Options Tab
The Options tab of Data Miner Recipes is used to set global options for recipes. Since most of these options are applied to the Data preparation step, they must be set prior to starting work on a new recipe. The Save defaults button must be clicked to apply modifications to the values on this tab.
Data Miner Recipes automatically samples data for analyses on large data sets. Sampling is used when the file size is large or the number of variables times the number of cases is large. This tab contains options that define a large data set.
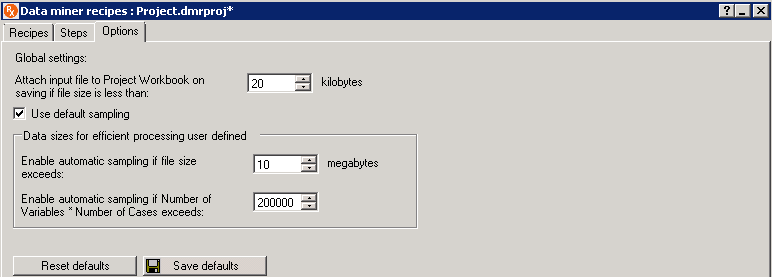
| Element Name | Description |
|---|---|
| Global Settings | |
| Attach input file to Project Workbook on saving if file size is less than | Includes the data file used in the
Data preparation
step in the Report on saving the project.
The data files that are 20 kilobytes or smaller are included, by default. The maximum file size that is included is 10,000 kilobytes. The input file is attached to the Project Workbook on save, but is not embedded into the Project Workbook. To review the input file after opening the project, select View data file from the Report button drop-down list (on the Steps tab). |
| Use default sampling | Clear this check box if you want to define different values for sampling.
The large data sources are sampled when the file size is greater than 10 megabytes or the number of variables times the number of cases is greater than 200,000, by default. |
| Data size for efficient processing user defined | |
| Enable automatic sampling if file size exceeds | Impacts the recipe when the
Use default sampling
check box is cleared.
When you want to change the definition of a large data set for automatic sampling, enter the value here. It is set to 10 megabytes, by default. A large data set can be defined as 1 to 500 megabytes. |
| Enable automatic sampling if Number of Variables * Number of Cases exceeds | Impacts the recipe when the
Use default sampling check box is cleared.
When you want to change the definition of a large data set for automatic sampling, enter the value here. It is set to 200,000, by default. A large data set can be defined as 10,000 to 2,147,483,647. |
| Generate C/C++ code for models | Creates C or C++ code for the models that are generated on the Model building step. The code is viewed in the Deployment step. |
| Reset defaults |
Resets the values to their original settings. |
| Save defaults |
Retains the settings for future recipes. |