Statistica H2O Nodes
Sparkling Water is not shipped with Statistica and needs to be deployed, configured and started before Statistica H2O workspace nodes can be used.
H2O is an open source, in-memory, distributed, fast, and scalable machine learning and predictive analytics platform that allows the user to build machine learning models on big data. Sparkling Water allows users to combine the fast, scalable machine learning algorithms of H2O with the capabilities of Spark.
Statistica users may want to connect to H2O / Sparkling Water for two main reasons:
- To use traditional algorithms and analyses in a distributed, scalable, in-memory environment for performance gains and practical feasibility of certain modeling designs, typically, involving large number of rows or columns in a dataset, which exceeds capabilities of a single host.
- To have access to machine learning algorithms that are currently unavailable in Statistica .
H2O integration in Statistica can work with both H2O and Sparkling Water instances, deployed to clusters as well as single hosts. However, neither H2O nor Sparkling Water are shipped with Statistica and need to be deployed, configured and started before Statistica H2O workspace nodes can be used.
Please refer to the downloads page of H2O.ai website for installation instructions (https://www.h2o.ai/download/). We recommend using Sparkling Water 2.1 which runs with Spark 2.1.
Statistica nodes utilize H2O’s REST API, so H2O server needs to be accessible over the network. Typically, the H2O server IP address and port are presented to the user once H2O is started. This information is needed for the H2O nodes (H2O Data) to connect to the H2O environment.
MISC
In this node you provide the H2O server IP address and port (mentioned in the previous section), and the path to the data source to be imported into H2O.
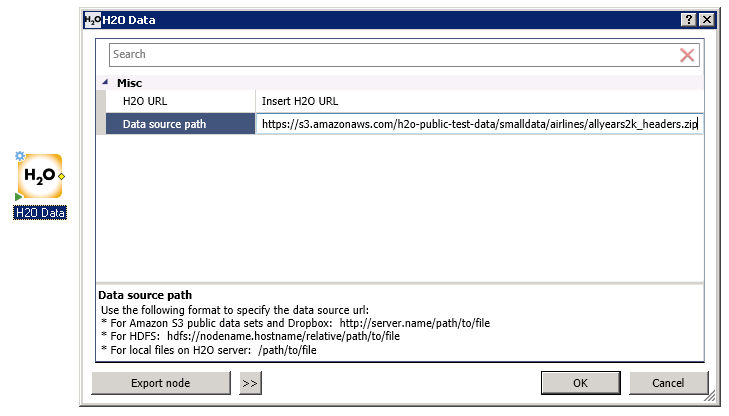
After running the node, it generates two outputs:
- A H2O Inferred Variable Types report, which lists all variable names for the given data set and the data types inferred by H2O.
- A spreadsheet that shows a sample of the dataset with the first few rows and inferred types.
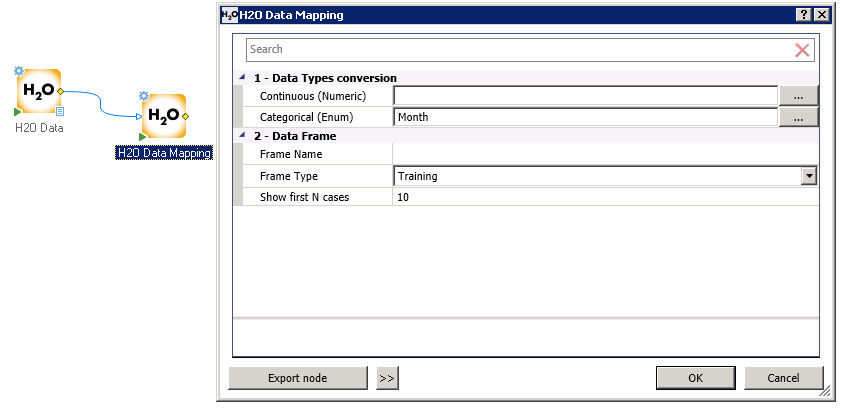
1. Data Type Conversion
In this section, select which variables to use as Categorical or Continuous during the analysis.
If you do not select variables, the node will use the data types reported in the H2O Inferred Variable Types report of the H2O Data Node.
Frame Type
In this field, select the name for the Frame Type (whether the data set will be used as Training or Validation data during the analysis)
Show first N cases
In this field, enter the number of cases to be displayed once the Frame is created.
H2O Data_Legacy Node [DEPRECATED]
You can still import Data into H2O with the H2O Data_Legacy node. However, be aware that this node always uses the Inferred data types and does not allow you to change the Variable data types. This node is deprecated and will not be available in future releases. You can import it by using the Node Browser. It is located in the DataMiner folder.
H2O Gradient Boosting Machine (GBM)
A GBM is an ensemble of either regression or classification tree models. Both are forward-learning ensemble methods that obtain predictive results using gradually improved estimations.
The H2O Gradient Boosting Machine(GBM) Node:
- Attachments:
Required: One upstream node (H2O Data Mapping Node) with training data
Optional: A second upstream node (H2O Data Mapping Node) with validation data
It exposes H2O GBM model parameters organized in three sections:
Parameters
Advanced
Expert
In section four (Reports) select what outputs to generate. The output for the H2O Gradient Boosting Machine(GBM) Node includes the following reports:
Model parameters
Output (model category, validation metrics)
Model summary (number of trees, min. depth, max. depth, mean depth, min. leaves, max. leaves, mean leaves)
Scoring history in tabular format
Training metrics (model name, model checksum name, frame name, description, model category, duration in ms, scoring time, predictions, MSE, R2)
Variable importances in tabular format

H2O Generalized Linear Modeling (GLM)
Generalized Linear Models (GLMs) are an extension of traditional linear models. GLMs estimate regression models for outcomes following exponential distributions. They have gained popularity in statistical data analysis due to the following:
The flexibility of the model structure unifying the typical regression methods (such as linear regression and logistic regression for binary classification)
The recent availability of model-fitting software
The ability to scale well with large datasets
The GLM suite includes these analyses:
Gaussian regression
Poisson regression
Binomial regression (classification)
Multinomial classification
Gamma regression
The H2O Generalized Linear Modeling (GLM) Node:
- Attachments:
Required: One upstream node (H2O Data Mapping Node) with training data
Optional: A second upstream node (H2O Data Mapping Node) with validation data
It exposes H2O GBM model parameters organized in three sections:
Parameters
Advanced
Expert
Reports, are where you can select what outputs to generate. The output for the H2O Gradient Boosting Machine(GBM) Node includes the following reports:
Model parameters
Output (model category, validation metrics, and standardized coefficients magnitude)
GLM model summary (family, link, regularization, number of total predictors, number of active predictors, number of iterations, training frame)
Scoring history in tabular form (timestamp, duration, iteration, log likelihood, objective)
Training metrics (model, model checksum, frame, frame checksum, description, model category, scoring time, predictions, MSE, r2, residual deviance, null deviance, AIC, null degrees of freedom, residual degrees of freedom)
Coefficients
Standardized coefficient magnitudes (if standardization is enabled

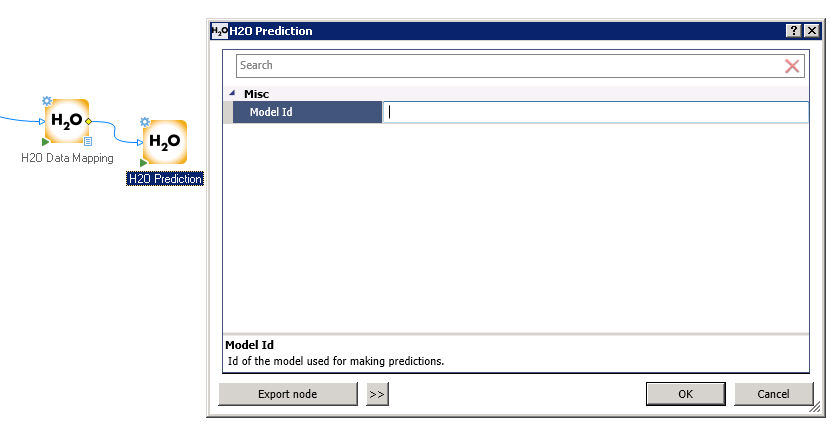
H2O Prediction Node
In the H2O Prediction Node, you can make predictions on new data sets using the trained models that are created when running H2O GBM or GLM nodes.
The H2O Prediction Node requires an upstream H2O Data Mapping Node that points to the new data set to be scored.
Additionally either the model id should be provided or an upstream H2O (GBM or GLM) model node must be attached.
Additional Data Science H2O Algorithms:
The following additional data science algorithms are also provided:
- H20 DeepLearning
- H20 DRF (Distributed Random Forest)
- H20 PCA (Principal Competent Analysis)
- H20 K-Means
Such nodes can be imported by using the Node Browser and navigation to the Statistica/Examples/Nodes folder.
- Example_H20_DeepLearning_MNIST_Digit_Regcognition
- Example_H20_DeepLearning_GLM_Lasso_AirlinesDeplay
- Example_H20_DRF_DisctributedRandomForest
- Example_H20_PCA_PrincipalComponestAnalysis
- Example_H20_K-Means
You can find Example workspaces under the Examples folder (File>Open Examples>Workspaces)
Additional H2O Information
http://h2o-release.s3.amazonaws.com/h2o/rel-ueno/5/docs-website/h2o-docs/booklets/GBMBooklet.pdf
http://h2o-release.s3.amazonaws.com/h2o/rel-ueno/5/docs-website/h2o-docs/booklets/GLMBooklet.pdf
http://h2o-release.s3.amazonaws.com/h2o/rel-ueno/5/docs-website/h2o-docs/booklets/PythonBooklet.pdf