select the Split/Approval Required import mode to split the imported records into bundles before processing. The bundling is done based on the hierarchy configured in a workflow. Each of the bundle is processed in separate independent workflows, which is a series of two workflows for each bundle.
Conflict resolution and merge – This workflow checks if the imported changes are in conflict with any other changes done to bundle after import has been initiated. If there is any conflicts, you need to resolve the conflict.
Normal governance workflow – After conflict is resolved, workflows for record add, modify, or delete are invoked for each bundle and will go through normal governance process as if the changes were initiated from UI or web services. In these workflows, an approval step is included before changes to record bundles can be confirmed.
Split/No Approval: Select the Split/No Approval import mode to merge the concurrent changes or detect conflict in the concurrent changes. Use this mode when records being imported are also modified by other processes or users. The Split/No Approval mode splits the import batch into multiple record bundles. For each bundle, a separate workflow process is fired to verify if the data has changed since the import has started. If required, data is merged or conflict resolution is attempted. Each workflow completes independent of other workflows.
Direct Load: All records are processed as one batch, with intention to make the data available and confirm the records immediately. The records can be validated and erroneous records can be rejected before confirming the valid records. A batch approval step can be configured to approve the whole batch. During the direct load, if any records that are part of the import are modified concurrently by other processes or users, such changes are overridden by imported data. Direct load is one of the four pre-defined modes implemented by out-of-the-box workflows. In most cases, the out-of-the-box workflows are modified for specific implementation.
Note: To summarize, these three different approval options handle complex data in the following ways:- Direct Load processes all of the imported records as one logical batch and confirms the validated records.
- Split/Approval Required allows splitting the logical batch into record bundles only to check for concurrent modifications and conflicts.
- Split/No Approval goes further and converts the logical batch into individual record bundles and executes the normal governance.
Database Loader: If this radio button is selected, the Mode drop-down list and Fresh Data check box appear. Select Load Records or Load Relationships mode. The records or relationships are uploaded using Database Loader. Select the Fresh Data check box to indicate that data is clean, and the initial version records need to be loaded. To learn more about Database Loader, refer to Importing of Records Using Database Loader.
- The Merge Data check box: When checked (or set to TRUE), any previous child relationships must be retained. When this check box is checked, any null values in the imported data are populated with data already stored in the database, provided the nullIfblanks input mapping option is not checked for such attributes. This allows partial data to be imported.
- The
Import Relationships Only
check box: Checked to import only relationships. The
Import Relationships Only check box is displayed only if you have selected the Direct Load option. The following actions are performed if this check box is selected:
- If the relationship does not exist in a repository, the relationship is created with the current version of existing records without considering the change in parent and child attributes. Existing records’ version is not changed.
- If the relationship and its attributes do not exist in a repository, relationship is created and its attributes are also added in the repository.
- If the relationship already exists in a repository and only relationship attributes are changed, they are updated.
- If both relationship and its attributes exist in a repository and there is no change in relationship attributes, relationship is not created and its attributes are also not updated.
- Duplicate records are ignored.
- The relationships are imported while executing the ExtractRelationship activity. For details about this activity, refer to TIBCO MDM Workflow Reference.
- Source ID: The source ID allows you to associate the data with an external system. The source ID is not automatically stored with records as attributes, but a rulebase can be used to copy the value to an attribute. The source ID can be used in workflow and business process rules to customize business processes.
- The
Delete Relationships Only check box: deletes the relationships between two records as per the input map mapping. The
Delete Relationships Only check box is displayed only if you have selected the Direct Load option.
To view and use the Delete Relationships Only check box on the TIBCO MDM UI, you must select the Delete Relationships Only check box using TIBCO MDM Studio while creating an input map.
- Approval Option:
- The
Data Sources tab: If you have selected more than one data source to map to an input map, the next screen displays a set of keys that are common to the selected data sources. The key columns of each datasource has the same name in all joined data sources. If the selected data sources do not include common keys, the following error message is displayed:
Invalid Input map; no common key defined.
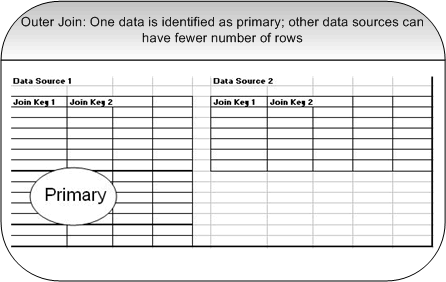
You can identify one of the datasource as the primary data source by the Primary? check box in the appropriate data source row.
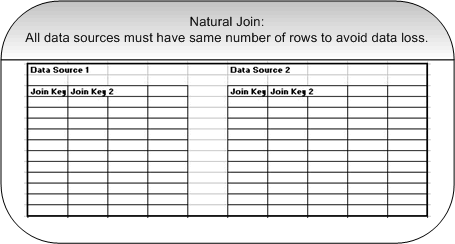
Note: If you do not select primary datasource, a row is discarded. The data corresponding to keys is not present in all the joined data sources.Primary data source identification is optional. It is recommended only if multiple data sources or a data source has fewer number of rows, and join key for such rows in primary data source do not exist in other data source. The primary data source should be the one which is a pivot data source. When multiple data sources are checked, data between the data sources is joined as follows:
- Outer Join: If a primary data source is identified, data from other data sources is joined with the primary data source using an outer join.
- Natural Join: A natural join is also known as an equi-join. If no primary data source is identified, data from all data sources is joined using a natural or equi-join. To avoid loss of data, all data sources must have the same set of records.
- Attribute Mapping: The View Input Map screen displays an Attribute Mapping section to map Data Source attributes to repository attributes. From this screen, you can view selected attributes from a data source to import to a repository. The data source attributes are mapped to the repository attributes.
- Click Expand All to view the user-defined system attributes and the user-defined attributes in their respective Attribute Groups.
- Click
Collapse All to collapse the Attribute Group list. In this case, only the names of the Attribute Groups are displayed.
Click
 next to an attribute group to display or hide its attributes.
next to an attribute group to display or hide its attributes.
The Data Source Attribute list displays all the columns available in the selected data source or sources. When you select an attribute, the mapping automatically appears in the Expression column.
Multivalue attributes can be mapped to different attributes of a data source. For multivalue attributes, you can click
 to add one more row. A new row is added to the table where you can map the data source attribute to a repository attribute which was cloned. You can click
to add one more row. A new row is added to the table where you can map the data source attribute to a repository attribute which was cloned. You can click
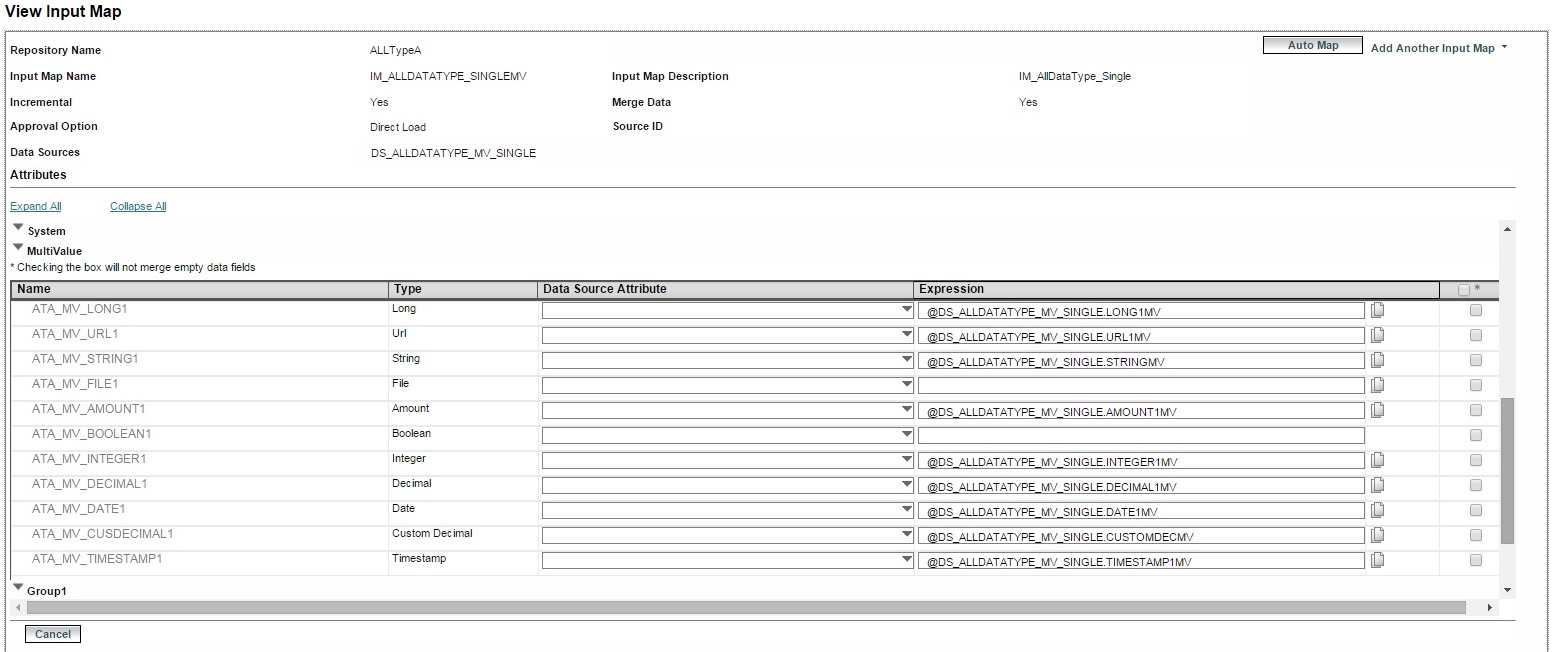
 to delete the mapping row. The following figure shows mappings of a multivalue attribute:
to delete the mapping row. The following figure shows mappings of a multivalue attribute:
- Relationship attributes are listed under the Relationship Attributes group. These attributes can be mapped to the attributes of the data source.

- Expression: Enter a valid SQL expression in the
Expression
column. The expression must conform to following rules:
- All expressions entered in the Expression column must be valid SQL expressions.
- If you include a column name from an SQL table, ensure that the name entered exists and is as specified in the SQL table.
- Enter integers directly, but embed String values in single quotation marks.
- If data contains an @ character, it cannot be entered in the source expression.
The following are a few sample SQL expressions:
CASE WHEN ((@<Data Source Name>.UOM) = '') THEN (SUBSTR('CONSTANT',1,4)) ELSE (SUBSTR('CORRECTEDPACK',1,13)) END CASE WHEN ((@FLAG.FLAG) = 'm') THEN @FLAG.DESC ELSE (SUBSTR('',0,0)) END
- Check box with an asterisk: Appears to the left of the Attribute Name for all required attributes in a given format.
Select the check box in the * column if you want to consider a blank value in the data source as NULL. Usually, this flag is specified for CONTAINS attribute. It is used only if Merge Previous Data is TRUE and CONTAINS attribute does not have any value for the record. When the check box in the * column is checked, it indicates that child relationships would not be merged if no value is specified in the CONTAINS attribute. For more information on Contains attribute, refer to Explicit Relationship Using the CONTAINS Attribute.
- Automatic mapping: If the data source attribute name and the repository attribute name are the same, click the
Auto Map button to automatically map the attributes. Any attribute which does not have a mapping (null) is mapped if the name of the attribute matches the attribute name in the data source.
If multiple data sources with the same attribute name exist, and Primary is specified, the primary data source is given priority. If Primary is not specified, the data source is picked up randomly.
- Automatic mapping: If the data source attribute name and the repository attribute name are the same, click the
Auto Map button to automatically map the attributes. Any attribute which does not have a mapping (null) is mapped if the name of the attribute matches the attribute name in the data source.