Open Document Files
Click the Browse documents button on the Text mining dialog box Quick tab or Advanced tab to display the Select documents dialog box. Use the options in this dialog box to select the document files to be analyzed (indexed). The basic algorithm implemented in Statistica Text Mining and Document Retrieval supports various input file formats, including MS Word® documents, rich text files (RTF), PDF, htm and html (downloaded web pages or URL addresses), XML, and text.
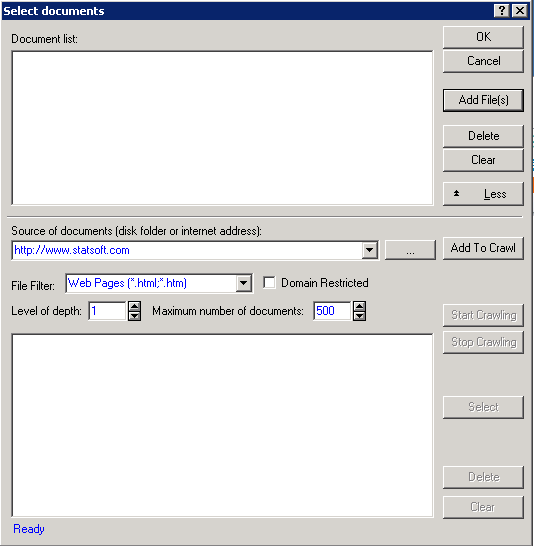
Click the Add file button to browse to the files to be included. Click the More button to display more options; you can select lists of files or URL (Web) addresses via wildcards or by crawling the web from a particular domain name or parent address.
| Option | Description |
|---|---|
| Document list | The selected files or web (URL) addresses will be listed in the Document list box. You can delete an item from this list by clicking it and then clicking the Delete button or pressing the Delete key on your keyboard. |
| OK | Click this button to select the files or URL addresses displayed in the Document list and to close the dialog box. |
| Cancel | Click this button to close this dialog box without selecting any files or URL addresses. |
| Add file | Click this button to display the standard file browser dialog box to select a list of document files; after closing that dialog box, the selected files will be transferred into the Document list box. |
| Delete | Click this button or press the Delete key on your keyboard to remove the documents currently selected (highlighted) in the Document list. |
| More/Less | Click this button to expand the Open document files dialog box and expose the crawler options and interface. The More button becomes a Less button, and you can use the additional options to select the document files to be analyzed (indexed) by crawling either a file directory structure on the hard disk or other storage device, or by crawling web pages (URL addresses) starting at particular starting pages. Click the Less button (previously the More button) to close the lower portion of the dialog box and return to the reduced set of options described above. |
The basic algorithm implemented in Statistica Text Mining and Document Retrieval supports various input file formats, including MS Word® documents, rich text files (RTF), PDF, htm and html (downloaded web pages or URL addresses), XML, and text.
Note: Overview of Web- or file-crawling options. Use the options in the lower portion of the Open document files dialog box to select a list of root directories or web addresses, and to automatically retrieve all documents found there or further down the hierarchy of files or web addresses. For example, if you specify a subdirectory c:\MyDocuments and click the Start crawling button, all files of the type specified in the File filter field that are found in this directory will automatically be retrieved and displayed in the box in the expanded portion of the dialog box. Further, if the Level of depth is set to a value greater than 1, the program will also look for documents (of the requested type, consistent with the File filter) in the subdirectories inside c:/MyDocuments, down to the Level of depth of this directory structure as requested.
Web-crawling works in very much the same way. The program connects to the Destination web pages selected (into the box in the expanded portion of the dialog box), and when you click the Start crawling button, the program will retrieve all web pages referenced in that starting web page. Put another way, the program will click every link found in the initial web page to retrieve all pages "below" it, down to the level specified in the Level of depth field.
Selecting files or URLs into the Document list: After the crawling operation has been completed, you can select files in the box in the expanded portion of the dialog box, using the standard Windows conventions (click on a file or URL to highlight/select it; to select more than one item hold down the Ctrl key and click on the items to add; to select a range of items, hold down the Shift key and click the first and last items in the range of items to select). Then click the Select button to transfer the selected files or web URLs to the Document list.
Retrieving very large collections of documents:If your work requires the retrieval of or crawling to a very large number of documents, you should select the Data Mining tab. In the Text Mining group, click Web Crawling to create an input spreadsheet with the links to the specific documents. The options available via this user interface are more flexible for automatically retrieving large numbers of documents, and for producing an input spreadsheet with a text variable containing the links. You can then use the options in the Text Mining dialog box (on the Quick or Advanced tab) to specify the (text) variable containing the references to the input documents, and in that manner process practically unlimited numbers of documents in a single analysis (since Statistica input spreadsheets are not limited to a maximum size).
 button to display a standard Windows file browser to browse to the file directory to transfer to the Destination field
button to display a standard Windows file browser to browse to the file directory to transfer to the Destination field