GCHAID Results - Summary Tab
Select the Summary tab of the GCHAID Results dialog box to access the options described here.
- Tree view
- The Tree view group box contains the following options:
- Tree browser
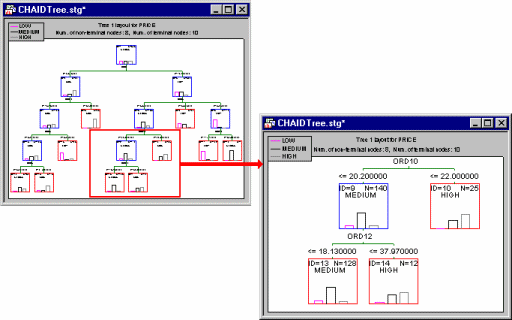
- Click this button to produce a complete representation of the results tree inside a STATISTICA workbook-like browser. Every node will be represented by a graph containing the respective split rule (unless the respective node is a terminal node) and various summary statistics. Intermediate and terminal nodes will be shown in the browser with different symbols:
This browser provides a complete summary of the results and thus allows you to efficiently review even the most complex trees (see also Reviewing large trees: Unique analysis management tools). However, the results displayed differ, depending upon whether the selected response variable was categorical or continuous.
Results for categorical dependent variable (classification). If you selected a categorical response variable (classification-type analysis; see also the GC&RT Overviews), then clicking on a node in the tree browser will produce a graph displaying the number of cases in each category of the variable as well as the histogram of statistics for the selected node.
Results for continuous dependent variable (regression). If you selected a continuous response variable (regression-type analysis; see also the GC&RT Overviews), then clicking on a node in the tree browser will produce a graph displaying the mean and variance of the variable as well as the plot of normal density with these parameters for the selected node.
- Tree graph
- Click this button to produce the Tree graph for the final tree. In this graph, each node will be presented as a rectangular box, where the terminal nodes are highlighted in red, and the intermediate nodes are highlighted in blue (by default). The following information is usually summarized in this graph: Node ID, the node size, the selected category of the response and the histogram (for classification-type problems) or the mean and variance at the node (for regression-type problems; see also the GC&RT Overviews). The graph also contains splitting information for the intermediate nodes: The splitting criterion that created its child nodes and the name of the predictor that was used in the splitting criterion. Note that all labels and legends for the graph are produced as custom text, and so can be edited via the Graph Title/Text dialog box, moved, or deleted.
These tools allow you to review all details of large and complex tree graphs.
For reviewing large trees, you can also use the Scrollable Tree or Workbook Tree Browser facilities, which are particularly well suited for browsing the information contained in complex regression or classification trees.
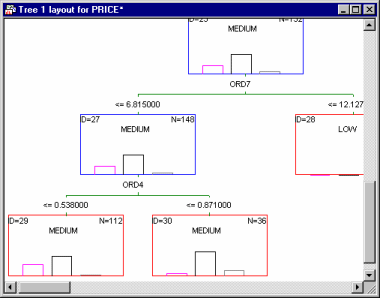
- Tree layout
- Click this button to display the graph showing the structure of the final tree. Each node will be presented as a rectangular box, where terminal nodes are highlighted in red, and non-terminal nodes are highlighted in blue.
- Scrollable tree
- Click this button to display the same Tree graph, but in a scrollable window.
In a sense, this option will display a very large graph that can be reviewed (scrolled) "behind" a (resizable) window. Note that all standard graphics editing, zooming, etc. tools for customization and reviewing further details of the graph are still available for this method of display.
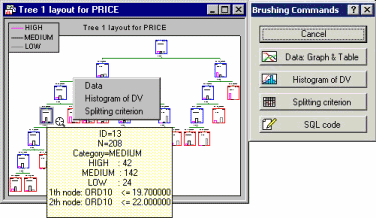
- Brush tree
- Click this button to "brush" large trees, i.e., to review the contents of different nodes in greater detail. After clicking the Brush tree button, STATISTICA will automatically "find" the tree for brushing, or create a summary tree graph if none has been created yet. The cross-hair tool
 will be displayed along with the Brushing Commands dialog box.
will be displayed along with the Brushing Commands dialog box.
If you move the crosshair over a node, a ToolTip will pop up displaying detailed summary statistics for the respective node. To select a node, click on it; you can then select the desired action for that node from the Brushing Commands dialog or the shortcut menu, which contain identical options. For descriptions of the options available for each node, see the Node tab.
You can exit the Brushing tree mode by clicking Cancel in the Brushing Commands dialog box.
- Design terms
- This option is only available if a coded (ANCOVA-like) design is specified (that option was chosen from the Startup Panel; see also Analyzing ANCOVA-like Designs in the General Classification and Regression Trees Overviews - Introductory - Overview Basic Ideas Part II). Click the Design terms button to display a spreadsheet of all the labels for each column in the design matrix (see also the GLM Introductory Overview). This spreadsheet enables you to unambiguously identify how the categorical predictors in the design were coded, that is, how the prediction model was parameterized. If in the current analysis the categorical predictor variables were coded according to the sigma-restricted parameterization (as requested via the respective option on the C&RT Specifications dialog box - Advanced tab), this spreadsheet will show the two levels of the respective factors that were contrasted in each column of the design matrix; if the overparameterized model was used, then the spreadsheet will show the relationship of each level of the categorical predictors to the columns in the design matrix (and, hence, the respective parameter estimates).
- Tree structure
- Click this button to display the Tree Structure spreadsheet, which contains the summary information of all splits and the terminal nodes for the final tree. Regardless of the type of analysis problem (regression or classification analysis), the information available in the tree structure will include for each node,
- The node IDs of child nodes to which cases or objects are sent, depending on which split condition is satisfied.
- The number of cases or objects belonging to the node.
- For non-terminal tree nodes, the predictor variable chosen for the split.
If you selected a categorical response variable (classification), then, in addition to the information described above the tree structure will include the number of cases or objects in each observed class that are sent to the node. Alternatively, in the case of a continuous response (regression) the tree structure will contain information about the mean and variance of the dependent variable for the cases or objects belonging to the node.
- Terminal nodes
- Click this button to display the spreadsheet containing summary information for the terminal nodes only.
For classification problems (categorical dependent variable), the spreadsheet shows the number of cases or objects in each observed class that are sent to the node; a Gain value is also reported. By default (with Profit equal to 1.0 for each dependent variable class), the gain value is simply the total number of observations (cases) in the respective node. If separate Profit values are specified for each dependent variable class, then the Gain value is computed as the total profit (number of cases times respective profit values).
For regression problems (continuous dependent variable), the spreadsheet shows the number of cases or objects in each observed class that are sent to the node, and the respective node mean and variance.
- Risk estimates
- Click this button to display a spreadsheet with risk estimates for the analysis sample, the test sample (if one was specified on the General CHAID Models Quick specs dialog box - Validation tab), and the v-fold cross-validation risk (if v-fold cross-validation was requested on the General CHAID Models Quick specs dialog box - Validation tab). For classification-type problems (see also GC&RT Overviews) with a categorical dependent variable and equal misclassification costs, risk is calculated as the proportion of cases incorrectly classified by the tree (in the respective type of sample); if unequal misclassification costs are specified, the risk is adjusted accordingly, i.e., expressed relative to the overall cost. For regression-type problems with a continuous dependent variable risk is calculated as the within-node variance. The standard error for the risk estimate is also reported.
- V-fold cross-validation & risk estimates
- Click this button to produce a spreadsheet with Risk estimates.
The following options enable the v-fold cross-validation process for computing the v-fold cross-validation error and risk for the final tree. Effectively, STATISTICA will draw v number of random subsamples, as equal in size as possible, from the learning sample, and compute the average risk over those samples.
- Seed for random number generator
- Specify a positive integer value that will be used as the seed for generating random numbers for producing the v-fold random subsamples from the learning sample.
- V-Fold cross-validation; v value
- Specify the number of cross-validation samples that will be generated from the learning sample to provide an estimate of the v-fold cross-validation risk in the Risk estimates results spreadsheet.