Noncentrality-Based Indices of Fit - Population Gamma Index
Tanaka and Huba (1985, 1989) have provided a general framework for conceptualizing certain fit indices in covariance structure analysis. In their first paper, Tanaka and Huba (1985, their Equation 19) gave a general form for the sample fit index for covariance structure models under arbitrary generalized least squares estimation.
In the Tanaka-Huba treatment, it is assumed that a covariance structure model has been fit by minimizing an arbitrary GLS discrepancy function of the form
![]() (93)
(93)
or, equivalently (see Browne, 1974)
![]() (94)
(94)
where s = vecs(S), and s = vecs(S(q)). V in Equation 93 and W in Equation 94 are arbitrary matrices. Appropriate choice of V or W can yield GLS or IRGLS estimators. For example, minimization of Equation 93 with V = S-1 if S has a Wishart distribution yields the well-known GLS estimators (Browne, 1974). Setting V=[S(q)]-1 yields IRGLS estimators. Bentler (1989, page 216), citing Lee & Jennrich, 1979, states that IRGLS estimators are equivalent to ML estimators. Setting
![]() (95)
(95)
yields a discrepancy function which, according to Browne (1974), is usually minimized by the same q that minimizes the maximum likelihood discrepancy function.
The Tanaka-Huba fit index can be written as
![]() (96)
(96)
In their more recent paper, Tanaka and Huba (1989) demonstrate a deceptively simple but important result that holds for models that are invariant under a constant scaling function (ICSF). A covariance structure model is ICSF if multiplication of any covariance matrix that fits the model by a positive scalar yields another covariance matrix which also satisfies the model exactly (though possibly with different free parameter values).
If a model which is ICSF has been estimated by minimizing a discrepancy function of the form given in Equations 93 and 94, then
e¢ Ws = 0(97)
i.e., e and s are orthogonal "in the metric of W," and, consequently,
s¢ Ws = s¢ Ws + e¢ We(98)
If Equation 98 holds, then g may be written
g = s¢ Ws/s¢ Ws = 1 - e¢ We/s¢ Ws (99)
where, as in Equation 64, e = s - s. In this form, g defines a weighted coefficient of determination.
Under the conditions of Equation 98, with maximum likelihood estimation, we immediately obtain:
 (100)
(100)
![]() (101)
(101)
whence
 (102)
(102)
which is equivalent to the Jöreskog and Sörbom (1984) GFI index.
Moreover, if the model is ICSF, then, under maximum Wishart likelihood estimation, there is the simplifying result (Browne, 1974, Proposition 8)
![]() (103)
(103)
Substituting in Equation 100, we find:
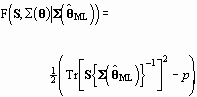 (104)
(104)
and so
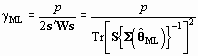 (105)
(105)
Tanaka and Huba (1985, 1989) based their derivation of g on sample quantities. However, in principle, we are interested in a sample index primarily as a vehicle for estimating the corresponding population index. The corresponding population quantities are obtained by substituting S for S, and S(q) for S(qML) in Equations 104 and 105.
We obtain:
![]() (106)
(106)
G1 can be thought of as a weighted population coefficient of determination for the multivariate (ICSF) model. (It may also be thought of as the population equivalent of the Jöreskog-Sörbom GFI index.)
An accurate point estimate for G1 will provide useful information about the extent to which a model reproduces the information in S. A confidence interval, however, provides even more useful information, because it conveys not only the size of G1, but also the precision of our estimate.
Let F* be the Population Noncentrality Index F(S,S(qML)). From Equations 104 and 105, it is easy to see that
![]() (107)
(107)
Equation 107 demonstrates that, under maximum likelihood estimation with ICSF models, G1 can be expressed solely as a function of the Population Noncentrality Index and p, the number of manifest variables. Any consistent estimate of F* will yield a consistent estimate of G1 when substituted in Equation 107.
Equation 107 implies that an asymptotic maximum likelihood estimate (AMLE) for the population noncentrality index F* may be converted readily to an AMLE for G1, simply by substituting the AMLE for F* in Equation 107.
Similarly, substitution of the endpoints of the confidence interval for F* in Equation 107 will generate a confidence interval for G1.
Equation 107 and the accompanying derivation were first presented in Steiger (1989). Maiti and Mukherjee (1990), working completely independently of Steiger (1989), produced the identical result (their Equation 17). Steiger (1989) had suggested that the sample GFI was a biased estimator of the population value. Maiti and Mukherjee quantified the bias with the following (their Equation 16) approximate expression (for a Chi-square statistic with n degrees of freedom).
![]() (108)
(108)
This can be rewritten in perhaps a more revealing form as
![]() (109)
(109)