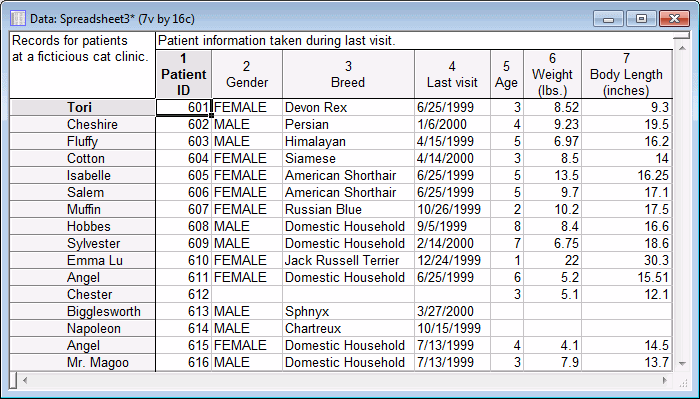
Merge Variables Example
Variable merging is useful when you have two different spreadsheets that have different variables, but the same observations (cases). Merging enables you to join the variables of one spreadsheet to the other so that you can centralize all of your observations to one table.
In this example, we have one spreadsheet that contains basic patient information at a cat clinic. We also have another spreadsheet with most of the same patients listed with their respective data entered from their most recent visits. We want to join both spreadsheets into a single data set.
- Ribbon bar. Select the Home tab. In the File group, click the Open arrow and select Open Examples to display the Open a Statistica Data File dialog box. The data files are located in the Datasets folder.
- Classic menus. From the File menu, select Open Examples to display the Open a Statistica Data File dialog box. The data files are located in the Datasets folder.
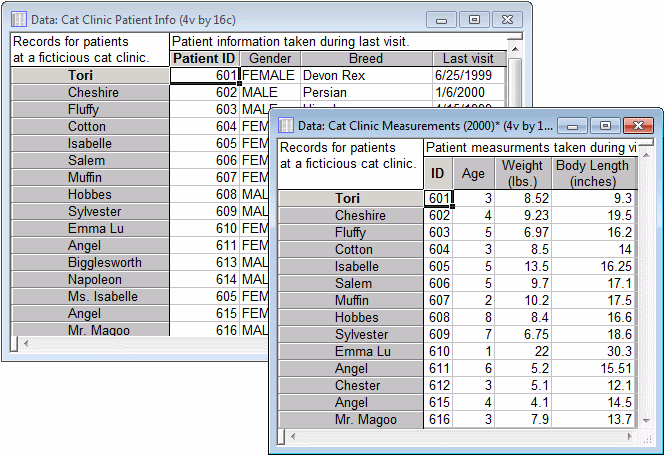
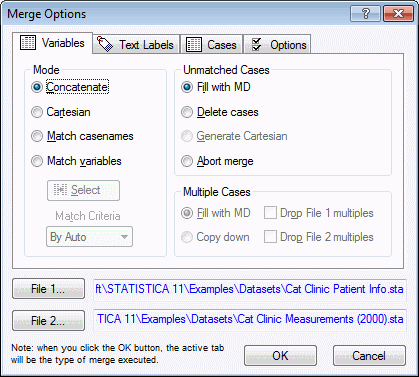
- Ribbon bar. Select the Data tab. In the Manage group, click Merge to display the Merge Options dialog box.
- Classic menus. From the Data menu, select Merge to display the Merge Options dialog box.
- Click the File 1 button, and in the Select Spreadsheet dialog box, select Cat Clinic Patient Info. Click the OK button.
- Then, click the File 2 button, and in the Select Spreadsheet dialog box, select Cat Clinic Measurements (2000). Click the OK button.
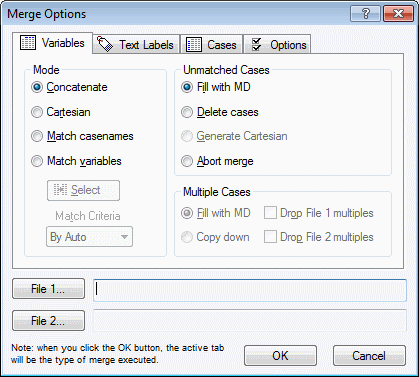
- The Merge Options dialog box should look like this:
The next step is to decide which mode we should use.
Because the ordering of cases does not appear to be precisely the same between the two spreadsheets, we need to either Match casenames or Match variables. We know that the variables (columns) Patient ID in Cat Clinic Patient Info.sta and ID in Cat Clinic Measurements (2000).sta are unique identifiers for each patient. Additionally, we can see that there are actually two different patients named Angel in both of the spreadsheets, so Matching casenames will not be a suitable choice.
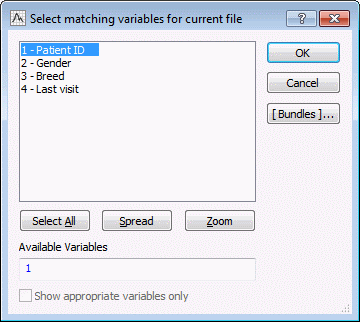
- We should select the Match variables option button. Then, the Select button will be enabled. Click the Select button to display the Select matching variables for current file dialog box. Select our unique variable identifier for Cat Clinic Patient Info, which is Patient ID.
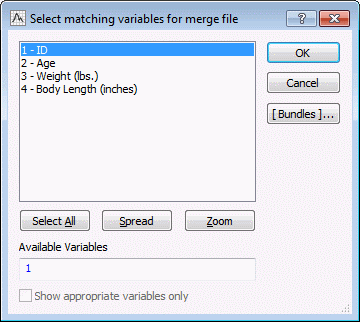
- Click OK, the Select matching variables for merge file dialog box is displayed. Select the unique variable identifier for Cat Clinic Measurements (2000), which is ID,
- Click OK to close this dialog box and return to the Merge Options dialog box.
- The next options of interest are the Drop File 1 multiples and Drop File 2 multiples.
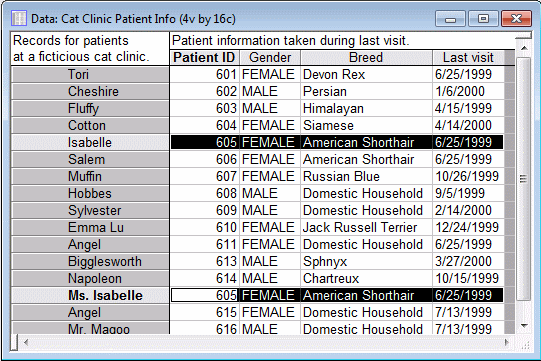
- After examining our spreadsheets, we notice in Cat Clinic Patient Info the same cat, 605, was entered twice (with slightly different names) by accident:
Along with duplicate cases, there is also the possibility of unmatched cases. This is to say, there may be cases that appear in one spreadsheet but not the other. In this case, we want to simply fill the extra variables for these unmatched cased with missing data (this will be explained further below); leave the option button Fill with MD set as the default.
- We want to avoid having any duplicate records from either spreadsheet being brought into our new spreadsheet, so we will select both of the check boxes Drop File 1 multiples and Drop File 2 multiples.
- Click the OK button; the following illustration shows the output:
- The first detail to notice is that the duplicate case Ms. Isabelle from the merge file was dropped. Remember that the File 1 spreadsheet contained two cases with the ID value 605, and we selected the option Drop merge multiples to ignore any duplicate cases such as this.
The next detail of interest is that the values for Gender, Breed, and Last visit are empty for the observation Chester. This is because Chester's ID value, 612, only appeared in File 2. Statistica was not able to match a case in File 1 with the value 612, so Chester's case data was simply inserted into the output; the variables from the current file that did not pertain to Chester are set to missing data because the Fill with MD option button in the Unmatched cases group box was selected.
The final note of interest is that the values for Age, Weight (lbs.), and Body Length (inches) are empty for the observations (cases) Bigglesworth and Napoleon. This is because their ID values, 613 and 614, only appeared in File 1. Statistica was not able to match a case in the merge file with either of these values, so Bigglesworth and Napoleon's case data were simply inserted into the output; the variables from the merge file that did not pertain to either Bigglesworth or Napoleon are set to missing data because the Fill with MD option button in the Unmatched cases group box was selected.
- We have successfully merged the variables from our measurements spreadsheet and our patient information spreadsheet into a new, unified data set.