Data Preparation Tab
For Data preparation step, you can use the options on the Data preparation tab to open or connect a data file for the analysis from a local machine or from a URL server. You can also use this section to apply data transformations, identify and review specific variables for the analysis, select a labeling variable for identifying specific case names to be used in the analysis, remove duplicate cases from the data and specify the use of a sample data set.
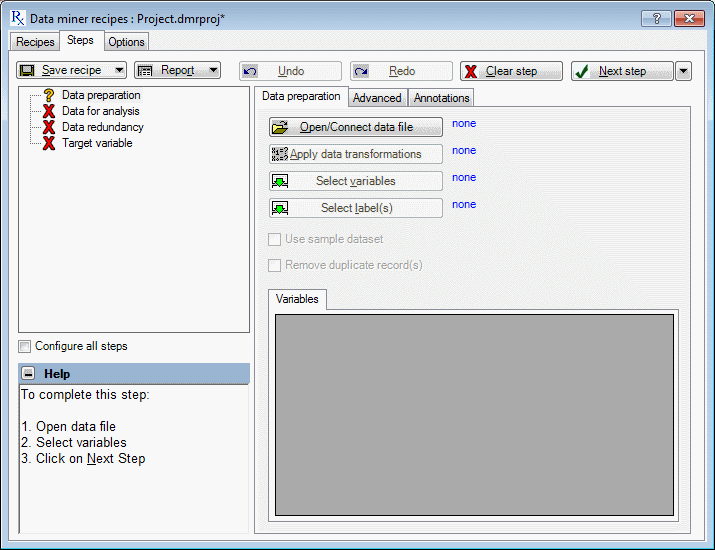
| Element Name | Description |
|---|---|
| Open/Connect data file | Displays the
Select Data Source
dialog box and select the data file for the analysis.
Data Miner Recipes data files are saved in the standard Statistica format with extension *.sta. |
| Apply data transformations | Displays the
Batch Transformation Formulas
dialog box, which contains options to supplement the data transformation formulas built into the Statistica spreadsheet.
You can enter several transformation formulas into a text editor and evaluate these transformations in sequence, one by one. Any transformation you choose is also be applied to new data during deployment. |
| Select variables | Displays a
five-list variable selection dialog box, which is used to choose variables for the analysis.
You can select continuous and categorical targets, continuous and categorical predictors, and a validation sample variable. |
| Select labels(s) | Displays a
single list variable selection
dialog box, which is used to identify one or more labeling variables for identifying specific cases from the data set for use in the analysis.
Note that case labels (ID) must be unique. If the selected variable does contain duplicate labels (for example two or more cases with the same label (ID) or the case names contain duplicate labels, the Next step fails and you are prompted to review the data set for duplicate names before continuing to the next step. |
| Use sample dataset | You can select this check box to extract a random sample from the original data set and use that sample as the data for the analysis.
By default, this check box is selected for large data files and cleared for smaller data sets. The default selection is to use Systematic random sampling with K =1. Additional sampling methods are specified on the Advanced tab. |
| Remove duplicate record(s) | You can select this check box to remove duplicate records from the data set.
Options for defining duplicate records are available on the Advanced tab. |
| Variables | Displays the variable's type (continuous or categorical) and role (input, output and validation sample).
Changes to a variable's type or role are made by clicking the Select variables button. |