Overview: Batch Processing Using Workflows and Statistica Enterprise Server
Batch processing makes it possible for you to specify a batch run to Statistica Enterprise Server to score data using preconfigured workflows. The system is designed so that a particular batch run can be broken into partitions and executed on Statistica Enterprise Server in parallel.
The batch system is designed to execute preconfigured workflows that have been saved to Statistica Enterprise. It is expected that these workflows will be defined as follows:
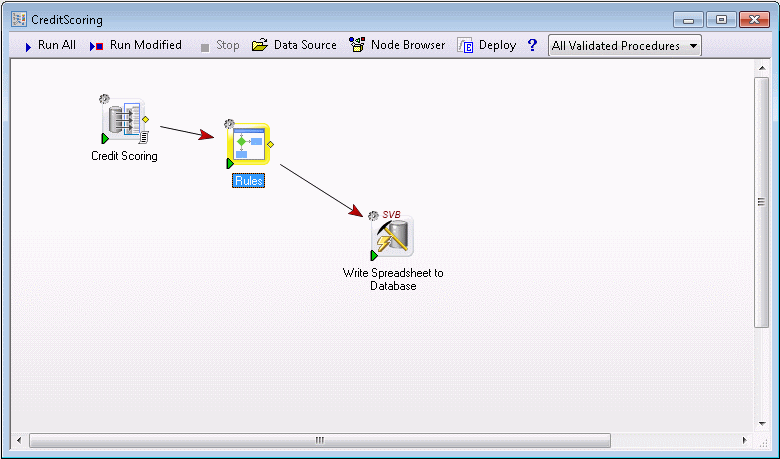
The data source is an Enterprise Data Configuration; a query will be executed to get the data to process. That query can be parameterized by user-defined parameters from the command line (this is described in more detail below). The Workflow then executes a Rules node, which defines all the business logic of the rules, including models that have been deployed to Statistica Enterprise. The Rules node is configured to output only a downstream spreadsheet, which is then fed into a Write Spreadsheet to Database node. This node will take an Enterprise Database Connection, and write the Rules results spreadsheet back the specified table in this database. (Note that Access, MySQL, Oracle, PostgreSQL, SQL Server, SQL Server PDW, and Teradata databases are supported.) The system will detect errors at various points, and report them back to the batch system.
The batch execution system consists of two script files, Batch.vbs and Batch.svb.
Batch.vbs
This is a windows scripting host file and is placed on the client machine that will be initiating the batch jobs. This can be modified as desired to affect how the batch job is invoked, and the format of the error information returned. The script references two Statistica client components, which need to be installed on the client machine: WSClientLibrary (for communication to Statistica Enterprise), and Dictionary (for handing of name/value pairs used as parameters). These two components are part of a standard Statistica client install, so the easiest way to get them on the client machine executing the batch job is to perform a Statistica client install.
The purpose of the Batch.vbs file is to take the command line parameters passed to it and submit a batch job to Statistica Enterprise Server, passing on the command line parameters to that environment. These command line parameters control which Statistica Enterprise Server to send the requests to and which Workflow (with optional revision number) to execute, and also pass parameters to the workflow, such as RunID and PartitionID. These parameters can be used by the Data Configuration node for filtering on the database or in the Rules node for use in including in rules. The script file will write status and errors to stdout, and will return a result code of 0 for successful indication and non-zero for error.
cscript //NoLogo Batch.vbs /WFID:/Paul/CreditScoring.sdm
/PartitionID:12 /RunID:Run1 /RunType:simulation
In this command line example, //NoLogo suppresses the scripting host logo when run, Batch.vbs is the provided batch scripting file, and the rest are parameters to the batch run. Parameters are specified in the form /parmname:parmvalue.
There are two required parameters:
| /ENTSERVER:servername | the name of the Statistica Enterprise Server |
| /WFID:workflow-path | the Enterprise path name of the workflow to execute |
Optionally, you can also specify:
| /WFVER:workflow-version | Latest, LatestApproved, or specific revision number of the workflow specified in WFID parameter. If this parameter is not specified, Latest is assumed |
In the cscript command line example above, the workflow to be executed, CreditScoring.sdm, is found in the Paul folder. Aside from these three predefined parameters (ENTSERVER, WFID, WFVER), the other parameters are user defined. The system will use these user-defined parameters in two places in the workflow: Data Configuration node and Rules node.
Command Line Parameters in Data Configuration Node
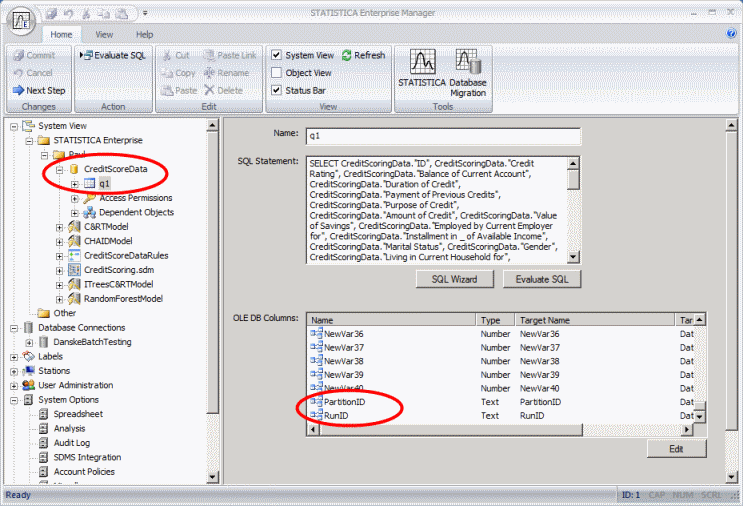
In the Data Configuration node, the fields defined in the query are matched up against the command-line parameters. If any of the fields have been referenced in the command line parameter, the field can be filtered by the corresponding value. For the example above, the query has two fields that are referenced in the command line: PartitionID and RunID. The example Workflow above references the Data Configuration CreditScoreData, which defines a query against the database. The table being queried includes two fields, PartitionID and RunID:
The batch scripts will let you take any fields defined in the query, and let you supply values for them at run time. For simple filtering, where you specify a single value for the query field, you can use the following syntax on the command line:
/fieldname:value
Where fieldname is the name of the database field, and value is the value to filter for.
For example, if the database stored RunID as string Run1, you could say:
/RunID:Run1
If the parameter value has embedded blanks, you should include it in quotes:
/RunID:"Run 1"
This will automatically be translated into SQL as WHERE RUNID='Run 1' when the query is executed. In the case of ambiguous reference (such as multiple queries in the data configuration that have the same name), you can specify the fully qualified query field in the form QueryName.ColumnName; for example:
/Q1.RunID:Run1
The system also supports more complicated filtering statements by adding additional command line parameters in the form fieldname.Operator and specifying an Enterprise operator filtering string from the selection below:
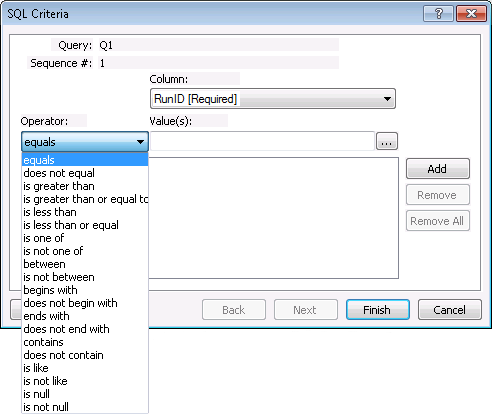
For example, if you wanted to include three RunIDs - Run1, Run2, and Run3 - you could specify the following:
/RunID:(Run1,Run2,Run3)
/RunID.Operator:"is one of"
Multiple fields specified on the command line are joined with AND on the WHERE clause, meaning all filtering conditions have to be True to return the data row.
Command Line Parameters in Rules Node
All command line parameters are available to Rules nodes via the spreadsheet Dictionary() formula. For example, if you specify the following command-line parameter:
/RunType:simulation
You can access this parameter in formula by Dictionary("RunType"). If you want to output the value of the command line parameter to a rules results spreadsheet in a field named Type, you could use the following formula Rule step:
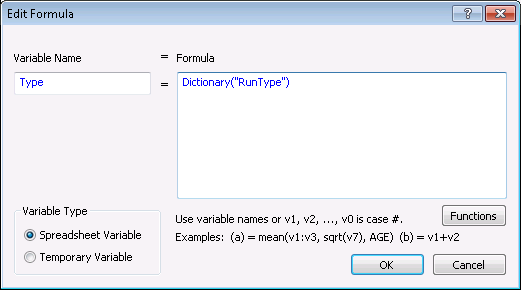
Assuming the batch run was started with command-line /RunType:simulation, the result is a new column in the results spreadsheet named of Type, and it will have value simulation in all the cases.
The Dictionary() formula can be used in conditional statements as well, enabling you to parameterize rules execution at runtime with command-line parameters.
Batch.svb
c:\WebSTATISTICAPub\RepositoryRoot\system\Scripts\
This is the script that is executed by the client-side Batch.vbs file. The script receives all the command-line parameters, opens the specified workspace, sets up the workspace environment with the global dictionary containing the command-line parameters, and executes the workspace. The workspace will look for global command-line parameters, and interpret them in the Data Configuration and Rules nodes as described above.
It is not expected that you will make any changes to this script, but it does provide a way to modify how the command-line batch execution is run.